Hadoop Ecosystem and Their Components – A Complete Tutorial
1. Hadoop Ecosystem Components
The objective of this Apache Hadoop ecosystem components tutorial is to have an overview of what are the different components of Hadoop ecosystem that make Hadoop so powerful and due to which several Hadoop job roles are available now. We will also learn about Hadoop ecosystem components like HDFS and HDFS components, MapReduce, YARN, Hive, Apache Pig, Apache HBase and HBase components, HCatalog, Avro, Thrift, Drill, Apache mahout, Sqoop, Apache Flume, Ambari, Zookeeper and Apache OOzie to deep dive into Big Data Hadoop and to acquire master level knowledge of the Hadoop Ecosystem.
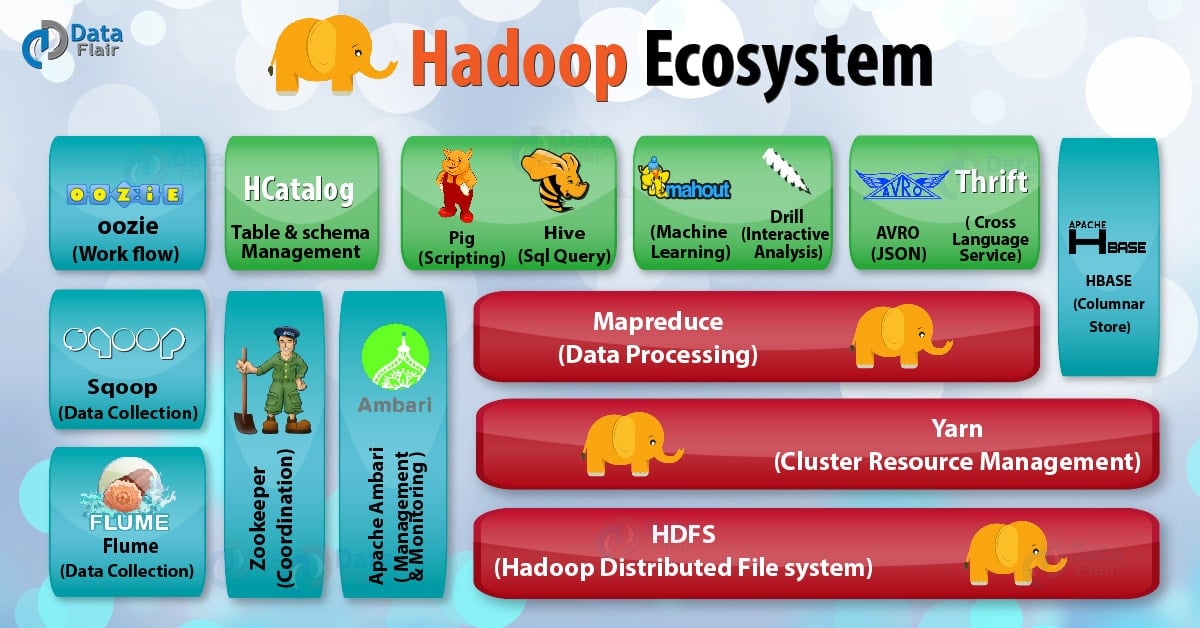
Hadoop Ecosystem and Their Components
2. Introduction to Hadoop Ecosystem
As we can see the different Hadoop ecosystem explained in the above figure of Hadoop Ecosystem. Now We are going to discuss the list of Hadoop Components in this section one by one in detail.
2.1. Hadoop Distributed File System
It is the most important component of Hadoop Ecosystem. HDFS is the primary storage system of Hadoop. Hadoop distributed file system (HDFS) is a java based file system that provides scalable, fault tolerance, reliable and cost efficient data storage for Big data. HDFS is a distributed filesystem that runs on commodity hardware. HDFS is already configured with default configuration for many installations. Most of the time for large clusters configuration is needed. Hadoop interact directly with HDFS by shell-like commands.
HDFS Components:
There are two major components of Hadoop HDFS- NameNode and DataNode. Let’s now discuss these Hadoop HDFS Components-
i. NameNode
It is also known as Master node. NameNode does not store actual data or dataset. NameNode stores Metadata i.e. number of blocks, their location, on which Rack, which Datanode the data is stored and other details. It consists of files and directories.
Tasks of HDFS NameNode
- Manage file system namespace.
- Regulates client’s access to files.
- Executes file system execution such as naming, closing, opening files and directories.
ii. DataNode
It is also known as Slave. HDFS Datanode is responsible for storing actual data in HDFS. Datanode performs read and write operation as per the request of the clients. Replica block of Datanode consists of 2 files on the file system. The first file is for data and second file is for recording the block’s metadata. HDFS Metadata includes checksums for data. At startup, each Datanode connects to its corresponding Namenode and does handshaking. Verification of namespace ID and software version of DataNode take place by handshaking. At the time of mismatch found, DataNode goes down automatically.
Tasks of HDFS DataNode
- DataNode performs operations like block replica creation, deletion, and replication according to the instruction of NameNode.
- DataNode manages data storage of the system.
This was all about HDFS as a Hadoop Ecosystem component.
Refer HDFS Comprehensive Guide to read Hadoop HDFS in detail and then proceed with the Hadoop Ecosystem tutorial.
2.2. MapReduce
Hadoop MapReduce is the core Hadoop ecosystem component which provides data processing. MapReduce is a software framework for easily writing applications that process the vast amount of structured and unstructured data stored in the Hadoop Distributed File system.
MapReduce programs are parallel in nature, thus are very useful for performing large-scale data analysis using multiple machines in the cluster. Thus, it improves the speed and reliability of cluster this parallel processing.
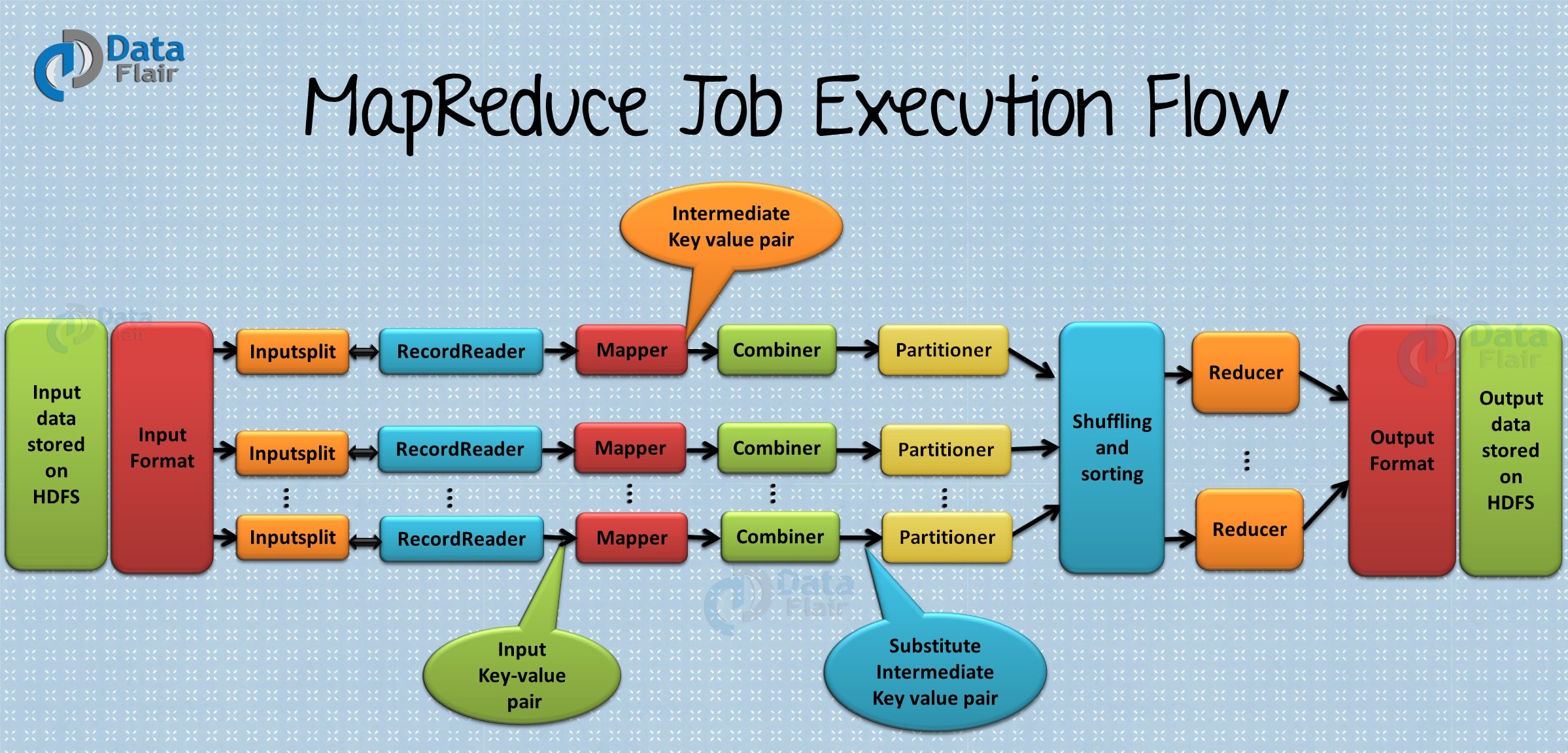
Hadoop MapReduce
Working of MapReduce
Hadoop Ecosystem component ‘MapReduce’ works by breaking the processing into two phases:
- Map phase
- Reduce phase
Each phase has key-value pairs as input and output. In addition, programmer also specifies two functions: map function and reduce function
Map function takes a set of data and converts it into another set of data, where individual elements are broken down into tuples (key/value pairs). Read Mapper in detail.
Reduce function takes the output from the Map as an input and combines those data tuples based on the key and accordingly modifies the value of the key. Read Reducer in detail.
Features of MapReduce
- Simplicity – MapReduce jobs are easy to run. Applications can be written in any language such as java, C++, and python.
- Scalability – MapReduce can process petabytes of data.
- Speed – By means of parallel processing problems that take days to solve, it is solved in hours and minutes by MapReduce.
- Fault Tolerance – MapReduce takes care of failures. If one copy of data is unavailable, another machine has a copy of the same key pair which can be used for solving the same subtask.
Refer MapReduce Comprehensive Guide for more details.
Hope the Hadoop Ecosystem explained is helpful to you. The next component we take is YARN.
2.3. YARN
Hadoop YARN (Yet Another Resource Negotiator) is a Hadoop ecosystem component that provides the resource management. Yarn is also one the most important component of Hadoop Ecosystem. YARN is called as the operating system of Hadoop as it is responsible for managing and monitoring workloads. It allows multiple data processing engines such as real-time streaming and batch processing to handle data stored on a single platform.

Hadoop Yarn Diagram
YARN has been projected as a data operating system for Hadoop2. Main features of YARN are:
- Flexibility – Enables other purpose-built data processing models beyond MapReduce (batch), such as interactive and streaming. Due to this feature of YARN, other applications can also be run along with Map Reduce programs in Hadoop2.
- Efficiency – As many applications run on the same cluster, Hence, efficiency of Hadoop increases without much effect on quality of service.
- Shared – Provides a stable, reliable, secure foundation and shared operational services across multiple workloads. Additional programming models such as graph processing and iterative modeling are now possible for data processing.
Refer YARN Comprehensive Guide for more details.
2.4. Hive
The Hadoop ecosystem component, Apache Hive, is an open source data warehouse system for querying and analyzing large datasets stored in Hadoop files. Hive do three main functions: data summarization, query, and analysis.
Hive use language called HiveQL (HQL), which is similar to SQL. HiveQL automatically translates SQL-like queries into MapReduce jobs which will execute on Hadoop.
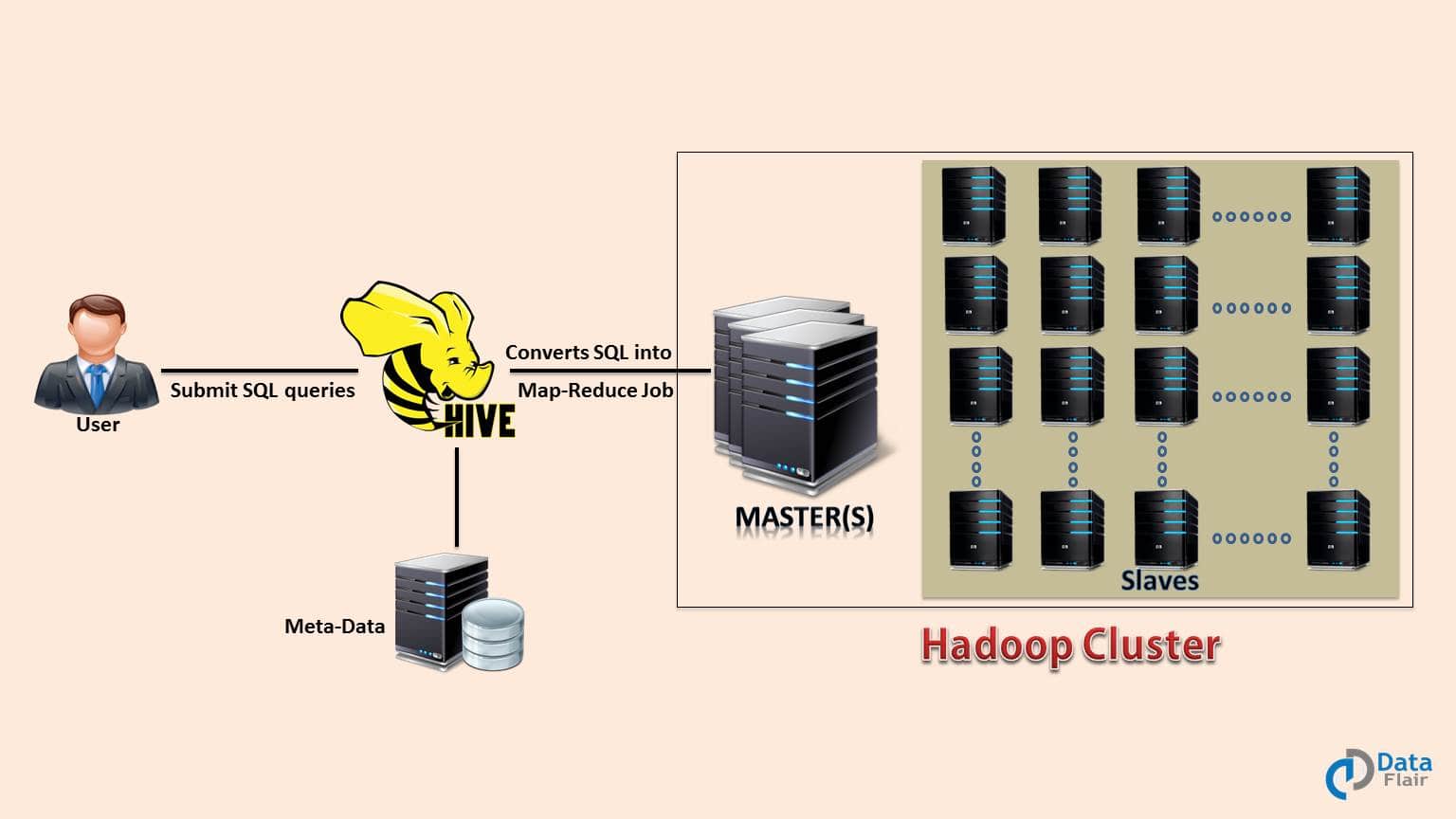
Hive Diagram
Main parts of Hive are:
- Metastore – It stores the metadata.
- Driver – Manage the lifecycle of a HiveQL statement.
- Query compiler – Compiles HiveQL into Directed Acyclic Graph(DAG).
- Hive server – Provide a thrift interface and JDBC/ODBC server.
Refer Hive Comprehensive Guide for more details.
2.5. Pig
Apache Pig is a high-level language platform for analyzing and querying huge dataset that are stored in HDFS. Pig as a component of Hadoop Ecosystem uses PigLatin language. It is very similar to SQL. It loads the data, applies the required filters and dumps the data in the required format. For Programs execution, pig requires Java runtime environment.
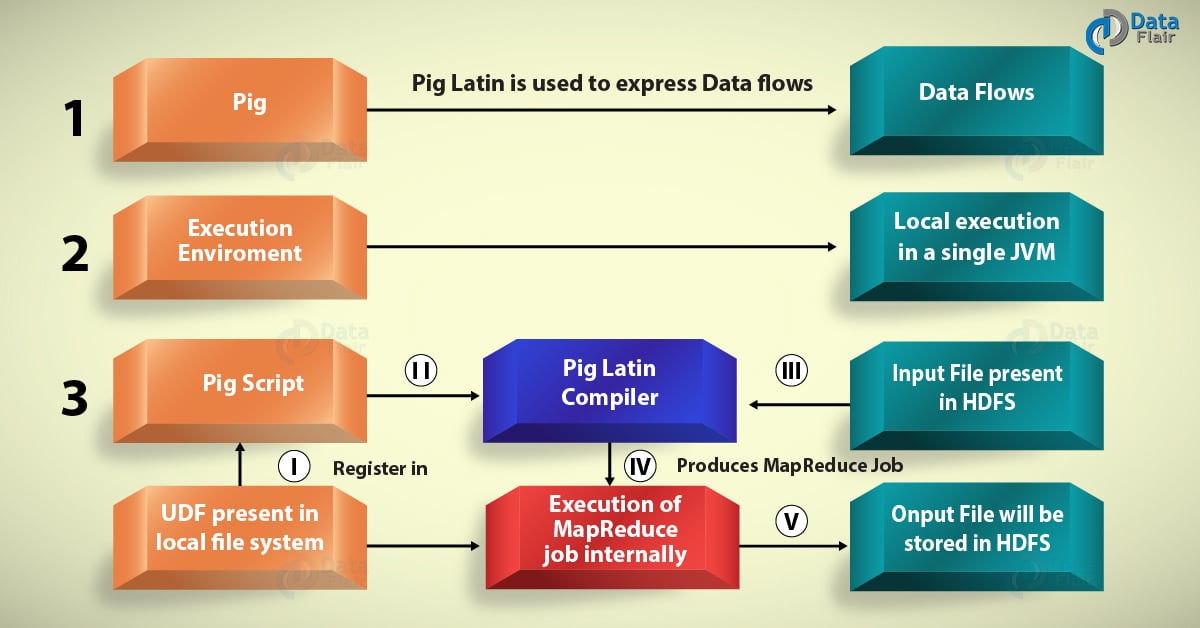
Pig Diagram
Features of Apache Pig:
- Extensibility – For carrying out special purpose processing, users can create their own function.
- Optimization opportunities – Pig allows the system to optimize automatic execution. This allows the user to pay attention to semantics instead of efficiency.
- Handles all kinds of data – Pig analyzes both structured as well as unstructured.
Refer Pig – A Complete guide for more details.
2.6. HBase
Apache HBase is a Hadoop ecosystem component which is a distributed database that was designed to store structured data in tables that could have billions of row and millions of columns. HBase is scalable, distributed, and NoSQL database that is built on top of HDFS. HBase, provide real-time access to read or write data in HDFS.

HBase Diagram
Components of Hbase
There are two HBase Components namely- HBase Master and RegionServer.
i. HBase Master
It is not part of the actual data storage but negotiates load balancing across all RegionServer.
- Maintain and monitor the Hadoop cluster.
- Performs administration (interface for creating, updating and deleting tables.)
- Controls the failover.
- HMaster handles DDL operation.
ii. RegionServer
It is the worker node which handles read, writes, updates and delete requests from clients. Region server process runs on every node in Hadoop cluster. Region server runs on HDFS DateNode.
Refer HBase Tutorial for more details.
2.7. HCatalog
It is a table and storage management layer for Hadoop. HCatalog supports different components available in Hadoop ecosystems like MapReduce, Hive, and Pig to easily read and write data from the cluster. HCatalog is a key component of Hive that enables the user to store their data in any format and structure.
By default, HCatalog supports RCFile, CSV, JSON, sequenceFile and ORC file formats.
Benefits of HCatalog:
- Enables notifications of data availability.
- With the table abstraction, HCatalog frees the user from overhead of data storage.
- Provide visibility for data cleaning and archiving tools.
2.8. Avro
Acro is a part of Hadoop ecosystem and is a most popular Data serialization system. Avro is an open source project that provides data serialization and data exchange services for Hadoop. These services can be used together or independently. Big data can exchange programs written in different languages using Avro.
Using serialization service programs can serialize data into files or messages. It stores data definition and data together in one message or file making it easy for programs to dynamically understand information stored in Avro file or message.
Avro schema – It relies on schemas for serialization/deserialization. Avro requires the schema for data writes/read. When Avro data is stored in a file its schema is stored with it, so that files may be processed later by any program.
Dynamic typing – It refers to serialization and deserialization without code generation. It complements the code generation which is available in Avro for statically typed language as an optional optimization.
Features provided by Avro:
- Rich data structures.
- Remote procedure call.
- Compact, fast, binary data format.
- Container file, to store persistent data.
2.9. Thrift
It is a software framework for scalable cross-language services development. Thrift is an interface definition language for RPC(Remote procedure call) communication. Hadoop does a lot of RPC calls so there is a possibility of using Hadoop Ecosystem componet Apache Thrift for performance or other reasons.
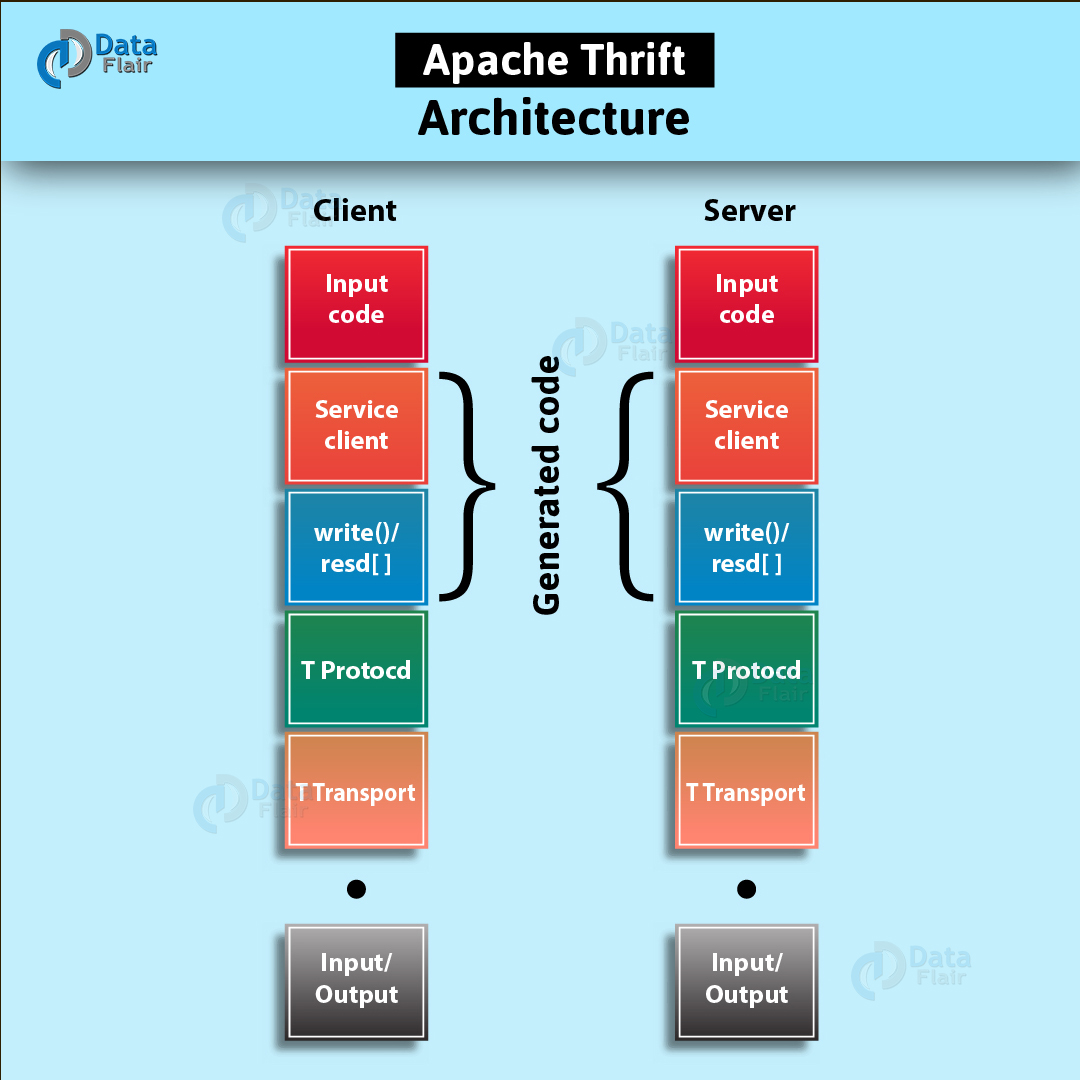
Thrift Diagram
2.10. Apache Drill
The main purpose of the Hadoop Ecosystem Component is large-scale data processing including structured and semi-structured data. It is a low latency distributed query engine that is designed to scale to several thousands of nodes and query petabytes of data. The drill is the first distributed SQL query engine that has a schema-free model.
Application of Apache drill
The drill has become an invaluable tool at cardlytics, a company that provides consumer purchase data for mobile and internet banking. Cardlytics is using a drill to quickly process trillions of record and execute queries.
Features of Apache Drill:
The drill has specialized memory management system to eliminates garbage collection and optimize memory allocation and usage. Drill plays well with Hive by allowing developers to reuse their existing Hive deployment.
- Extensibility – Drill provides an extensible architecture at all layers, including query layer, query optimization, and client API. We can extend any layer for the specific need of an organization.
- Flexibility – Drill provides a hierarchical columnar data model that can represent complex, highly dynamic data and allow efficient processing.
- Dynamic schema discovery – Apache drill does not require schema or type specification for data in order to start the query execution process. Instead, drill starts processing the data in units called record batches and discover schema on the fly during processing.
- Drill decentralized metadata – Unlike other SQL Hadoop technologies, the drill does not have centralized metadata requirement. Drill users do not need to create and manage tables in metadata in order to query data.
2.11. Apache Mahout
Mahout is open source framework for creating scalable machine learning algorithm and data mining library. Once data is stored in Hadoop HDFS, mahout provides the data science tools to automatically find meaningful patterns in those big data sets.
Algorithms of Mahout are:
- Clustering – Here it takes the item in particular class and organizes them into naturally occurring groups, such that item belonging to the same group are similar to each other.
- Collaborative filtering – It mines user behavior and makes product recommendations (e.g. Amazon recommendations)
- Classifications – It learns from existing categorization and then assigns unclassified items to the best category.
- Frequent pattern mining – It analyzes items in a group (e.g. items in a shopping cart or terms in query session) and then identifies which items typically appear together.
2.12. Apache Sqoop
Sqoop imports data from external sources into related Hadoop ecosystem components like HDFS, Hbase or Hive. It also exports data from Hadoop to other external sources. Sqoop works with relational databases such as teradata, Netezza, oracle, MySQL.

Apache Sqoop Diagram
Features of Apache Sqoop:
- Import sequential datasets from mainframe – Sqoop satisfies the growing need to move data from the mainframe to HDFS.
- Import direct to ORC files – Improves compression and light weight indexing and improve query performance.
- Parallel data transfer – For faster performance and optimal system utilization.
- Efficient data analysis – Improve efficiency of data analysis by combining structured data and unstructured data on a schema on reading data lake.
- Fast data copies – from an external system into Hadoop.
2.13. Apache Flume
Flume efficiently collects, aggregate and moves a large amount of data from its origin and sending it back to HDFS. It is fault tolerant and reliable mechanism. This Hadoop Ecosystem component allows the data flow from the source into Hadoop environment. It uses a simple extensible data model that allows for the online analytic application. Using Flume, we can get the data from multiple servers immediately into hadoop.

Apache Flume
Refer Flume Comprehensive Guide for more details
2.14. Ambari
Ambari, another Hadop ecosystem component, is a management platform for provisioning, managing, monitoring and securing apache Hadoop cluster. Hadoop management gets simpler as Ambari provide consistent, secure platform for operational control.
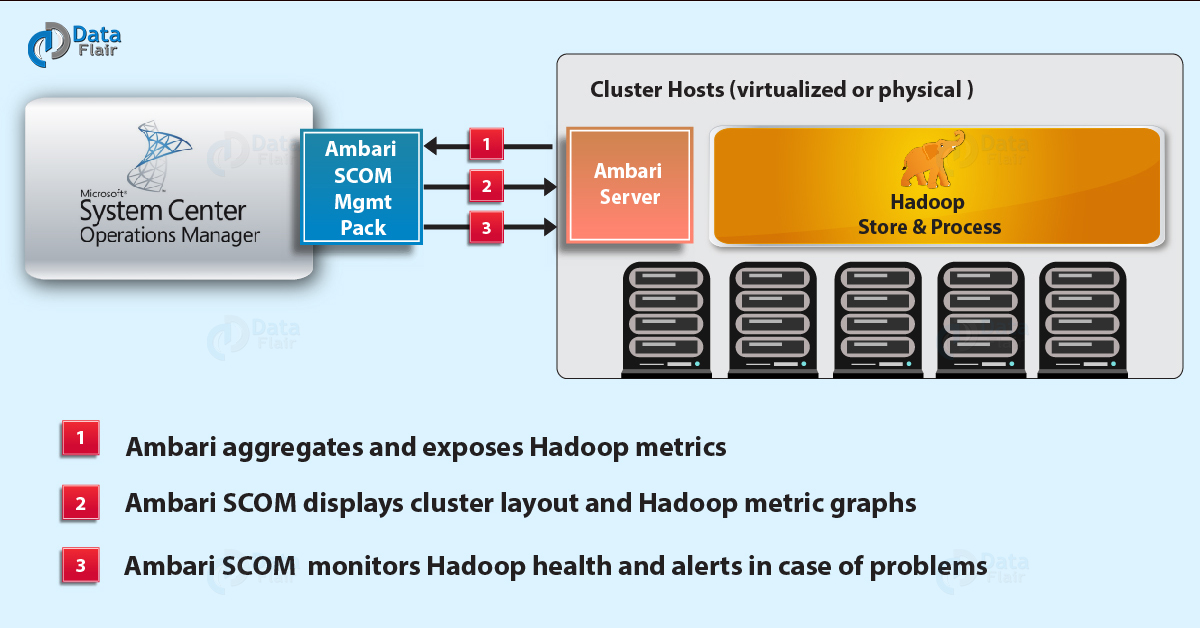
Ambari Diagram
Features of Ambari:
- Simplified installation, configuration, and management – Ambari easily and efficiently create and manage clusters at scale.
- Centralized security setup – Ambari reduce the complexity to administer and configure cluster security across the entire platform.
- Highly extensible and customizable – Ambari is highly extensible for bringing custom services under management.
- Full visibility into cluster health – Ambari ensures that the cluster is healthy and available with a holistic approach to monitoring.
2.15. Zookeeper
Apache Zookeeper is a centralized service and a Hadoop Ecosystem component for maintaining configuration information, naming, providing distributed synchronization, and providing group services. Zookeeper manages and coordinates a large cluster of machines.

ZooKeeper Diagram
Features of Zookeeper:
- Fast – Zookeeper is fast with workloads where reads to data are more common than writes. The ideal read/write ratio is 10:1.
- Ordered – Zookeeper maintains a record of all transactions.
2.16. Oozie
It is a workflow scheduler system for managing apache Hadoop jobs. Oozie combines multiple jobs sequentially into one logical unit of work. Oozie framework is fully integrated with apache Hadoop stack, YARN as an architecture center and supports Hadoop jobs for apache MapReduce, Pig, Hive, and Sqoop.
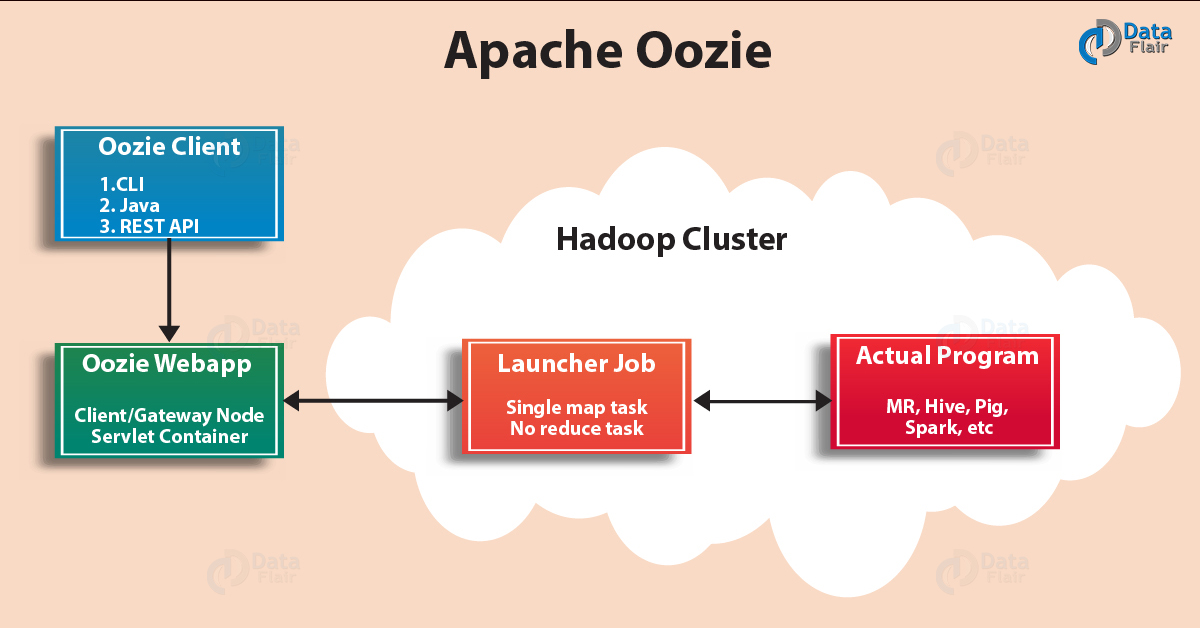
Oozie Diagram
In Oozie, users can create Directed Acyclic Graph of workflow, which can run in parallel and sequentially in Hadoop. Oozie is scalable and can manage timely execution of thousands of workflow in a Hadoop cluster. Oozie is very much flexible as well. One can easily start, stop, suspend and rerun jobs. It is even possible to skip a specific failed node or rerun it in Oozie.
There are two basic types of Oozie jobs:
- Oozie workflow – It is to store and run workflows composed of Hadoop jobs e.g., MapReduce, pig, Hive.
- Oozie Coordinator – It runs workflow jobs based on predefined schedules and availability of data.
This was all about Components of Hadoop Ecosystem
3. Conclusion: Components of Hadoop Ecosystem
We have covered all the Hadoop Ecosystem Components in detail. Hence these Hadoop ecosystem components empower Hadoop functionality. As you have learned the components of the Hadoop ecosystem, so refer Hadoop installation guide to use Hadoop functionality. If you like this blog or feel any query so please feel free to share with us.
See Also-
We work very hard to provide you quality material
Could you take 15 seconds and share your happy experience on Google





Super…very nice article
Hii Ashok,
It’s our pleasure that you like the “Hadoop Ecosystem and Components Tutorial”. as you enjoy reading this article, we are very much sure, you will like other Hadoop articles also which contains a lot of interesting topics. You must read them.
Thank you for visiting Data Flair.
where is spark its part of hadoop or what ??????????????????????
It was very good and nice to learn from this blog
Hii Sreeni,
Glad to read your review on this Hadoop Ecosystem Tutorial. If you enjoyed reading this blog, then you must go through our latest Hadoop article.
https://data-flair.training/blogs/hadoop-cluster/.
If you want to explore Hadoop Technology further, we recommend you to check the comparison and combination of Hadoop with different technologies like Kafka and HBase. This will definitely help you get ahead in Hadoop.
It’s very easy and understandable, who starts learning from scratch. Good work team. I have noted that there is a spell check error in Pig diagram(Last box Onput instead of Output)
WOW Perfect Splendid, Great article about Hadoop Architecture. Thanks
erripuk
you suck bro!!!