Hadoop HDFS Architecture Explanation and Assumptions
This HDFS tutorial by DataFlair is designed to be an all in one package to answer all your questions about HDFS architecture.
Hadoop Distributed File System(HDFS) is the world’s most reliable storage system. It is best known for its fault tolerance and high availability.
In this article about HDFS Architecture Guide, you can read all about Hadoop HDFS.
First of all, we will discuss what is HDFS next with the Assumptions and Goals of HDFS design. This HDFS architecture tutorial will also cover the detailed architecture of Hadoop HDFS including NameNode, DataNode in HDFS, Secondary node, checkpoint node, Backup Node in HDFS.
HDFS features like Rack awareness, high Availability, Data Blocks, Replication Management, HDFS data read and write operations are also discussed in this HDFS tutorial.
What is Hadoop HDFS?
HDFS stores very large files running on a cluster of commodity hardware. It works on the principle of storage of less number of large files rather than the huge number of small files. HDFS stores data reliably even in the case of hardware failure. It provides high throughput by providing the data access in parallel.
HDFS Assumption and Goals
I. Hardware failure
Hardware failure is no more exception; it has become a regular term. HDFS instance consists of hundreds or thousands of server machines, each of which is storing part of the file system’s data. There exist a huge number of components that are very susceptible to hardware failure. This means that there are some components that are always non-functional. So the core architectural goal of HDFS is quick and automatic fault detection/recovery.
II. Streaming data access
HDFS applications need streaming access to their datasets. Hadoop HDFS is mainly designed for batch processing rather than interactive use by users. The force is on high throughput of data access rather than low latency of data access. It focuses on how to retrieve data at the fastest possible speed while analyzing logs.
III. Large datasets
HDFS works with large data sets. In standard practices, a file in HDFS is of size ranging from gigabytes to petabytes. The architecture of HDFS should be design in such a way that it should be best for storing and retrieving huge amounts of data. HDFS should provide high aggregate data bandwidth and should be able to scale up to hundreds of nodes on a single cluster. Also, it should be good enough to deal with tons of millions of files on a single instance.
IV. Simple coherency model
It works on a theory of write-once-read-many access model for files. Once the file is created, written, and closed, it should not be changed. This resolves the data coherency issues and enables high throughput of data access. A MapReduce-based application or web crawler application perfectly fits in this model. As per apache notes, there is a plan to support appending writes to files in the future.
V. Moving computation is cheaper than moving data
If an application does the computation near the data it operates on, it is much more efficient than done far of. This fact becomes stronger while dealing with large data set. The main advantage of this is that it increases the overall throughput of the system. It also minimizes network congestion. The assumption is that it is better to move computation closer to data instead of moving data to computation.
VI. Portability across heterogeneous hardware and software platforms
HDFS is designed with the portable property so that it should be portable from one platform to another. This enables the widespread adoption of HDFS. It is the best platform while dealing with a large set of data.
Introduction to HDFS Architecture
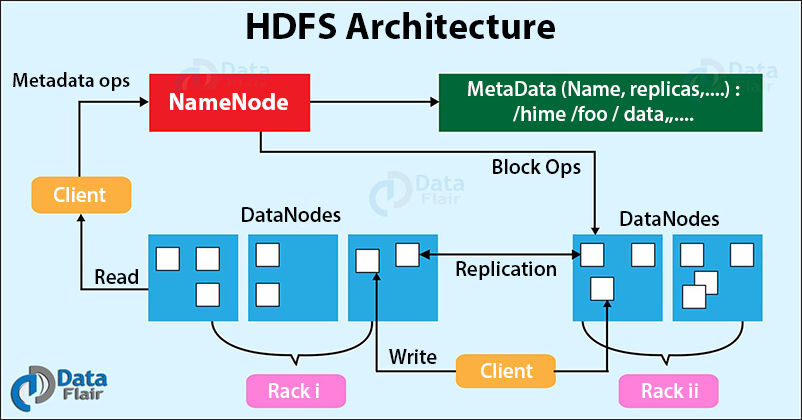
Hadoop Distributed File System follows the master-slave architecture. Each cluster comprises a single master node and multiple slave nodes. Internally the files get divided into one or more blocks, and each block is stored on different slave machines depending on the replication factor (which you will see later in this article).
The master node stores and manages the file system namespace, that is information about blocks of files like block locations, permissions, etc. The slave nodes store data blocks of files.
The Master node is the NameNode and DataNodes are the slave nodes.
Let’s discuss each of the nodes in the Hadoop HDFS Architecture in detail.
What is HDFS NameNode?
NameNode is the centerpiece of the Hadoop Distributed File System. It maintains and manages the file system namespace and provides the right access permission to the clients.
The NameNode stores information about blocks locations, permissions, etc. on the local disk in the form of two files:
- Fsimage: Fsimage stands for File System image. It contains the complete namespace of the Hadoop file system since the NameNode creation.
- Edit log: It contains all the recent changes performed to the file system namespace to the most recent Fsimage.
Functions of HDFS NameNode
- It executes the file system namespace operations like opening, renaming, and closing files and directories.
- NameNode manages and maintains the DataNodes.
- It determines the mapping of blocks of a file to DataNodes.
- NameNode records each change made to the file system namespace.
- It keeps the locations of each block of a file.
- NameNode takes care of the replication factor of all the blocks.
- NameNode receives heartbeat and block reports from all DataNodes that ensure DataNode is alive.
- If the DataNode fails, the NameNode chooses new DataNodes for new replicas.
Before Hadoop2, NameNode was the single point of failure. The High Availability Hadoop cluster architecture introduced in Hadoop 2, allows for two or more NameNodes running in the cluster in a hot standby configuration.
What is HDFS DataNode?
DataNodes are the slave nodes in Hadoop HDFS. DataNodes are inexpensive commodity hardware. They store blocks of a file.
Functions of DataNode
- DataNode is responsible for serving the client read/write requests.
- Based on the instruction from the NameNode, DataNodes performs block creation, replication, and deletion.
- DataNodes send a heartbeat to NameNode to report the health of HDFS.
- DataNodes also sends block reports to NameNode to report the list of blocks it contains.
What is Secondary NameNode?
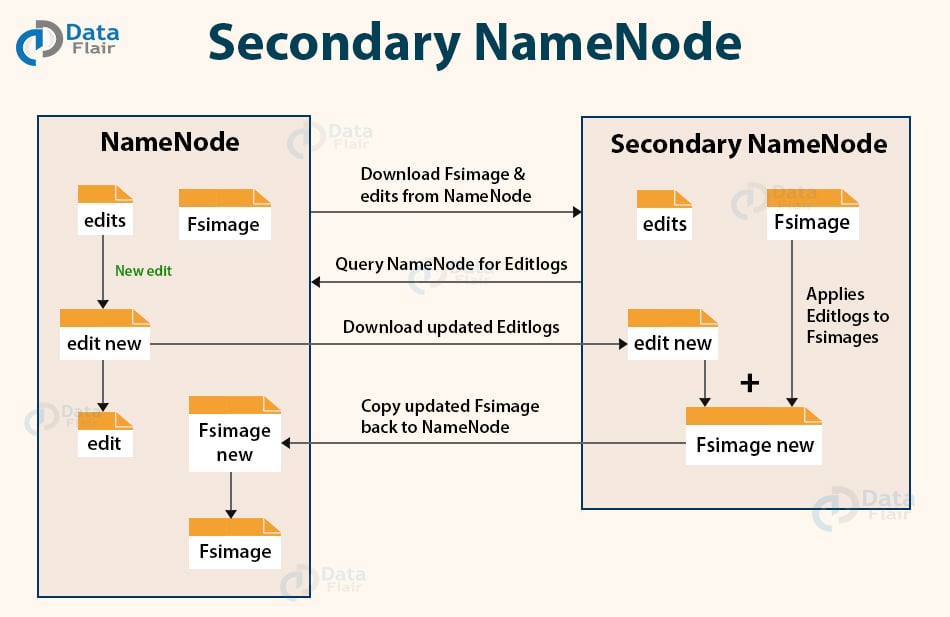
Apart from DataNode and NameNode, there is another daemon called the secondary NameNode. Secondary NameNode works as a helper node to primary NameNode but doesn’t replace primary NameNode.
When the NameNode starts, the NameNode merges the Fsimage and edit logs file to restore the current file system namespace. Since the NameNode runs continuously for a long time without any restart, the size of edit logs becomes too large. This will result in a long restart time for NameNode.
Secondary NameNode solves this issue.
Secondary NameNode downloads the Fsimage file and edit logs file from NameNode.
It periodically applies edit logs to Fsimage and refreshes the edit logs. The updated Fsimage is then sent to the NameNode so that NameNode doesn’t have to re-apply the edit log records during its restart. This keeps the edit log size small and reduces the NameNode restart time.
If the NameNode fails, the last save Fsimage on the secondary NameNode can be used to recover file system metadata. The secondary NameNode performs regular checkpoints in HDFS.
What is Checkpoint Node?
The Checkpoint node is a node that periodically creates checkpoints of the namespace.
Checkpoint Node in Hadoop first downloads Fsimage and edits from the Active Namenode. Then it merges them (Fsimage and edits) locally, and at last, it uploads the new image back to the active NameNode.
It stores the latest checkpoint in a directory that has the same structure as the Namenode’s directory. This permits the checkpointed image to be always available for reading by the NameNode if necessary.
What is Backup Node?
A Backup node provides the same checkpointing functionality as the Checkpoint node.
In Hadoop, Backup node keeps an in-memory, up-to-date copy of the file system namespace. It is always synchronized with the active NameNode state.
It is not required for the backup node in HDFS architecture to download Fsimage and edits files from the active NameNode to create a checkpoint. It already has an up-to-date state of the namespace state in memory.
The Backup node checkpoint process is more efficient as it only needs to save the namespace into the local Fsimage file and reset edits. NameNode supports one Backup node at a time.
This was about the different types of nodes in HDFS Architecture. Further in this HDFS Architecture tutorial, we will learn about the Blocks in HDFS, Replication Management, Rack awareness and read/write operations.
Let us now study the block in HDFS.
What are Blocks in HDFS Architecture?
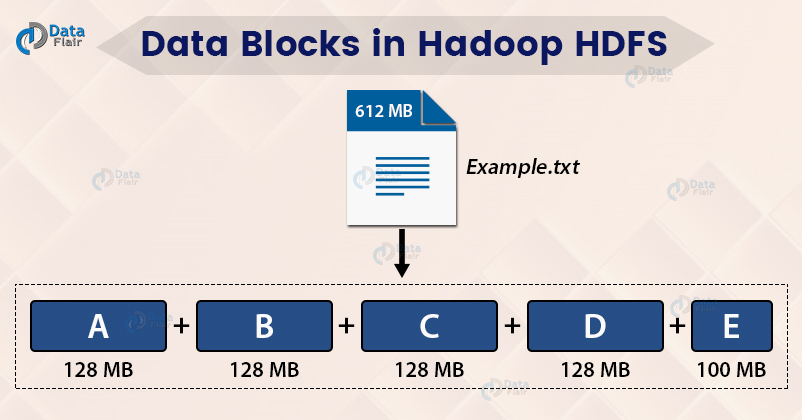
Internally, HDFS split the file into block-sized chunks called a block. The size of the block is 128 Mb by default. One can configure the block size as per the requirement.
For example, if there is a file of size 612 Mb, then HDFS will create four blocks of size 128 Mb and one block of size 100 Mb.
The file of a smaller size does not occupy the full block size space in the disk.
For example, the file of size 2 Mb will occupy only 2 Mb space in the disk.
The user doesn’t have any control over the location of the blocks.
Read the HDFS Block article to explore in detail.
HDFS is highly fault-tolerant. Now, look at what makes HDFS fault-tolerant.
What is Replication Management?
For a distributed system, the data must be redundant to multiple places so that if one machine fails, the data is accessible from other machines.
In Hadoop, HDFS stores replicas of a block on multiple DataNodes based on the replication factor.
The replication factor is the number of copies to be created for blocks of a file in HDFS architecture.
If the replication factor is 3, then three copies of a block get stored on different DataNodes. So if one DataNode containing the data block fails, then the block is accessible from the other DataNode containing a replica of the block.
If we are storing a file of 128 Mb and the replication factor is 3, then (3*128=384) 384 Mb of disk space is occupied for a file as three copies of a block get stored.
This replication mechanism makes HDFS fault-tolerant.
Read the Fault tolerance article to learn in detail.
What is Rack Awareness in HDFS Architecture?
Let us now talk about how HDFS store replicas on the DataNodes? What is a rack? What is rack awareness?
Rack is the collection of around 40-50 machines (DataNodes) connected using the same network switch. If the network goes down, the whole rack will be unavailable.
Rack Awareness is the concept of choosing the closest node based on the rack information.
To ensure that all the replicas of a block are not stored on the same rack or a single rack, NameNode follows a rack awareness algorithm to store replicas and provide latency and fault tolerance.
Suppose if the replication factor is 3, then according to the rack awareness algorithm:
- The first replica will get stored on the local rack.
- The second replica will get stored on the other DataNode in the same rack.
- The third replica will get stored on a different rack.
HDFS Read and Write Operation
1. Write Operation
When a client wants to write a file to HDFS, it communicates to the NameNode for metadata. The Namenode responds with a number of blocks, their location, replicas, and other details. Based on information from NameNode, the client directly interacts with the DataNode.
The client first sends block A to DataNode 1 along with the IP of the other two DataNodes where replicas will be stored. When Datanode 1 receives block A from the client, DataNode 1 copies the same block to DataNode 2 of the same rack. As both the DataNodes are in the same rack, so block transfer via rack switch. Now DataNode 2 copies the same block to DataNode 4 on a different rack. As both the DataNoNes are in different racks, so block transfer via an out-of-rack switch.
When DataNode receives the blocks from the client, it sends write confirmation to Namenode.
The same process is repeated for each block of the file.
2. Read Operation
To read from HDFS, the client first communicates with the NameNode for metadata. The Namenode responds with the locations of DataNodes containing blocks. After receiving the DataNodes locations, the client then directly interacts with the DataNodes.
The client starts reading data parallelly from the DataNodes based on the information received from the NameNode. The data will flow directly from the DataNode to the client.
When a client or application receives all the blocks of the file, it combines these blocks into the form of an original file.
Go through the HDFS read and write operation article to study how the client can read and write files in Hadoop HDFS.
Overview Of HDFS Architecture
In Hadoop HDFS, NameNode is the master node and DataNodes are the slave nodes. The file in HDFS is stored as data blocks.
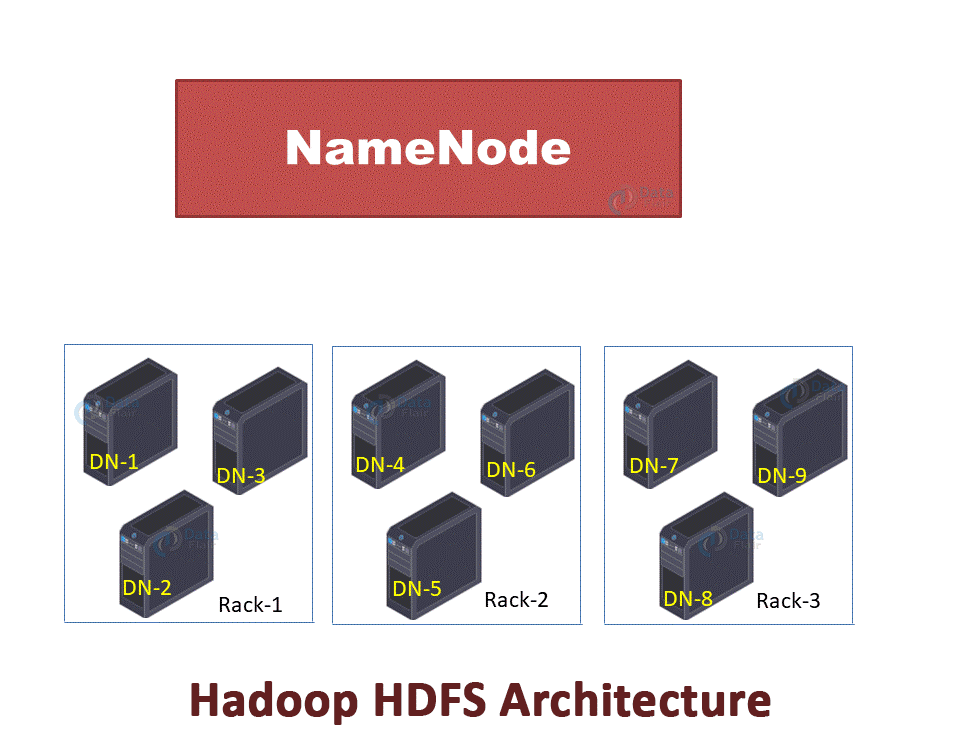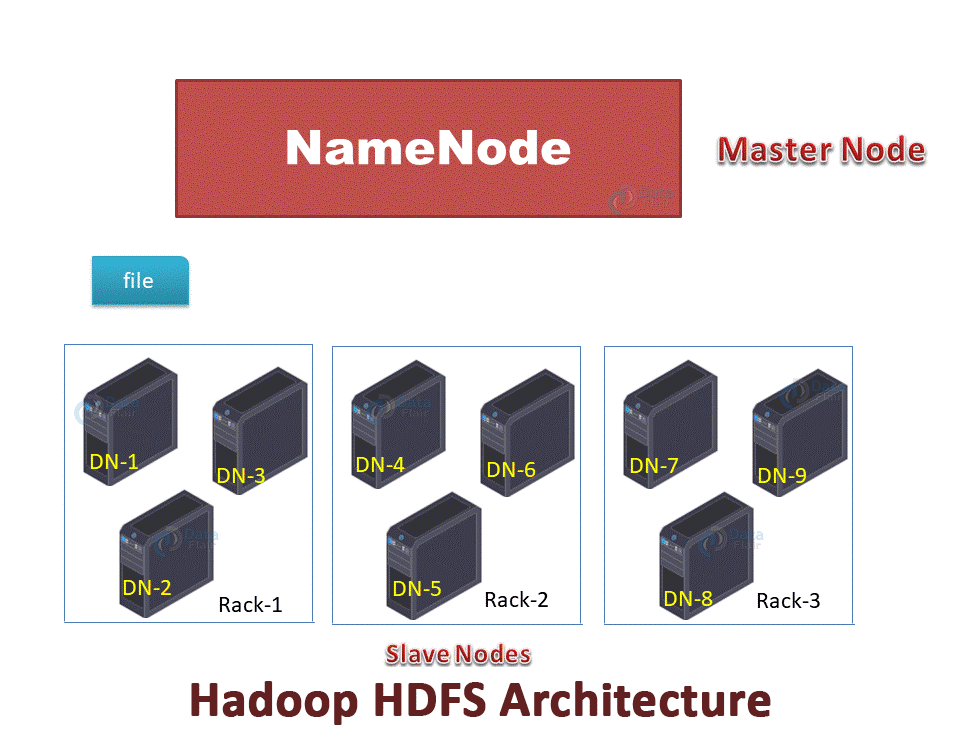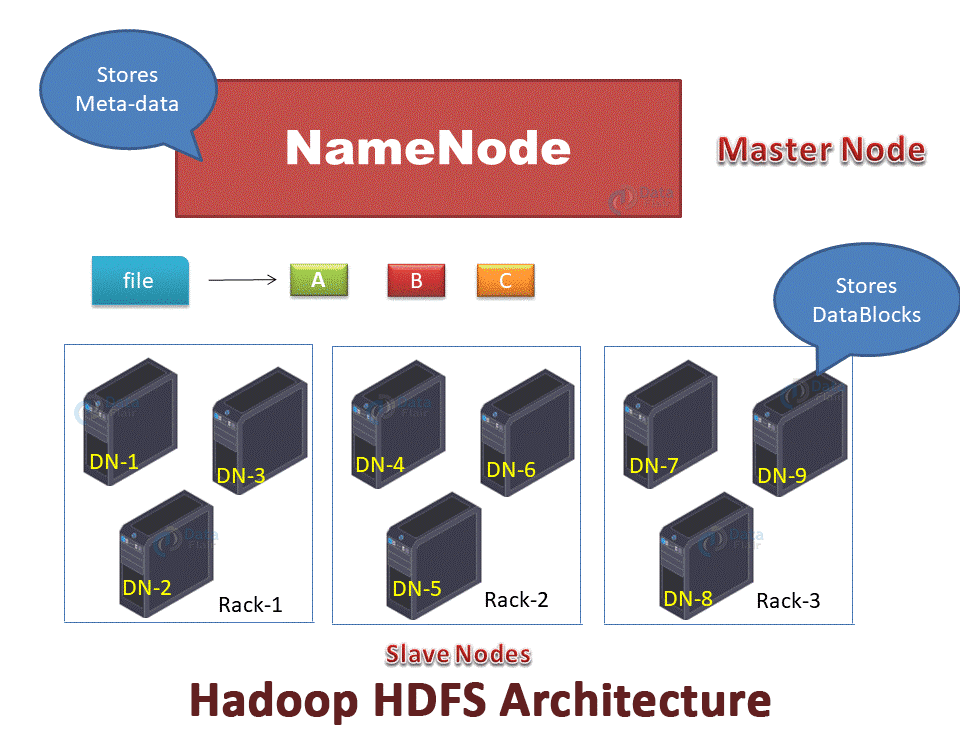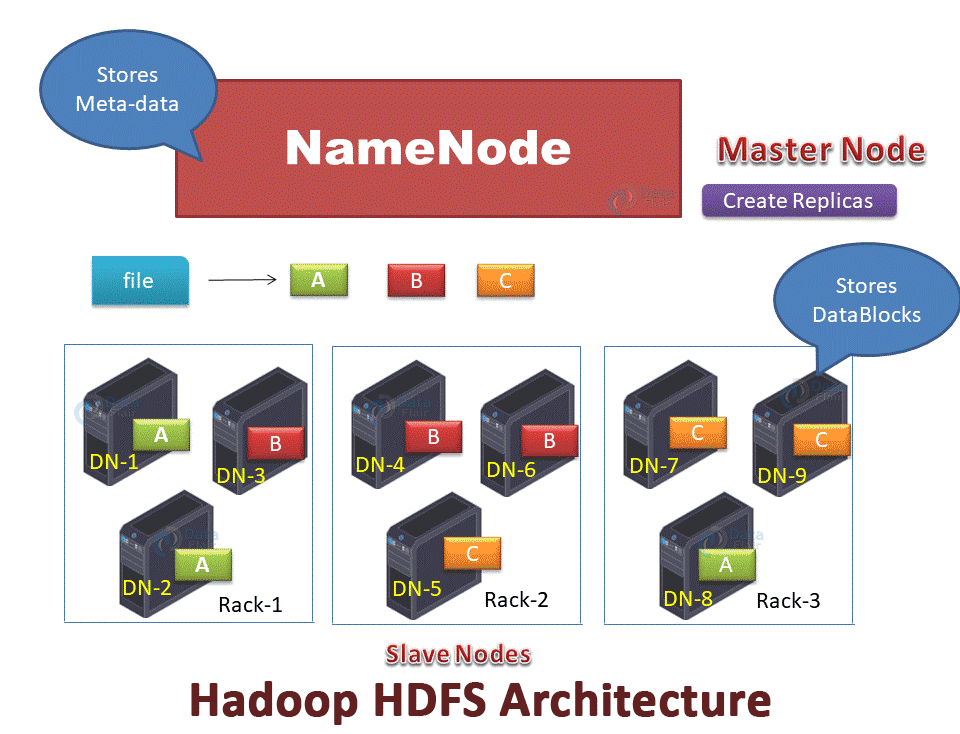
The file is divided into blocks (A, B, C in the below GIF). These blocks get stored on different DataNodes based on the Rack Awareness Algorithm. Block A on DataNode-1(DN-1), block B on DataNode-6(DN-6), and block C on DataNode-7(DN-7).
To provide Fault Tolerance, replicas of blocks are created based on the replication factor.
In the below GIF, 2 replicas of each block is created (using default replication factor 3). Replicas were placed on different DataNodes, thus ensuring data availability even in the case of DataNode failure or rack failure.
So, This was all on HDFS Architecture Tutorial. Follow the following links to master HDFS architecture.
Summary
After reading the HDFS architecture tutorial, we can conclude that the HDFS divides the files into blocks. The size of the block is 128 Mb by default, which we can configure as per the requirements.
The master node (NameNode) stores and manages the metadata about block locations, blocks of a file, etc.The DataNode stores the actual data blocks. The Master Node manages the DataNodes.
HDFS creates replicas of blocks and stores them on different DataNodes in order to provide fault tolerance. Also, NameNode uses the Rack Awareness algorithm to improve cluster performance.
Loving Hadoop? Join our course and Boost Your Career with BIG DATA
If you face any difficulty in this HDFS Architecture tutorial, please comment and ask.
Keep Learning!!
Did we exceed your expectations?
If Yes, share your valuable feedback on Google





Well explained HDFS Architecture. Rarely find this informative HDFS architecture guide. The HDFS Architecture Diagram made it very easy for me to understand the HDFS Architecture. This HDFS Architecture Explanation also helped in my recent interview of Hadoop Architect.
Wowee ! The best answer available on this topic HDFS and Map Reduce. Great explaination here its the best one .
Thank you Shubham for sharing such a positive experience and taking the time to leave this excellent review on Hadoop HDFS Architecture.
If you want to read some more articles on Hadoop HDFS, you can follow the link given below:
https://data-flair.training/blogs/hadoop-hdfs-data-read-and-write-operations/
Hii Renuka,
You are just amazing. Very Glad to see that our Hadoop HDFS Architecture has such a good impact on you. I hope you checked all the links given in the tutorial of Hadoop HDFS Architecture. You can also check our article on Hadoop interview questions.
Best wishes from us.
Well explained with good example.
Hii Vikas,
Glad you like our explanation of Hadoop HDFS Architecture. We always try to give you a practical example along with theory so that you can understand the concepts easily. You can also go through the link given in the blog, for better Hadoop HDFS understanding.
what is hop in hadoop architecture
what is hop in hadoop architecture?
Fabulous explanation on HDFS complete architecture. Great explanation with good examples.
Is Checkpointing node and backup node are alternates to each other ?
are they both used in HA environment only ?
Nice tried but I think its not enough. What about Journal nodes, ZKFC, QJM etc.