HDFS Federation in Hadoop – Architecture and Benefits
Want to read the new feature added in Hadoop 2.0 and the motivation behind it?
In Hadoop HDFS, NameNode stores the metadata for every file and block in the filesystem. On very large clusters with many files, NameNode requires a large amount of memory for storing metadata for each file and block.
Also, the prior HDFS architecture supported a single NameNode that manages the file system namespace. Thus, the memory becomes the limiting factor for scaling, and single NameNode becomes a bottleneck. HDFS Federation feature added in Hadoop 2.0 release allowed a cluster to scale by adding more NameNodes.
In this article, we will study the HDFS federation feature in detail.
The article covers the following points:
- Introduction to Current HDFS architecture
- Limitations of Current HDFS Architecture
- Introduction to HDFS Federation
- HDFS Federation architecture
- Benefits of HDFS Federation
Let us first see the HDFS architecture prior to the HDFS Federation architecture release.
[ps2id id=’Introduction-to-Current-HDFS-architecture’ target=”/]Introduction to Current HDFS Architecture
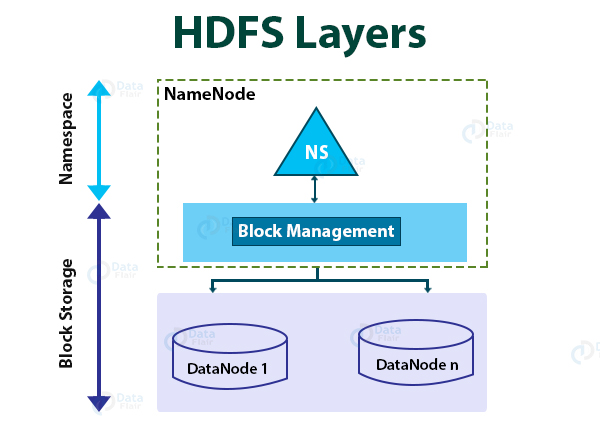
HDFS architecture has two layers:
1. Namespace
The Namespace layer in the HDFS architecture consists of files, blocks, and directories. This layer provides support for namespace related filesystem operations like create, delete, modify, and list files and directories.
Want to perform operations on HDFS files? Learn 12 frequently used HDFS commands.
2. Block Storage layer
Block Storage layer has two parts:
- Block Management: NameNode performs block management. Block Management provides DataNode cluster membership by handling registrations, and periodic heartbeats. It processes block reports and supports block related operations like create, delete, modify, or get block location. It also maintains locations of blocks, replica placement. Block Management manages block replication for under replicated blocks and deletes over replicated blocks.
- Storage: DataNode manages storage space by storing blocks on the local file system and providing read/write access.
This architecture allows for only single NameNode to maintain the filesystem namespace.
Thus it is simple to implement and works well for the small clusters. The big organizations like Yahoo, Facebook, faced some limitations when the cluster grew exponentially.
[ps2id id=’Limitations-of-Current-HDFS-Architecture’ target=”/]Limitations of Current HDFS Architecture
- Due to the tight coupling of namespace and the storage layer, an alternate implementation of NameNode is difficult. This limits the usage of block storage directly by the other services.
- Due to single NameNode, we can have only a limited number of DataNodes that a single NameNode can handle.
- The operations of the filesystem are also limited to the number of tasks that NameNode handles at a time. Thus, the performance of the cluster depends on the NameNode throughput.
- Also, because of a single namespace, there is no isolation among the occupant organizations which are using the cluster.
[ps2id id=’Introduction-to-HDFS-Federation’ target=”/]Introduction to HDFS Federation
HDFS Federation feature introduced in Hadoop 2 enhances the existing HDFS architecture. It overcomes HDFS architecture limitations (discussed above) by adding multiple NameNode/namespaces support to HDFS. This allows the use of more than one NameNode/namespace. Therefore, it scales the namespace horizontally by allowing the addition of NameNode in the cluster.
Let us now study the HDFS Federation architecture.
[ps2id id=’HDFS-Federation-architecture’ target=”/]HDFS Federation Architecture
In HDFS Federation architecture, there are multiple NameNodes and DataNodes.
Each NameNode has its own namespace and block pool.
All the NameNodes uses DataNodes as the common storage.
Every NameNode is independent of the other and does not require any coordination amongst themselves.
Each Datanode gets registered to all the NameNodes in the cluster and store blocks for all the block pools in the cluster.
Also, DataNodes periodically send heartbeats and block reports to all the NameNode in the cluster and handles the instructions from the NameNodes.
Look at the figure below that shows the architecture design of the HDFS Federation.
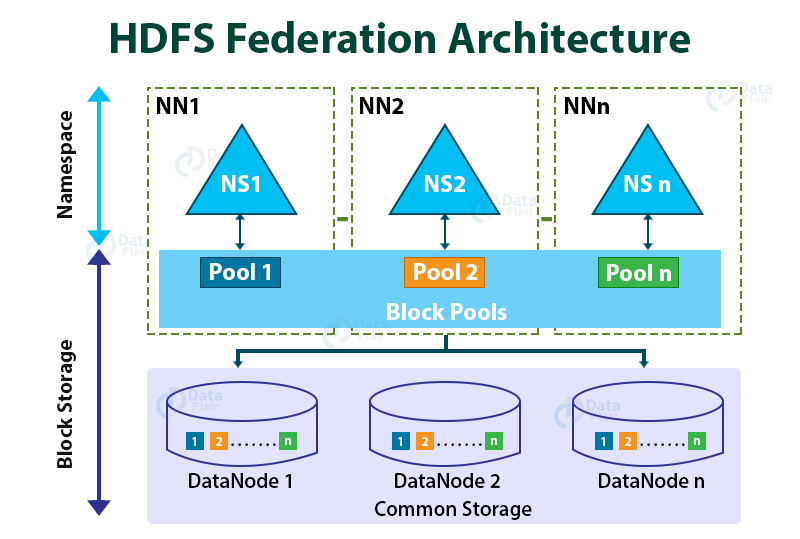
In the above figure, which represents HDFS Federation architecture, there are multiple NameNodes which are represented as NN1, NN2, ..NNn.
NS1, NS2, and so on are the multiple namespaces managed by their respective NameNode (NS1 by NN1, NS2 by NN2, and so on).
Each namespace has its own block pool (NS1 has Pool1, NS2 has Pool2, and so on).
Each Datanode store blocks for all the block pools in the cluster.
For example, DataNode1 stores the blocks from Pool 1, Pool 2, Pool3, etc.
Let us now understand the block pool and namespace volume in detail.
Block pool
Block pool in HDFS Federation architecture is the collection of blocks belonging to the single namespace. HDFS Federation architecture has a collection of block pools, and each block pool is managed independently from each other. This allows the generation of the Block IDs for new blocks by the namespace, without any coordination with other namespaces.
Namespace Volume
Namespace with its block pool is termed as Namespace Volume. The HDFS Federation architecture has the collection of Namespace volume, which is a self-contained management unit. On deleting the NameNode or namespace, the corresponding block pool present in the DataNodes also gets deleted. On upgrading the cluster, each namespace volume gets upgraded as a unit.
[ps2id id=’Benefits-of-HDFS-Federation’ target=”/]Benefits of HDFS Federation
1. Namespace Scalability
With federation, we can horizontally scale the namespace. This benefits the large clusters or cluster with too many small files because of more NameNode addition to the cluster.
2. Performance
It improves the performance of the filesystem as the filesystem operations are not limited by the throughput of a single NameNode.
3. Isolation
Due to multiple namespaces, it can provide isolation to the occupant organizations that are using the cluster.
Summary
HDFS federation feature added to Hadoop 2.x provides support for multiple NameNodes/namespaces. This overcomes the isolation, scalability, and performance limitations of the prior HDFS architecture.
HDFS Federation architecture also opens up the architecture for future innovations. It allows new services to use block storage directly.
Now, explore what is Erasure Coding in HDFS, and why this feature is introduced in Hadoop 3.0
If you like this post on HDFS federation or have any query, kindly inform us by leaving a comment in the section below. We will glad to solve them.
Keep Learning!!
We work very hard to provide you quality material
Could you take 15 seconds and share your happy experience on Google





This Is really A good article or blog on HDFS High Availability.
Please provide Resources manager HA article in Hadoop Cluster