71 Data Science Interview Questions and Answers – Crack Technical Interview Now!
Machine Learning courses with 100+ Real-time projects Start Now!!
DataFlair has published a series of top data science interview questions and answers which contains 130+ questions of all the levels. Have a look –
- Data Science Interview Questions for Freshers
- Data Science Interview Questions for Intermediate Level
- Data Science Interview Questions for Experienced
This is the second part of the Data Science Interview Questions and Answers series. In our first part, we discussed some basic level questions which could be asked in your next interview, especially if you are a fresher in Data Science. Today, I am sharing the top 71 Data Science Interview Questions and Answers. This is the only part where you will get best scenario-based interview questions for data scientist interviews. Outline of the article –
- Python Data Science Interview Questions and Answers
- Scenario-based Data Science Interview Questions and Answers
- ML & Statistics Data Science Interview Questions and Answers
- General Data Science Interview Questions and Answers
- Behavior-based Data Science Interview Questions
A Data Science Interview is not a test of your knowledge, but your ability to do it at the right time.
Python Data Science Interview Questions
Every data science interview has many Python-related questions, so if you really want to crack your next data science interview, you need to master Python.
Q.1 What is a lambda expression in Python?
Ans. With the help of lambda expression, you can create an anonymous function. Unlike conventional functions, lambda functions occupy a single line of code. The basic syntax of a lambda function is –
lambda arguments: expression
An example of lambda function in Python data science is –
x = lambda a : a * 5
print(x(5))
We obtain the output of 25.
Q.2 How will you measure the Euclidean distance between the two arrays in numpy?
Ans. In order to measure the Euclidean distance between the two arrays, we will first initialize our two arrays, then we will use the linalg.norm() function provided by the numpy library. Here, numpy is imported as np.
a = np.array([1,2,3,4,5]) b = np.array([6,7,8,9,10]) # Solution e_dist = np.linalg.norm(a-b) e_dist 11.180339887498949
With data integrity, we can define the accuracy as well as the consistency of the data. This integrity is to be ensured over the entire life-cycle.
Q.3 How will you create an identity matrix using numpy?
Ans. In order to create the identity matrix with numpy, we will use the identity() function. Numpy is imported as np
np.identity(3)
We will obtain the output as –
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
Q.4 You had mentioned Python as one of the tools for solving data science problems, can you tell me the various libraries of Python that are used in Data Science?
Ans. Some of the important libraries of Python that are used in Data Science are –
- Numpy
- SciPy
- Pandas
- Matplotlib
- Keras
- TensorFlow
- Scikit-learn
To crack your next Data Science Interview, you need to learn these top Python Libraries now.
Q.5 How do you create a 1-D array in numpy?
Ans. You can create a 1-D array in numpy as follows:
x = np.array([1,2,3,4])
Where numpy is imported as np
Q.6 What function of numpy will you use to find maximum value from each row in a 2D numpy array?
Ans. In order to find the maximum value from each row in a 2D numpy array, we will use the amax() function as follows –
np.amax(input, axis=1)
Where numpy is imported as np and input is the input array.
Q.7 Given two lists [1,2,3,4,5] and [6,7,8], you have to merge the list into a single dimension. How will you achieve this?
Ans. In order to merge the two lists into a single list, we will concatenate the two lists as follows –
list1 + list2
We will obtain the output as – [1, 2, 3, 4, 5, 6, 7, 8]
Q.8 How will you create an identity matrix using numpy?
Ans. In order to create the identity matrix with numpy, we will use the identity() function. Numpy is imported as np
np.identity(3)
We will obtain the output as –
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
Q.9 How to add a border that is filled with 0s around an existing array?
Ans. In order to add a border to an array that is filled with 0s, we first make an array Z and initialize it with zeroes. We first import numpy as np.
Z = np.ones((5,5)) Then, we perform padding on it with the help of pad() function. Z = np.pad(Z, pad_width=1, mode='constant', constant_values=0) print(Z)
Q.10 Consider a (5,6,7) shape array, what is the index (x,y,z) of the 50th element?
Ans.
print(np.unravel_index(50,(5,6,7)))
Q.11 How will you multiply a 4×3 matrix by a 3×2 matrix ?
Ans. There are two ways to do this. The first method is for the versions of Python that are older than 3.5 –
Z = np.dot(np.ones((4,3)), np.ones((3,2)))
print(Z)
array([[3., 3.],
[3., 3.],
[3., 3.],
[3., 3.]])
The second method is for Python version > 3.5,
Z = np.ones((4,3)) @ np.ones((3,2))
Note: This is not enough, a lot of NumPy related questions are asked in the Data Science Interview. Therefore DataFlair has published Python NumPy Tutorial – An A to Z guide that will surely help you.
Scenario-based Data Science Interview Questions and Answers
Below are 20 scenario or situation based interview questions provided by experts of Data Science. If you want to take a step ahead among all the aspirants then practice the below questions sincerely.
Q.12 Suppose that you have to train your neural networks over a dataset of 20 GB. You have a RAM of 3 GB. How will you resolve this problem of training large data?
Ans.
- We will train our neural network with limited memory as follows:
- We first load the entire data in our numpy array.
- Then we obtain the data through passing the index to the numpy array.
- We then pass this data to our neural network and train it in small batches.
You can’t afford to miss Neural Network for data science interview preparation. Learn it through the DataFlair’s latest guide on Neural Networks for Data Science Interview.
Q.13 If through training all the features in the dataset, an accuracy of 100% is obtained but with the validation set, the accuracy score is 75%. What should be looked out for?
Ans. If the training accuracy of 100% is obtained, then a verification of overfitting is required in our model.
Q.14 Suppose that you are training your machine learning model on the text data. The document matrix that is created consists of more than 200K documents. What techniques can you use to reduce the dimensions of the data?
Ans. In order to reduce the dimensions of our data, we can use any one of the following three techniques:
- Latent Semantic Indexing
- Latent Dirichlet Allocation
- Keyword Normalization
Q.15 In a survey conducted, the average height was 164cm with a standard deviation of 15cm. If Alex had a z-score of 1.30, what will be his height?
Ans. Using the formula, X= μ+Zσ, we determine that X = 164 + 1.30*15 = 183.5. Therefore, the height of Alex is 183.50 cm.
Q.16 While reading the file ‘file.csv’, you get the following error:
Traceback (most recent call last):
File “<input>”, line 1, in<module>
UnicodeEncodeError: ‘ascii’ codec can’t encode character.
How will you correct this error?
Ans. In order to correct this error, we will read the csv with the utf-8 encoding. pd.read_csv(“‘file.csv”, encoding=’utf-8′)
Q.17 Assume that you have to perform clustering analysis. The first step towards any data science problem including clustering is data cleaning. However, in this case of clustering analysis you have a lesser number of data points. What strategy would you use while performing data cleaning prior to the clustering operation?
Ans. Capping and Flooring would be the most appropriate strategy for performing data cleaning prior to the clustering operation.
Q.18 Assume that you are given a data science problem that involves dimensionality reduction as a part of its pre-processing technique. You are required to reduce the original data to k dimensions using PCA and then use them as projections for the main features. What value of k would you select – high or low to decrease the regularization?
Ans. In order to preserve the characteristics of our data, the value of k will be high, therefore, leading to less regularization.
Q.19 For a given dataset, you decide to use SVM as the main classifier. You select RBF as your kernel. What would be the optimum gamma value that would allow you to capture the features of the dataset really well?
Ans. In SVM, the gamma parameter denotes the influence of the points that are either near or far away from the dividing hyperplane. When the gamma is high, the model will be able to capture the shape of the data quite well.
Master SVM concepts with DataFlairs best ever tutorial on Support Vector Machines
Q.20 Suppose that you have to perform transformation operation on an image. The operation is a basic rotation. The point to be rotated has the coordinates (2,0) to a new coordinate of (0,2). How will you perform this operation?
Ans. In order to rotate the image from the point (2,0) to the point (0,2), we will perform matrix multiplication where [2,0] will be represented as a vector that will be multiplied with the matrix [ [0,-1] , [1,0] ]. As a result of their dot product, we will obtain the new coordinate point of (0,2).
Q.21 Assume that while working in the field of image processing. You have to deploy Finite Difference Filters. However, these filters are very vulnerable to additional noise. What will you do to reduce the noise to the point of minimal distortion?
Ans. In order to reduce the noise to the point of minimal distortion while using the Finite-Difference Filters, we will make use of Smoothing. Smoothing is used in image processing to reduce noise that might be present in an image which can also be used to produce an image that is less pixelated.
Q.22 Assume that for a binary classification challenge, we have a fully connected architecture comprising of a single hidden layer with three neurons and a single output neuron. The structure of the input and output layer is as follows –
Input dataset: [ [0,1,1,0] , [1,1,0,0] , [1,0,0,1], [1,1,0,0] ]
Output: [ [0] , [1] , [0] ]
For performing model training, the weights have been initialized for both the input and output layer as 1. Based on this, will the model be able to learn from the patterns?
Ans. No. Since you have initialized the weights with 1, all the neurons will try to do the same thing as they will never converge.
Q.23 Suppose that you are training your Artificial Neural Network. After you have created your model, you evaluate it. However, during model evaluation, you find out that the training loss/validation loss remains constant. What could be the reason behind this constant figure loss between training and validation test?
Ans. There are two important reasons that would contribute towards the training/validation loss stagnation. Firstly, the architecture of the model is not properly defined. Secondly, the input data has noisy characteristics.
Learn everything about Machine Learning and its Algorithms
Q.24 You have a data science project assignment where you have to deal with 1000 columns and around 1 million rows. The objective of the problem is to carry out classification. You are required to reduce the dimensions of this data in order to reduce the model computation time. Furthermore, your machine suffers from memory constraints. What will you do in this situation?
Ans. Considering memory constraints, developing a machine learning model would prove to be a laborious task. However, one can carry this out with the following steps:
- Since we are low on our RAM, we can preserve the memory by closing the other miscellaneous applications that we do not require.
- We will then perform sampling on our data randomly. This sample will be a much smaller version of the bigger dataset.
- We will then reduce the dimensionality by removing the correlated variables. Furthermore, using PCA, we will select those features that can explain maximum variance in our data.
- We will further create a linear model using stochastic gradient descent.
- Using domain knowledge, we will further drop the predictor variables that do not have much effect on the response variable. This will further lead to a reduction in the number of dimensions.
Q.25 Your company has assigned you a new project that involves assisting a food delivery company to prevent losses from occurring. The main reason behind the loss is that the food delivery team is not able to deliver food to their customers in the stipulated time-frame. As a part of their policy, they are then required to deliver food without any charge. This is resulting in losses on the company’s part. How can you fix this problem using machine learning algorithm?
Ans. Considering that this question does not have any pattern or required data, it does not qualify for a machine learning problem. It is clearly a route optimization problem that will require a different set of algorithms.
Q.26 Suppose that you have been assigned the task of analyzing text data that is obtained from the news sentences that are structured. Now, you have to detect noun phrases, verb phrases as well as perform subject and object detection. Which grammar-based text parsing technique would you use in this scenario?
Ans. In this scenario, we will make use of Dependency and Constituent Parsing Extraction techniques to retrieve relations from the textual data.
Q.27 You are working on a Data Science problem in which you have spent a considerable amount of time in data preprocessing and analysis. You are now required to implement a machine learning model that would provide you with a high accuracy. Knowing that boosting algorithms are coveted by data scientists for their high accuracy, you decide to develop five Gradient Boosting Models. However, the models do not surpass even the standard benchmark score. You then create an ensemble of these five models but you do not succeed. Where exactly did you go wrong?
Ans. Ensemble Learning involves the notion of combining weak learners to form strong learners. The underlying ensemble models only provide accurate results when they are uncorrelated. If the ensemble models in the scenario above do not yield an accurate output then we conclude that the models are correlated.
Q.28 Suppose that you are working on neural networks where you have to utilise an activation function in its hidden layers. The output that we obtain is -0.0002. What type of activation could have been used in order to obtain such type of an output?
Ans. Since, the output obtained is -0.0002 which is between -1 and 1, the activation function which has been used in the hidden layer is tanh.
Wait! It is time to revise your neural network concepts.
Q.29 Assume that you are working at DataFlair and you have been assigned the task of developing a machine learning algorithm that predicts the number of views an article attracts. During the process of analysis, you include important features such as author name, number of articles written by the author in the past etc. What would be the ideal evaluation metric that you would use in this scenario?
Ans. Number of views that an article attracts on the website is a continuous target variable which is a part of the regression problem. Therefore, we will make use of mean squared error as our primary evaluation metric.
Q.30 Assume that you are working with categorical features wherein you do not know about the distribution of the categorical variable present in the validation set. Now, you wish to apply one hot encoding on the categorical features. What are the various challenges that you can encounter once you have applied one hot encoding on the categorical variable belonging to the train set?
Ans. Applying One Hot Encoding to encode the categories present in the test set but not in the train set, will not involve all the categories of the categorical variable present in the dataset. Secondly, there could be a possible mismatch between the frequency distribution of the categories present in the training set and the validation set.
Q.31 Suppose that you have to work with the data present on social media. After you have retrieved the data have to develop a model that suggests the hashtags to the user. How will you carry this out?
Ans. We can carry out Topic Modeling to extract significant words present in the corpus. To capture the top n-gram words and their combinations. And, for learning repeating contexts in the sentence we train a word2vec model.
Machine Learning and Statistics Data Science Interview Questions and Answers
The next important part of our data science interview questions and answers is mathematics, ML and Statistics. Without having the knowledge of these 3 you cannot become a data scientist. For most of the candidates, statistics prove as a tough part. So, this is something that can help you to score well in your data science interview. My tip is to thoroughly learn all the formulas and definitions related to it.
Q.32 Can you name the type of biases that occur in machine learning?
Ans. There are four main types of biases that occur while building machine learning algorithms –
- Sample Bias
- Prejudice Bias
- Measurement Bias
- Algorithm Bias
Q.33 How is skewness different from kurtosis?
Ans. In data science, the general meaning of skewness is basically to determine the imbalance. In statistics, skewness is a measure of asymmetry in the distribution of data. Ideally, data is normally distributed, meaning that both the left and right tails are equidistant from the center of the distribution. In this case, the skewness is 0. However, a distribution exhibits negative skewness if the left tail is longer than the right one. And, the distribution exhibits positive skewness if the right tail is longer than the left one.
In case of kurtosis, we measure the pointedness of the peak of distribution. The ideal kurtosis or the kurtosis of a normal distribution is 3. If the kurtosis of the tail data exceeds 3, then we say that the distributions possess heavy tails. And, if the kurtosis is less than 3, we say that the distributions have thin tails.
Q.34 In a univariate linear least squares regression, what is the relationship between the correlation coefficient and coefficient of determination?
Ans. The relationship between the correlation coefficient and coefficient of determination in a univariate linear least squares regression is that the latter is a result of the square of the former. R squared tells us about the coefficient of determination and it provides a magnitude of variability of the dependent variable through the independent one.
If there is any concept in Machine learning that you have missed, DataFlair came with the complete Machine Learning Tutorial Library. Save the page and learn everything for free at any time.
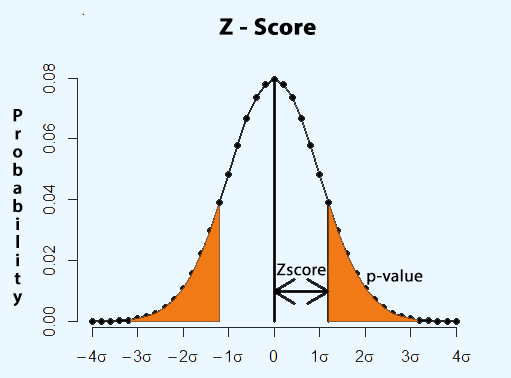
Q.35 What is z-score?
Ans. Z-score, also known as the standard score is the number of standard deviations that the data-point is from the mean. It measures how many standard deviations below or above the population mean is. Z-score ranges from -3 and goes up till +3 standard deviations.
Q.36 What is the formula of Logistic Regression?
Ans. The formula of Logistic Regression is:
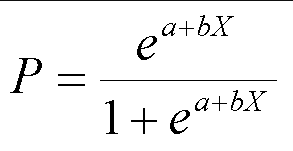
Where P represents the probability, e is the base of natural logarithms and a and b are the parameters of the logistic regression model.
Do you know – There is no single Data Science Interview where the question from logistic regression is not asked. What are you waiting for? Start learning logistic regression with the best ever guide.
Q.37 For tuning hyperparameters of your machine learning model, what will be the ideal seed?
Ans. There is no fixed value for the seed and no ideal value. The seed is initialized randomly in order to tune the hyperparameters of the machine learning model.
Q.38 Explain the difference between Eigenvalue and Eigenvectors.
Ans. While the eigenvalues are the values that are associated with the degree of linear transformation, eigenvectors of a non-singular matrix are associated with its linear transformations that are calculated with correlation or covariance matrix functions.
Q.39 Is it true that Pearson captures the monotonic behavior of the relation between the two variables whereas Spearman captures how linearly dependent the two variables are?
Ans. No. It is actually the opposite. Pearson evaluates the linear relationship between the two variables whereas Spearman evaluates the monotonic behavior that the two variables share in a relationship.
Q.40 How is standard deviation affected by the outliers?
In the formula for standard deviation –
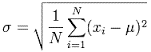
The variation in the input value of x, that is, a variation in its value between high and low would adversely affect the standard deviation and its value would be farther away from the mean. Therefore, we conclude that outliers will have an effect on the standard deviation.
Q.41 How will you create a decision tree?
Ans.

- If both positive and negative examples are present, we select the attribute for splitting them.
- If examples are positive, answer yes. Otherwise, answer no.
- When there are no observed examples then we select a default based on majority classification at the parent.
- If no attributes are remaining, then both the positive and negative examples are present. This means that there are no sufficient features for classification or an error is present in the examples.
Master the concept of decision trees and answer all the Data Science Interview Questions related to it confidently.
Q.42 What is regularization? How is it useful?
Ans. Regularizations are the techniques for reducing the error by fitting a function on a training set in an appropriate manner to avoid overfitting.
While training the model, there is a high chance of the model learning noise or the data-points that do not represent any property of your true data. This can lead to overfitting. Therefore, in order to minimize this form of error, we use regularization in our machine learning models.
Q.43 Given a linear equation: 2x + 8 = y for the following data-points:
| X | Y |
| 5 | 18 |
| 6 | 20 |
| 7 | 22 |
| 8 | 24 |
| 9 | 26 |
What will be the corresponding Mean Absolute Error?
Ans. In order to calculate the mean value error, we first calculate the value of y as per the given linear equation. Then we calculate the absolute error with respect to the output value of y. In the end, we find the average of the errors which is our Mean Absolute Error.
| X | Y | 2x + 8 = y | Absolute Error |
| 5 | 10 | 18 | 8 |
| 6 | 21 | 20 | 1 |
| 7 | 26 | 22 | 4 |
| 8 | 19 | 24 | 5 |
| 9 | 30 | 26 | 4 |
Mean Error 4.4
General Data Science Interview Questions and Answers
Q.44 How is conditional random field different from hidden markov models?
Ans. Conditional Random Fields (CRMs) are discriminative in nature whereas Hidden Markov Models (HMMs) are generative models.
Q.45 What does the cost parameter in SVM stand for?
Ans. Cost (C) Parameter in SVM decides how well the data should with the model. Cost Parameter is used for adjusting the hardness or softness of your large margin classification. With low cost, we make use of a smooth decision surface whereas to classify more points we make use of the higher cost.
Q.46 Why is gradient descent stochastic in nature?
Ans. The term stochastic means random probability. Therefore, in the case of stochastic gradient descent, the samples are selected at random instead of taking the whole in a single iteration.
Q.47 How will you subtract means of each row of matrix?
Ans. In order to subtract the means of each row of a matrix, we will use the mean() function as follows –
X = np.random.rand(5, 10)
Y = X – X.mean(axis=1, keepdims=True)
Q.48 What do you mean by the law of large numbers?
Ans. According to the law of large numbers, the frequency of occurrence of events that possess the same likelihood are evened out after they undergo a significant number of trials.
Q.49 Explain L1 and L2 Regularization
Both L1 and L2 regularizations are used to avoid overfitting in the model. L1 regularization or Lasso and L2 regularization or Ridge Regularization remove features from our model. L1 regularization, however, is more tolerant to outliers. Therefore L1 regularization is much better at handling noisy data.
Q.50 What do the Alpha and Beta Hyperparameter stand for in the Latent Dirichlet Allocation Model for text classification?
Ans. In the Latent Dirichlet Model for text classification, Alpha represents the number of topics within the document and Beta stands for the number of terms occurring within the topic.
Q.51 Is it true that the LogLoss evaluation metric can possess negative values?
Ans. No. Log Loss evaluation metric cannot possess negative values.
Q.52 What is the formula of Stochastic Gradient Descent?
The formula for Stochastic Gradient Descent is as follows:
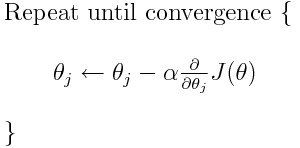
Q.53 Explain TF/IDF Vectorization
TF/IDF stands for Term Frequency/Inverse Document Frequency. It is used for information retrieval and mining. It is used as a weighing factor to find the importance of word to a document. This importance is proportional to, and increases with the number of times a word occurs in the document but is offset by the frequency of the word in a corpus.
Q.54 What is Softmax Function? What is the formula of Softmax Normalization?
Ans. Softmax Function is used for normalizing the input into a probability distribution over the output classes. Following is the formula for the Softmax Normalization:
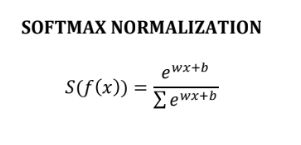
Behavior-based Data Science Interview Questions
Bu this, we mean the general questions that could be based on your past experience, behavior, about the company, about the role, your family background, etc. Must remember these type of questions has a good weightage in data science interview. This type of questions can be asked indirectly. It is recommended to practice them twice or thrice before attempting for the interview, it will surely boost your confidence.
Q.1 Where do you see yourself in X years?
Q.2 Why did you choose this role?
Q.3 Which was the most challenging project you did? Explain it.
Q.4 How will you manage a conflict situation with your colleague?
Q.5 What would you prefer – working in a large team, small team, or individually?
Q.6 If you encountered a tedious or boring task how will you motivate yourself to complete it?
Q.7 Tell me about one innovative solution that you have developed in the previous job that you are proud of.
Q.8 What can your hobbies tell me that resume can’t?
Q.9 Tell me about your top 5 predictions for the next 15 years?
Q.10 Tell me your likes and dislikes about the previous position.
Q.11 How will you identify a barrier that can affect your performance?
Q.12 What are your motivations for working with our company?
Q.13 Tell me about a challenging work situation and how you overcame it?
Q.14 Tell me about the situation when you were dealing with the coworkers and patience proves as a strength there.
Q.15 Is there any case when you changed someone’s opinion?
Q.16 What would you do if your senior/manager rejected all your ideas?
Q.17 If you were assigned multiple tasks at the same time, how would you organize yourself to produce quality work under tight deadlines?
Answering the above data science interview questions won’t work alone. You need to learn the talent of correctly framing the answers for data science interview questions. For that, you can check DataFlair’s Data Science Interview Preparation Guide designed by experts.
Be so good in an interview that they can’t ignore you!
Summary
Superb, you have read all the data science interview questions and answers. Tell me one thing, how many questions you have solved by yourself?
As the industry is booming and companies are demanding more data scientists. This can increase the level of interview. Therefore, DataFlair is trying to prepare you for the advanced level. If there is any answer in which you are facing difficulty you can comment below, we will surely help you.
Have you faced any Data Science Interview yet? Do share your experience with us.
If there is any topic which you want to prepare for data science interview, you can visit DataFlair’s Data Science tutorial Library.
Keep learning, keep succeeding. All the very best!👍
We work very hard to provide you quality material
Could you take 15 seconds and share your happy experience on Google





Q39 : it is Spearman correlation instead of spearson
Thank you, nice stuff for preparing the interview.
Can you come along some more scenario based questions which include real life data based on how to increase the sales of company for any product based company, or how will you measure the advertisement done for the organization for various platform and how can you improve the sales using the analytics.
Hello Prasun,
We will surely update more scenario-based questions in our article, keep visiting DataFlair for regular updates.
Thank you for sharing this information who has a career stating data science is very helpful for better understanding.
Thank you for all the information. I really got impressed about your website, it contains way more useful information than any others.
Will looking forward another posts as well from South Korea. Thank you again!
Hi, Thank you for the knowledge. I have given multiple interviews in DS. But I am working now in a different field. Though I have answered technical questions correct, I can’t answer questions related to deployment, processes in our organization, etc.
Can you please guide me regarding the same.