HDFS Disk Balancer – Learn how to Balance Data on DataNode
Disk Balancer is a command-line tool introduced in Hadoop 3 for balancing the disks within the DataNode. HDFS diskbalancer is different from the HDFS Balancer, which balances the distribution across the nodes.
In this article, we will study the following points:
- What is the need for Disk Balancer in Hadoop HDFS
- Introduction to HDFS Disk Balancer
- How Disk Balancer works
- Functions of HDFS Disk Balancer
- HDFS Disk Balancer commands
- HDFS Disk Balancer Settings
[ps2id id=’Need-for-disk-Balancer’ target=”/]Need for HDFS disk Balancer
In Hadoop HDFS, DataNode distributes data blocks between the disks on the DataNode. While writing new blocks in HDFS, DataNodes chooses volume-choosing policies (round-robin policy or available space policy) to choose disk (volume) for a block.
Round-Robin policy: It spread the new blocks evenly across the available disks. DataNode uses this policy by default.
Available space policy: This policy writes data to those disks that have more free space (by percentage).
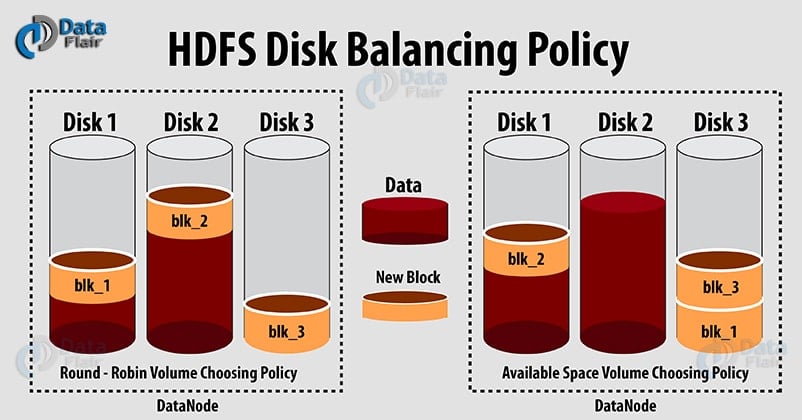
However, with round-robin policy in the long-running cluster, DataNodes sometimes unevenly fill their storage directories (disks/volume), leading to situations where certain disks are full while others are significantly less used. This happens either because of large amounts of writes and deletes or due to disk replacement.
Also, if we use available-space based volume-choosing policy, then every new write will go to the newly-added empty disk making other disks idle during the period. This will create a bottleneck on the new disk.
Thus there arises a need for Intra DataNode Balancing (even distribution of data blocks within DataNode) to address the Intra-DataNode skews (uneven distribution of blocks across disk), which occur due to disk replacement or random writes and deletes.
Therefore, a tool named Disk Balancer was introduced in Hadoop 3.0 that focused on distributing data within a node.
[ps2id id=’Introduction-to-Disk-Balancer’ target=”/]Introduction to HDFS Disk Balancer
Disk Balancer is a command-line tool introduced in Hadoop HDFS for Intra-DataNode balancing. HDFS diskbalancer spread data evenly across all disks of a DataNode. Unlike a Balancer which rebalances data across the DataNode, DiskBalancer distributes data within the DataNode.
HDFS Disk Balancer operates against a given DataNode and moves blocks from one disk to another.
[ps2id id=’How-Disk-Balancer-works’ target=”/]How HDFS Disk Balancer Works
HDFS Disk Balancer operates by creating a plan, which is a set of statements that describes how much data should move between two disks, and goes on to execute that set of statements on the DataNode. A plan consists of multiple move steps. Each move step in a plan has an address of the destination disk, source disk. A move step also has the number of bytes to move. This plan is executed against an operational DataNode.
By default, Disk Balancer is not enabled on a Hadoop cluster. One can enable the Disk Balancer in Hadoop by setting dfs.disk.balancer.enabled true in hdfs-site.xml.
[ps2id id=’Functions-of-Disk-Balancer’ target=”/]Functions of HDFS Disk Balancer
HDFS Diskbalancer supports two major functions i.e, reporting and balancing.
1. Data Spread Report
In order to define a way to measure which machines in the cluster suffer from the uneven data distribution, the HDFS disk balancer defines the HDFS Volume Data Density metric and the Node Data Density metric.
HDFS Volume data density metric allows us to compare how well the data is spread across different volumes of a given node.
The Node data density metric allows comparing between nodes.
1.1 Volume Data Density or Intra-Node Data Density
Volume data density metric computes how much data exits on a node and what should be the ideal storage on each volume.
The ideal storage percentage for each device is equal to the total data stored on that node divided by the total disk capacity on that node for each storage-type.
Suppose we have a machine with four volumes – Disk1, Disk2, Disk3, Disk4.
The following table shows the metric and its computation.
Table 1: Disk capacity and usage on a machine
| Disk1 | Disk2 | Disk3 | Disk4 | |
| capacity | 200 GB | 300 GB | 350 GB | 2500 GB |
| dfsUsed | 100 GB | 76 GB | 300 GB | 475 GB |
| dfsUsedRatio | 0.5 | 0.25 | 0.85 | 0.95 |
| volumeDataDensity | 0.20 | 0.45 | -0.15 | -0.24 |
In this example,
Total capacity= 200 + 300 + 350 + 500 = 1350GB
and
Total Used= 100 + 76 + 300 + 475 = 951 GB
Therefore, the ideal storage on each volume/disk is:
Ideal storage = total Used ÷ total capacity
= 951÷1350 = 0.70 or 70% of capacity of each disk.
Also, volume data density is equal to the difference between ideal-Storage and current dfsUsedRatio.
Therefore, volume data density for disk1 is:
VolumeDataDensity = idealStorage – dfs Used Ratio
= 0.70-0.50 = 0.20
A positive value for volumeDataDensity indicates that disk is under-utilized and, a negative value indicates that disk is over-utilized in relation to the current ideal storage target.
1.2. Node Data Density or Inter-Node Data Density
After calculating volume data density, we can calculate Node Data Density, which is the sum of all absolute values of volume data density.
This allows comparing nodes that need our attention in a given cluster. Lower nodeDataDensity values indicate better spread, and higher values indicate more skewed data distribution.
1.3 Reports
Once we have volumeDataDensity and nodeDataDensity, we can find the top 20 nodes in the cluster that skewed data distribution, or we can get the volumeDataDensity for a given node.
2. Disk balancing
Once we know that a certain node needs balancing, we compute or read the current volumeDataDensity. With this information, we can easily decide which volumes are over-provisioned and which are under-provisioned. In order to move data from one volume to another in the DataNode, we would add a protocol based RPC similar to the one used by the balancer. Thus, allowing the user to replace disks without worrying about decommissioning a node.
[ps2id id=’Commands-Supported-by-Disk-Balancer’ target=”/]Commands Supported by HDFS Disk Balancer
Let us now see the various commands supported by the HDFS Disk Balancer.
1. plan
HDFS diskbalancer plan command Usage:
hdfs diskbalancer -plan <datanode>
HDFS diskbalancer plan Description:
The plan command generates the plan for the specified DataNode. This command can be run against a given DataNode. There are some additional options that can be used with hdfs diskbalancer plan command that allows users to control the output and execution of a plan.
| Options | Description |
| -out | controls the output location of a plan file |
| -bandwidth | It enables the user to set maximum bandwidth used for running the Disk Balancer. This option thus helps in limiting the amount of data moved by the Disk Balancer per second on an operational DataNode. This option is not necessary to be set because if it is not specified, then the disk balancer uses the default bandwidth of 10 MB/s. |
| –thresholdPercentage | This allows the user to set the thresholdPercentage, which defines the value at which disks start participating in the data redistribution or balancing operation. The default thresholdPercentage value is 10%, which means a disk is used in balancing operation only when the disk contains 10% more or less data then the ideal storage value. |
| -maxerror | It allows users to specify the number of errors to be ignored for a move operation between two disks before we abort a move step. If it is not specified, then the disk balancer uses the default value. |
| -v | Verbose mode, specifying this option forces the plan command to display a summary of the plan on stdout. |
| -fs | This option specifies the NameNode to use. If this is not specified, then Disk Balancer uses the default NameNode from the configuration. |
Example:
hdfs diskbalancer -plan node1.mycluster.com
2. execute
HDFS diskbalancer execute command Usage:
hdfs diskbalancer -execute <JSON file path>
HDFS diskbalancer execute command Description:
The execute command executes the plan against the DataNode for which the plan was generated. The <JSON File Path> is the path to the JSON document, which contains the generated plan (nodename.plan.json).
Example:
hdfs diskbalancer -execute /system/diskbalancer/nodename.plan.json
3. query
HDFS diskbalancer query command Usage:
hdfs diskbalancer -query <datanode>
HDFS diskbalancer query command Description:
The query command gets the current status of the HDFS disk balancer from a DataNode for which the plan is running.
Example:
hdfs diskbalancer -query nodename.mycluster.com
4. cancel
HDFS diskbalancer cancel command Usage:
hdfs diskbalancer -cancel <JSON file path> OR hdfs diskbalancer -cancel planID node <nodename>
HDFS diskbalancer cancel command Description:
The cancel command cancels the running plan.
The <JSON file path> is the path to the JSON document, which contains the generated plan.
planID is the ID of the plan to cancel.
Example:
hdfs diskbalancer -cancel /system/diskbalancer/nodename.plan.json
5. report
HDFS diskbalancer report command Usage:
hdfs diskbalancer -fs https://namenode.uri -report <file://> OR hdfs diskbalancer -fs https://namenode.uri -report [<DataNodeID|IP|Hostname>,...] OR hdfs diskbalancer -fs http://namenode.uri -report -top topnum
HDFS diskbalancer report command Description:
The report command gives a detailed report of the specified DataNodes or top DataNodes that require a disk balancer. The DataNodes can be specified either by a host file or by the list of DataNodes separated by a comma.
| <file://> | specify the host file which lists the DataNodes for which you want to generate the reports. |
| [<DataNodeID|IP|Hostname>,..] | specify the DataNodeID, IP of the DataNode and the Hostname of the DataNode for which you want to generate the report. |
| topnum | specifies the number of top nodes that require a disk balancer. |
[ps2id id=’Disk-Balancer-Settings’ target=”/]Hadoop Disk Balancer Settings
We can control some of the diskbalancer settings through the hdfs-site.xml file. Let us see some of the diskbalancer settings with their description.
| Setting | Description |
| dfs.disk.balancer.enabled | Controls whether to enable the diskbalancer for a cluster or not. The default value is set to false, which indicates that the diskbalancer is disabled. The DataNodes will reject the execute command if this is not enabled. |
| dfs.disk.balancer.max.disk.throughputInMBpersec | This parameter controls the maximum bandwidth used by diskbalancer while balancing disk data. The default value is 10MB/s. |
| dfs.disk.balancer.max.disk.errors | This parameter sets the value of the maximum number of errors to be ignored for a move operation between two disks before we abort a move step. The default value for this is 5. |
| dfs.disk.balancer.block.tolerance.percent | The tolerance percent specifies the difference threshold between the data storage capacity and current status of each disk during data balancing among disks. For example, if the ideal storage capacity of a disk is 1 Tb and the value of this parameter is set to 10. If the data storage capacity of target disk reaches to 900 GB, then disk storage status is considered as perfect. |
| dfs.disk.balancer.plan.threshold.percent | This parameter controls the thresholdPercentage value for volume data density in a plan. If the absolute value of the volume data density of a disk is out of threshold value, it indicates data balancing is required. The default value is 10. |
| dfs.disk.balancer.top.nodes.number | This parameter specifies the top N nodes that require disk data balancing in a cluster. |
Conclusion
In short, we can conclude that a disk Balancer is a tool that distributes data blocks between the volumes of the DataNode.Thus, it addresses Intra-Node skew.
Also, the disk balancer moves data from one volume to another within nodes while nodes are alive, so users can replace disks without having to worry about decommissioning a node.
HDFS Disk Balancer support some of the commands like plan for generating a plan, execute for executing the plan against DataNode, query for querying the status of disk balancer, cancel to cancel the plan, etc.
Now explore HDFS Federation feature introduced in Hadoop 2.0
Still, if you have any query regarding HDFS Diskbalancer, ask in the comment section.
Keep Learning!!
Your opinion matters
Please write your valuable feedback about DataFlair on Google





Sir, which policy to use Round Robin or Available Space and why?
Hi ,
We have 5 node cluster using plain vanilla apache, recently we added a new node into the cluster now total we have 6 node cluster,after adding that new node into our cluster we ran the balancer.but its running very slowly, still its running, can any one please say how much time it will takes for complete balancing and how we get to know that balancing is completed.
Thanks…..
if we didn’t used balancer? what happened if data stored without balancer ? Please explain
Thank you for the document~
Is there any way to perform disk balancing when replacing a disk in a DataNode of Hadoop Cluster running on Hadoop 2 version?