HDFS Data Write Operation – Anatomy of file write in Hadoop
Ever thought how files are written in the world’s most reliable storage?
After learning the HDFS read operation, let us now see the Hadoop HDFS file write operation. In this article, we will study the HDFS write operations. The article describes the internals of HDFS write and what happens if DataNode fails during file write.
Introduction to HDFS
HDFS is the distributed file system in Hadoop for storing huge volumes and variety of data. HDFS follows the master-slave architecture where the NameNode is the master node, and DataNodes are the slave nodes. The files in HDFS are broken into data blocks. The NameNode stores the metadata about the blocks, and DataNodes stores the data blocks.
Explore everything that HDFS offers by HDFS introductory tutorial.
Let’s see how the files are written in Hadoop HDFS.
HDFS write operation

To write data in HDFS, the client first interacts with the NameNode to get permission to write data and to get IPs of DataNodes where the client writes the data. The client then directly interacts with the DataNodes for writing data. The DataNode then creates a replica of the data block to other DataNodes in the pipeline based on the replication factor.
DFSOutputStream in HDFS maintains two queues (data queue and ack queue) during the write operation.
1. The client interacts with HDFS NameNode
- To write a file inside the HDFS, the client first interacts with the NameNode. NameNode first checks for the client privileges to write a file. If the client has sufficient privilege and there is no file existing with the same name, NameNode then creates a record of a new file.
- NameNode then provides the address of all DataNodes, where the client can write its data. It also provides a security token to the client, which they need to present to the DataNodes before writing the block.
- If the file already exists in the HDFS, then file creation fails, and the client receives an IO Exception.
2. The client interacts with HDFS DataNode
After receiving the list of the DataNodes and file write permission, the client starts writing data directly to the first DataNode in the list. As the client finishes writing data to the first DataNode, the DataNode starts making replicas of a block to other DataNodes depending on the replication factor.
If the replication factor is 3, then there will be a minimum of 3 copies of blocks created in different DataNodes, and after creating required replicas, it sends an acknowledgment to the client.
Thus it leads to the creation of a pipeline, and data replication to the desired value, in the cluster.
Internals of file write in Hadoop HDFS
Let us understand the HDFS write operation in detail. The following steps will take place while writing a file to the HDFS:
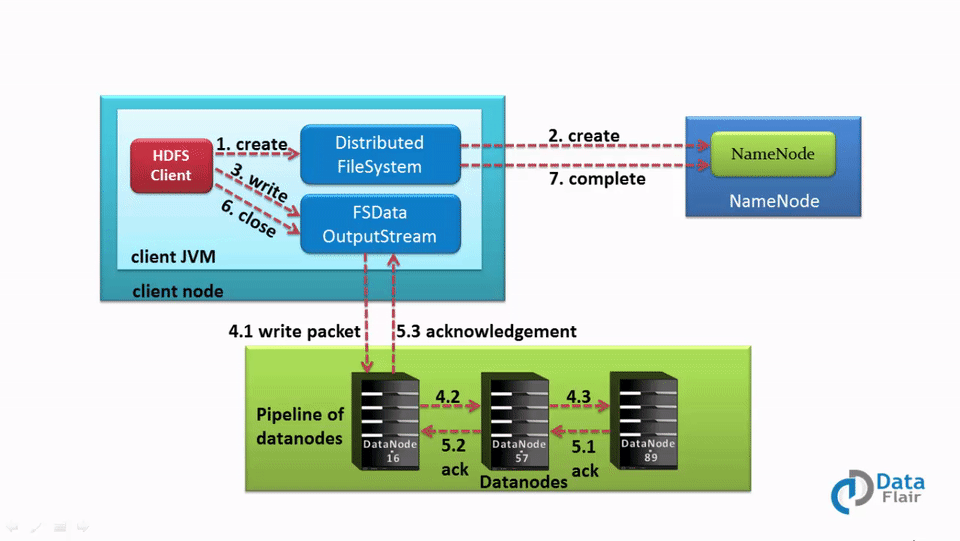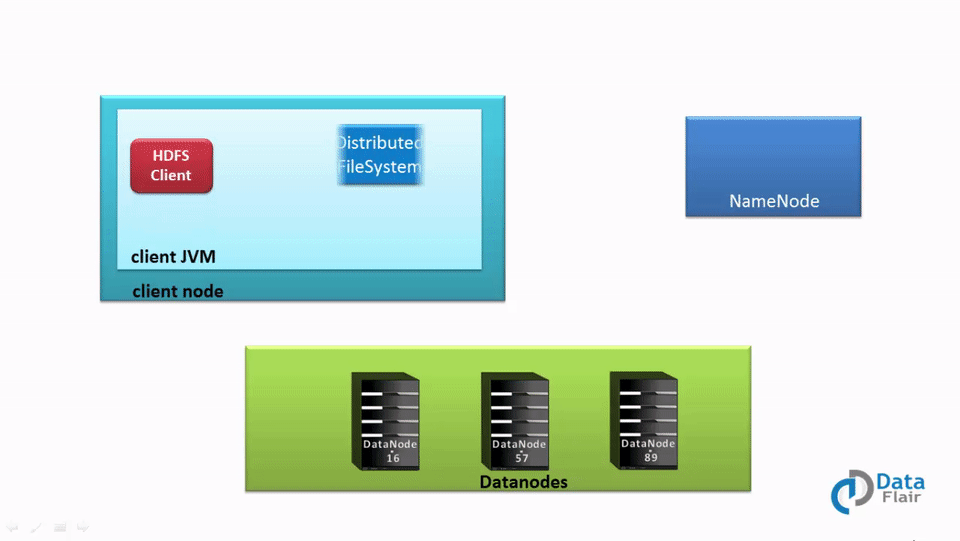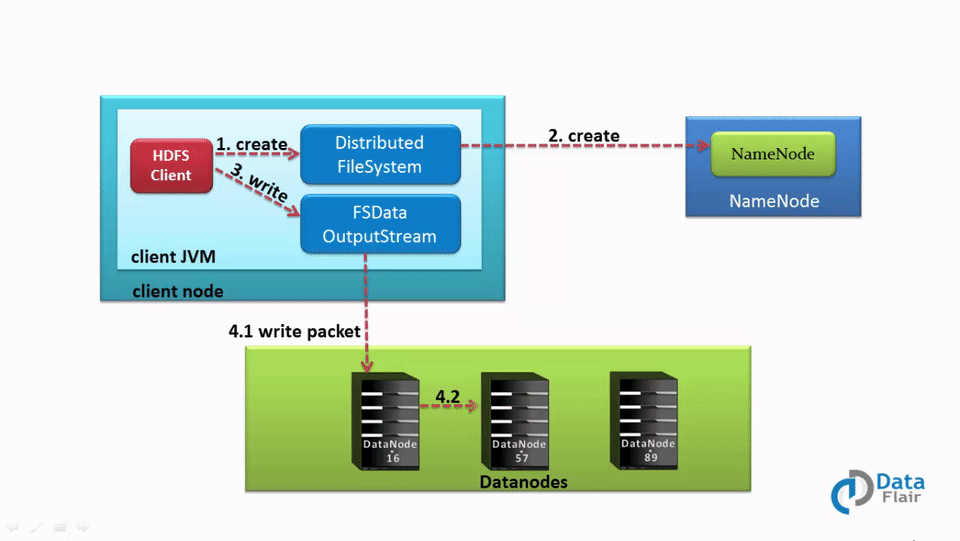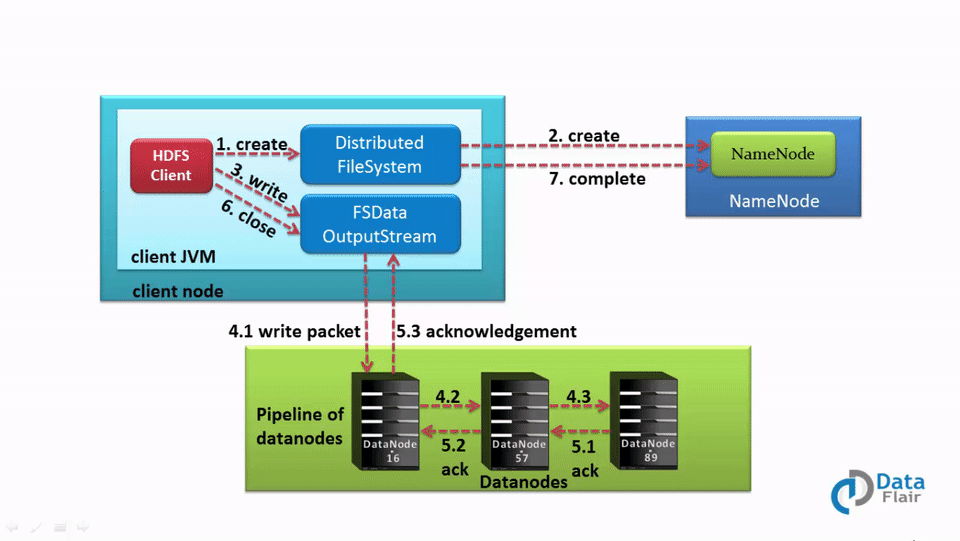
1. The client calls the create() method on DistributedFileSystem to create a file.
2. DistributedFileSystem interacts with NameNode through the RPC call to create a new file in the filesystem namespace with no blocks associated with it.
3. The NameNode checks for the client privileges and makes sure that the file doesn’t already exist. If the client has sufficient privileges and no file with the same name exists, the NameNode makes a record of the new file. Otherwise, the client receives an I/O exception, and file creation fails. The DistributedFileSystem then returns an FSDataOutputStream for the client where the client starts writing data. FSDataOutputstream, in turn, wraps a DFSOutputStream, which handles communication with the DataNodes and NameNode.
4. As the client starts writing data, the DFSOutputStream splits the client’s data into packets and writes it to an internal queue called the data queue. DataStreamer, which is responsible for telling the NameNode to allocate new blocks by choosing the list of suitable DataNode to store the replicas, uses this data queue.
The list of DataNode forms a pipeline. The number of DataNodes in the pipeline depends on the replication factor.
Suppose the replication factor is 3, so there are three nodes in the pipeline.
The DataStreamer streams the packet to the first DataNode in the pipeline, which stores each packet and forwards it to the second node in the pipeline. Similarly, the second DataNode stores the packet and transfers it to the next node in the pipeline (last node).
Finding difficulty ? Just look at this video to understand the HDFS file write operation easily.
5. The DFSOutputStream also maintains another queue of packets, called ack queue, which is waiting for the acknowledgment from DataNodes.
Packet in the ack queue gets remove only when it receives an acknowledgment from all the DataNodes in the pipeline.
6. The client calls the close() method on the stream when he/she finishes writing data. Thus, before communicating the NameNode to signal about the file complete, the client close() method’s action pushes the remaining packets to the DataNode pipeline and waits for the acknowledgment.
7. As the Namenode already knows about the blocks (the file made of), so the NameNode only waits for blocks to be minimally replicated before returning successfully.
What happens if DataNode fails while writing a file in the HDFS?
While writing data to the DataNode, if DataNode fails, then the following actions take place, which is transparent to the client writing the data.
1. The pipeline gets closed, packets in the ack queue are then added to the front of the data queue making DataNodes downstream from the failed node to not miss any packet.
2. Then the current block on the alive DataNode gets a new identity. This id is then communicated to the NameNode so that, later on, if the failed DataNode recovers, the partial block on the failed DataNode will be deleted.
3. The failed DataNode gets removed from the pipeline, and a new pipeline gets constructed from the two alive DataNodes. The remaining of the block’s data is then written to the alive DataNodes, added in the pipeline.
4. The NameNode observes that the block is under-replicated, and it arranges for creating further copy on another DataNode. Other coming blocks are then treated as normal.
How to Write a file in HDFS – Java Program
A sample code to write a file to HDFS in Java is as follows:
FileSystem fileSystem = FileSystem.get(conf);
// Check if the file already exists
Path path = new Path("/path/to/file.ext");
if (fileSystem.exists(path)) {
System.out.println("File " + dest + " already exists");
return;
}
// Create a new file and write data to it.
FSDataOutputStream out = fileSystem.create(path);
InputStream in = new BufferedInputStream(new FileInputStream(
new File(source)));
byte[] b = new byte[1024];
int numBytes = 0;
while ((numBytes = in.read(b)) > 0) {
out.write(b, 0, numBytes);
}
// Close all the file descripters
in.close();
out.close();
fileSystem.close();Summary
After reading this article, you have a good idea about the HDFS file write operation. From this article, we clearly understand the anatomy of file write in Hadoop.
The article has described the file write in detail along with the explanation of replicas creation during file write. We have also seen what happens if the DataNode fails while writing the file.
Now its time to play with HDFS, follow frequently used HDFS Command-List tutorial.
Any Doubts? Ask DataFlair
Keep Executing!!
Did you know we work 24x7 to provide you best tutorials
Please encourage us - write a review on Google





Thanks for the detail guide on hdfs. Before landing on this site i had no idea what hdfs is. but now concept is clear
Wonderful Web site, Continue the wonderful work. Thanks a lot!.
Very good Website, Carry on the beneficial work. Thanks a ton!.
Hello team, I found your blog very useful for mu purpose. I am a frequent visitor of your blogs. Please keep sharing the like material to help people like me.. Thanks!!!
Nicely explained.. Thanks ,I liked it
It’s an amazing paragraph for all the online visitors; they will
obtain advantage from it I am sure.
when i practice command -put, there is error to say no such file and directory, but when i use -ls the directory and file, there exist. why?
Hi Junwen,
The Hadoop HDFS command -put copies files or directories from the local filesystem to the destination in the Hadoop filesystem.
The Hadoop HDFS command -ls enlist all the files and directories present in the specified path.
While practicing -put command might be you are providing the wrong file path due to which you are getting such error. Check your local file-path.
Refer to the Dataflair HDFS command article to get more clearance about the HDFS command.