What is Hadoop Cluster | Hadoop Cluster Architecture
1. Hadoop Cluster
Today, we will start the Hadoop Cluster Tutorial. In this Tutorial, we will discuss Hadoop Cluster Architecture, diagram. Moreover, we will look at the Hadoop Cluster advantages and Hadoop Nodes configuration.
In simple terms, Cluster is a set of connected computers which work together as a single system. Similarly, the Hadoop cluster is just a computer cluster which we use for Handling huge volume of data distributedly.
So, let’s start the Hadoop Cluster Tutorial.
What is Hadoop Cluster | Hadoop Cluster Architecture
2. Hadoop Cluster Architecture
Basically, for the purpose of storing as well as analyzing huge amounts of unstructured data in a distributed computing environment, a special type of computational cluster is designed that what we call as Hadoop Clusters.
Though, whenever we talk about Hadoop Clusters, two main terms come up, they are cluster and node, so on defining them:
- A collection of nodes is what we call the cluster.
- A node is a point of intersection/connection within a network, ie a server
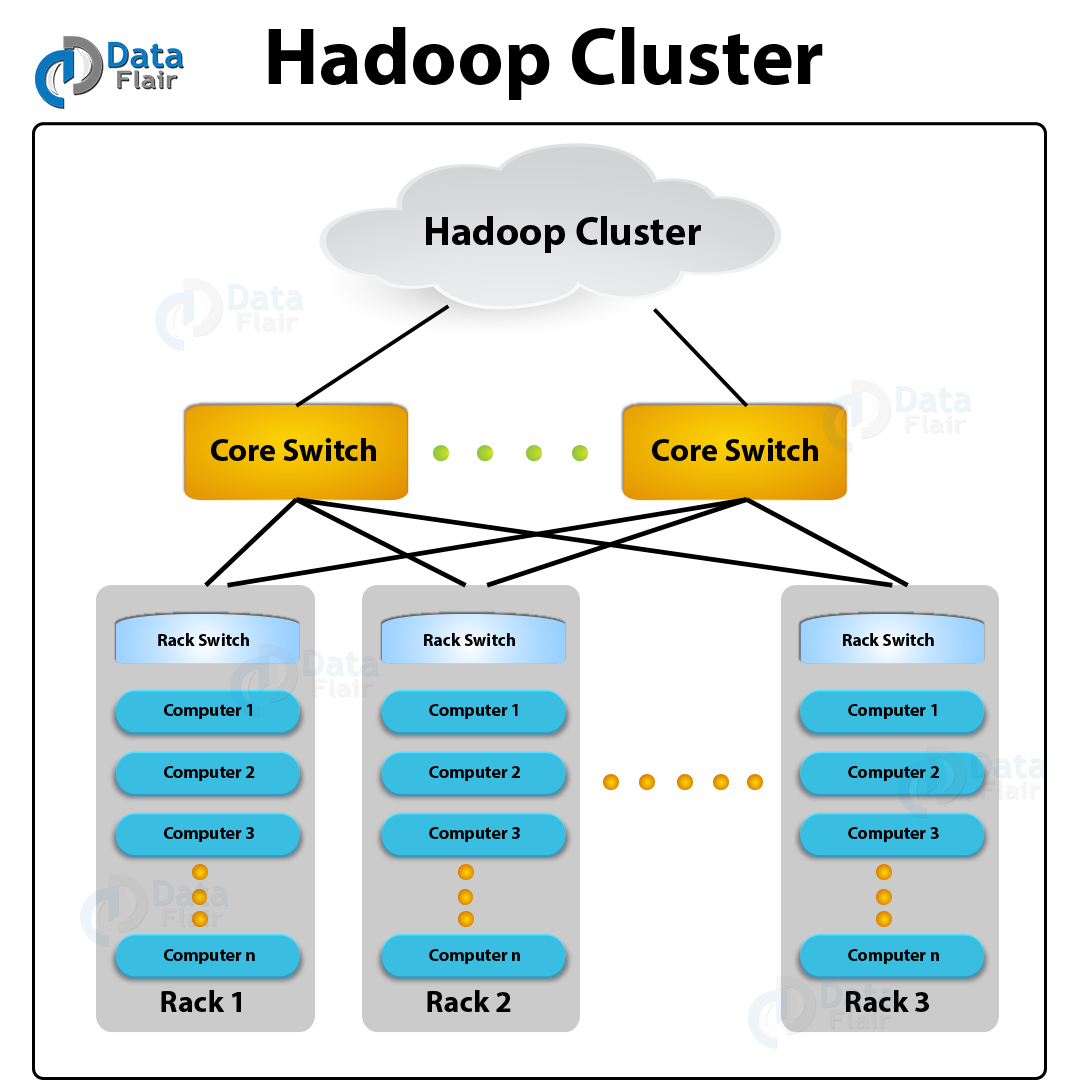
Hadoop Cluster Architecture
You must read set up for Cluster in Hadoop
There is nothing shared between the nodes in a Hadoop cluster except for the network which connects them (Hadoop follows shared-nothing architecture). This feature decreases the processing latency so the cluster-wide latency is minimized when there is a need to process queries on huge amounts of data.
In addition, Hadoop clusters have two types of machines, such as Master and Slave, where:
- Master: HDFS NameNode, YARN ResourceManager.
- Slaves: HDFS DataNodes, YARN NodeManagers.
However, it is recommended to separate the master and slave node, because:
- Task/application workloads on the slave nodes should be isolated from the masters.
- Slaves nodes are frequently decommissioned for maintenance.
Moreover, it is possible to scale out a Hadoop cluster. Here, Scaling means to add more nodes. That’s why we also call it linearly scalable. Hence, we get a corresponding boost in throughput, for every node we add.
Let’s have a look at Hadoop 2.x vs Hadoop 3.x
3. Datanode and Namenode
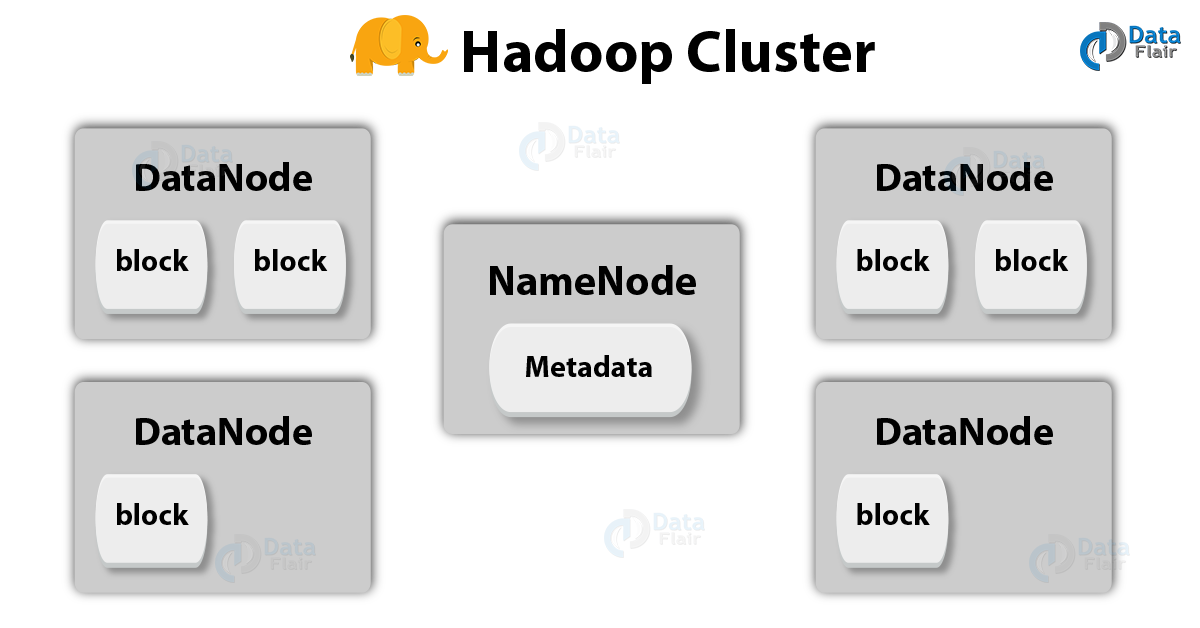
Hadoop Cluster – Datanode and Namenode
The NameNode is the HDFS master, which manages the file system namespace and regulates access to files by clients and also consults with DataNodes (HDFS slave) while copying data or running MapReduce operations. Whereas DataNode manages storage attached to the nodes that they run on, basically there are a number of DataNodes, that means one DataNode per slave in the cluster.
In other words, a node which knows where the files are to be found in hdfs are Namenode, and the node which have the data of the files are Datanodes.
Refer below image to understand its basic image:
4. Yarn
Yarn – Yet Another resource negotiator is the resource management layer of Hadoop. It permits diverse applications like real-time streaming, multiple data processing engines interactive SQL, data science as well as batch processing, to handle data which is stored in hdfs.
– What YARN Does
It is a Hadoop’s prerequisite which offers a central platform that brings security, and data governance tools, as well as resource management over Hadoop clusters.
Furthermore, it offers a consistent framework for writing data access applications that run in Hadoop, to ISVs as well as developers.
Also, it enhances a Hadoop compute cluster on the basis of several features, such as Compatibility, Scalability, Cluster Utilization, and Multi-tenancy.
Do you know about the Distributed cache in Hadoop
5. The Communication Protocols
For inter-node communication, Hadoop uses tcp ip. Basically, on top of the TCP/IP protocol, all HDFS communication protocols are layered and on the NameNode machine, a client establishes a connection to a configurable TCP port. Moreover, with the NameNode it talks the ClientProtocol. And, by using the DataNode Protocol, the DataNodes talk to the NameNode.
In addition, the abstraction Remote Procedure Call (RPC) wraps both the DataNode Protocol as well as the Client Protocol. Although, the NameNode never starts any RPCs, by design. Rather than that it only responds to RPC requests which are issued by DataNodes or clients.
6. Hadoop Nodes Configuration
However, by two types of important configuration files, Hadoop’s Java configuration is driven:
- Read-only default configuration : core-default.xml, hdfs-default.xml, yarn-default.xml and mapred-default.xml.
- Site-specific configuration : etc/hadoop/core-site.xml, etc/hadoop/hdfs-site.xml, etc/hadoop/yarn-site.xml and etc/hadoop/mapred-site.xml.
Moreover, by setting site-specific values via above files and etc/hadoop/hadoop-env.sh and etc/hadoop/yarn-env.sh, we can control the Hadoop scripts found in the bin/ directory of the distribution.
In addition, we need to configure the environment in which the Hadoop daemons execute and also the configuration parameters for the Hadoop daemons, in order to configure the Hadoop cluster. Where,
- HDFS daemons: NameNode, and DataNode.
- YARN daemons: ResourceManager, and NodeManager.
7. Advantages of a Hadoop Cluster
- The cluster helps in increasing the speed of the analysis process.
- It is inexpensive.
- These clusters are failure resilient.
- One more benefit to Hadoop clusters is “scalability”, it means Hadoop offers Scalable and flexible Data Storage. Here Scalability means, we can scale a Hadoop cluster by adding new servers to the cluster if needed.
- Hadoop Clusters deal with data from many sources and formats in a very quick, easy manner.
- It is possible to deploy Hadoop using a single-node installation, for evaluation purposes.
Let’s discuss Hadoop Limitations
8. Cluster management
There are several options for Hadoop Cluster management. One of them is Apache Ambari, this is used and promoted by Hortonworks and many more. As an advantage, we can manage more than one cluster at the same time by using Ambari. Another tool from various options for Hadoop Cluster management is Cloudera Manager. It is an end-to-end management tool for Apache Hadoop that offers complete control over Hadoop clusters. Moreover, it provides beneficial features to monitor performance as well as the health of the Hadoop cluster. Also, it permits us to deploy and operate a complete Hadoop stack in a very easy manner.
So, this was all in the Hadoop Clusters. Hope you like our explanation
9. Conclusion: Hadoop Clusters
Hence, we have seen the whole about Hadoop Cluster in detail. Moreover, in this Hadoop Cluster tutorial, we discussed Architecture of Cluster in Hadoop, its Components along with Hadoop Nodes Configuration in detail. Also, we discussed Hadoop Cluster Diagram for better understanding with the Hadoop. Still, if you have any doubt, ask in the comment tab. You can also share the experience of reading this blog through comments.
See also –
Install Hadoop 2.x in Distributed Mode
For reference
Your 15 seconds will encourage us to work even harder
Please share your happy experience on Google





Very good and solid article. Thank you.
Thank you Maitis for such a beautiful appreciation for Hadoop Cluster. We have a complete set of tutorials on Hadoop Ecosystem. Please refer them too.
Regards,
DataFlair