Apache Flume Tutorial – Flume Introduction, Features & Architecture
The article provides you the complete Apache Flume Tutorial. It explains Apache Flume used for transferring data from web servers to HDFS or HBase. Let’s start!!!
What is Apache Flume?
Apache Flume is an open-source tool for collecting, aggregating, and moving huge amounts of streaming data from the external web servers to the central store, say HDFS, HBase, etc. It is a highly available and reliable service which has tunable recovery mechanisms.
The main purpose of designing Apache Flume is to move streaming data generated by various applications to Hadoop Distributed FileSystem.
Why Apache Flume?
A company has millions of services that are running on multiple servers. Thus, produce lots of logs. In order to gain insights and understand customer behavior, they need to analyze these logs altogether.
In order to process logs, a company requires an extensible, scalable, and reliable distributed data collection service.
That service must be capable of performing the flow of unstructured data such as logs from source to the system where they will be processed (such as in Hadoop Distributed FileSystem). Flume is an open-source distributed data collection service used for transferring the data from source to destination.
It is a reliable, and highly available service for collecting, aggregating, and transferring huge amounts of logs into HDFS. It has a simple and flexible architecture.
Apache Flume is highly robust and fault-tolerant and has tunable reliability mechanisms for fail-over and recovery. It allows the collection of data collection in batch as well as in streaming mode.
Features of Apache Flume
- Apache Flume is a robust, fault-tolerant, and highly available service.
- It is a distributed system with tunable reliability mechanisms for fail-over and recovery.
- Apache Flume is horizontally scalable.
- Apache Flume supports complex data flows such as multi-hop flows, fan-in flows, fan-out flows. Contextual routing etc.
- It provides support for large sets of sources, channels, and sinks.
- Apache Flume can efficiently ingest log data from various servers into a centralized repository.
- With Flume, we can collect data from different web servers in real-time as well as in batch mode.
- We can import large volumes of data generated by social networking sites and e-commerce sites into Hadoop DFS using Apache Flume.
Apache Flume Architecture
Apache Flume has a simple and flexible architecture. The below diagram depicts Flume architecture.
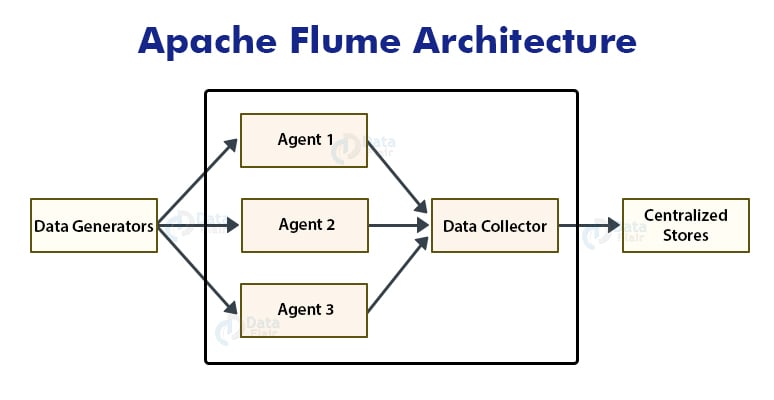
As shown in the above figure, data generators generate huge volumes of data that are collected by individual agents called Flume agents which are running on them. The data generators are Facebook, Twitter, e-commerce sites, or various other external sources.
A data collector collects data from the agents, aggregates them, and pushes them into a centralized repository such as HBase or HDFS.
Flume Event
A Flume event is a basic unit of data that needs to be transferred from source to destination.
Flume Agent
Flume agent is an independent JVM process (JVM) in Apache Flume. Agent receives events from clients or other Flume agents and passes it to its next destination which can be sink or other agents.
Flume Agent contains three main components. They are the source, channel, and sink.

Source
A source receives data from the data generators. It transfers the received data to one or more channels in the form of events.
Flume provides support for several types of sources.
Example − Exec source, Thrift source, Avro source, twitter 1% source, etc.
Channel
A channel receives the data or events from the flume source and buffers them till the sinks consume them. It is a transient store.
Flume supports different types of channels.
Example − Memory channel, File system channel, JDBC channel, etc.
Sink
A sink consumes data from the channel and stores them into the destination. The destination can be a centralized store or other flume agents.
Example − HDFS sink.
Additional Components of Flume Agent
There are few more components other than described above that play a significant role in transferring the events.
Interceptors
They alter or inspect flume events transferred between the flume source and channel.
Channel Selectors
They determine which channel is to be chosen for transferring the data when multiple channels exist. Channel selectors are of two types- Default and multiplexing.
Sink Processors
Sink Processors invoke a particular sink from the group of sinks.
Apache Flume – Data Flow
A flume is a tool used for moving log data into HDFS. Apache Flume supports complex data flow. There are three types of data flow in Apache Flume. They are:
1. Multi-hop Flow
Within Apache Flume, there can be multiple agents. So before reaching the final destination, the flume event may travel through more than one flume agent. This is called a multi-hop flow.
2. Fan-out Flow
The dataflow from one flume source to multiple channels is called fan-out flow. Fan-out flow is of two types − replicating and multiplexing.
3. Fan-in Flow
The fan-in flow is the data flow where data is transferred from many sources to one channel.
Flume Advantages
1. Apache Flume enables us to store streaming data into any of the centralized repositories (such as HBase, HDFS).
2. Flume provides steady data flow between producer and consumer during reading2/write operations.
3. Flume supports the feature of contextual routing.
4. Apache Flume guarantees reliable message delivery.
5. Flume is reliable, scalable, extensible, fault-tolerant, manageable, and customizable.
Flume disadvantages
1. Apache Flume offers weaker ordering guarantees.
2. Apache Flume does not guarantee that the messages reaching are 100% unique.
3. It has complex topology and reconfiguration is challenging.
4. Apache Flume may suffer from scalability and reliability issues.
Apache Flume Applications
1. Apache Flume is used by e-commerce companies to analyze customer behavior from a particular region.
2. We can use Apache Flume to move huge amounts of data generated by application servers into the Hadoop Distributed File System at a higher speed.
3. Apache Flume is used for fraud detections.
4. We can use Apache Flume in IoT applications.
5. Apache Flume can be used for aggregating machine and sensor-generated data.
6. We can use Apache Flume in the alerting or SIEM.
7. Flume specializes in collecting and aggregating log data from various sources and sending it to centralized storage like HDFS.
8. Apache Flume can easily integrate with different data streaming tools like Apache Spark.
Summary
In short, Apache Flume is an open-source tool for collecting, aggregating, and moving huge amounts of data from the external web servers to the central store. Apache Flume is a highly available and reliable service. Apache Flume can be used for ingesting data from various applications to HDFS.
It is useful for various e-commerce sites for understanding customer behavior. The Apache Flume Tutorial had explained the Flume architecture, data flow. It had also enlisted flume features, advantages, and disadvantages.
Hope you liked the Apache Flume Tutorial by DataFlair. Do share your feedback in the comment section.
If you are Happy with DataFlair, do not forget to make us happy with your positive feedback on Google





Flume is a unique component which is very efficient and reliable. nice info..
while collection can we process the data as well in flume in real-time ?
nice tutorial, i tried kinesis before flume, but flume is more feature rich.
What is the meaning of contextual routing with respect of Flume?
contextual routing means we can specify the route of events to any particular source.
how does the data get into the spooling directory in the local file system that we have set for transferring data into hdfs?
Nice explanation !