How Data Science became the Trump Card for Flipkart?
Machine Learning courses with 100+ Real-time projects Start Now!!
From handling bookmarks to handling multi-billion dollar company Flipkart has come a long way.
After Walmart’s acquisition for $16 billion(world’s largest e-commerce deal) as an Indian, I feel sad and disheartened and you should too. I guess a lot of writers will quit their day jobs to pursue their passion for engineering(#PunIntended :p).
Before exploring the case study – Data Science at Flipkart, let’s talk a little about Flipkart.
Flipkart is India’s largest e-commerce marketplace. It has a registered customer base of over 100 million. It was started 12 years ago and it offers over 80 million products across 80+ categories.
Starting from Smartphones, Books, Media, Consumer Electronics, Furniture to fashion and Lifestyle it offers everything in one (Two-Three) clicks. It was launched in October 2007. Flipkart is known for its path-breaking services like Cash on Delivery, No cost EMI and 10-day Replacement Policy.
It was the pioneer in offering services like In-a-Day Guarantee (65 cities) and Same-Day-Guarantee (13 cities) at scale. With over 1,00,000 registered sellers, it has redefined the way brands and MSME’s do business online.
Data Science at Flipkart
The company has a very flat structure within the Data Science team, which enables it to focus on excellence and create a deep sense of ownership. Also being a young team they are able to democratize the process of problem selection.
Here are some of the signals which they incorporate in their ranking function to help achieve their goals –
Recommendation System
Flipkart is nothing without Data Science, the recommendation system helps in providing the highest conversion rates. It is also a significant contributor to the company’s units and revenue.
You can check the Data Science and Netflix case study to know more about the recommendation system.
But, this doesn’t end here because a person will not just purchase a product based on similar products or recommended products. There is much more to it.
Product Quality
They ensure a check on quality by having a check on the material quality- It should be good and durable. Is the seller good? What is the feedback from the existing customers?
To keep the users trust in them, they ensure that they are not compromising with the quality and for that, they show products that are of higher quality on top of the recommended list. By doing this, the trust factor remains intact and the users get quality products.
Performance
To ensure that the users buy good performance and popular product, they have added it in their ranking system. This provides mutual benefit to them. The user makes the buying decision and the company gets more loyal customers who trust on the performance of the products.
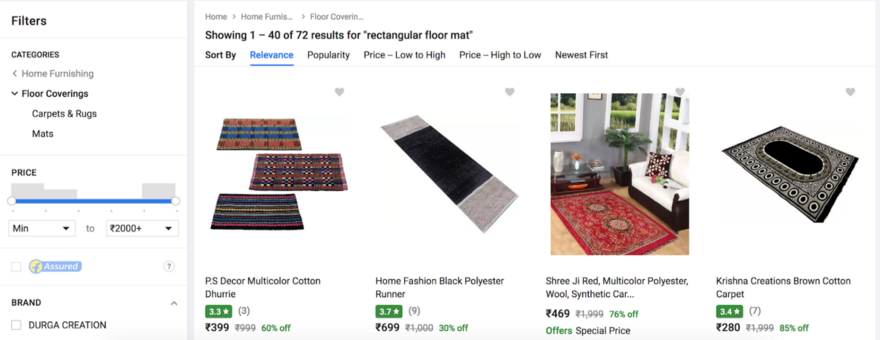
Source: Flipkart
The page of Flipkart has a set of Filters on the left pane displaying Categories, Price, Brand, Customer ratings, Offers, Discount, Color, and Availability. The user can select the criteria in the filters and view only those products that fit into their requirement.
The Problems that Flipkart faces are:
- Product discovery along with personalization and intent modeling
- Demand shaping and planning
- Heterogeneous networks for consumer, product & seller interactions
- Customer insights
- Catalog enhancement and product insights
- Customer emotion detection and right response matching
- Fulfillment automation
- Optimization of last mile delivery
Hope you enjoyed reading the above case studies. Now, let’s come to the topic again, how a product goes through three stages before a consumer makes the buying decision. The stages are:
- Pre-processing
- Intent understanding
- Ranking
From the consumer’s point of view, if I was searching for an earphone here (This will be my pre-processing stage).
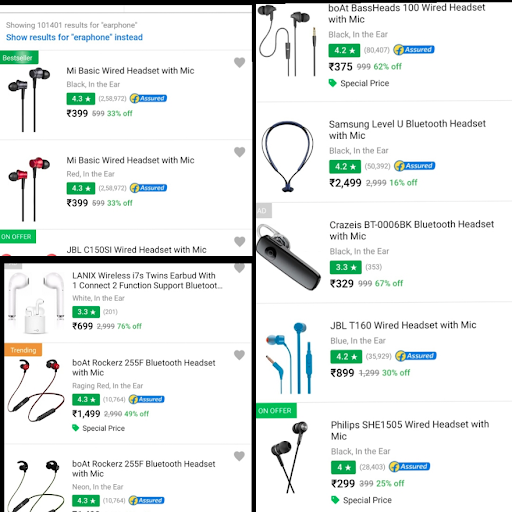
My thought (Intent) behind the purchase of an earphone was to get one which I can use at the gym. Here Flipkart gave me several options with different features:
- Wired Headset with Mic
- Level U Bluetooth headset with Mic
- Wireless Twin Earbud etc.
At this point of time Data Science plays a crucial part, for mapping query to the Store it uses three ways:
- Classic Statistical Approach
- Supervisory Approach
- Supervisory++ Approach
Classic Statistical Approach
In Layman’s language, Classic Statistical Approach to Store Mapping helps is searching the baseline system for the products that the users clicked on.
The aggregation on the ‘Click’ data provides a ‘Confidence Measure’ showing the number of times that users clicked on a product for the same search query and hence the store mapping happens almost instantly.
This approach largely depends on the data and works well with categories that are common, popular, and well-known among the users. A product belonging to a niche category may not have a lot of query data and hence, the store to query mapping may be less probable in such corner cases.
We identified the following challenges with this approach:
- Works on the exact query
- Memorizes the query allowing no room for generalization
- Lacks query volume or click data in a niche or unpopular vertical
Supervisory Approach to Store Mapping
The company uses L1 or leaf level store identification. In this, a query can come in a very general way, for e.g: Avengers: Endgame. Now a fan of the movie/characters is looking for the Endgame printed products.
So, the e-tailer has varied options available for the same and can accommodate 10s categories for it. The category options can be a poster for room, mobile cover, bottles, pencil box, bedsheets, books. etc.
Supervisory ++ Approach to Store Mapping
This is used for efficient text classification. The labels are fewer than the catalog data.
For a reduced run time, the company uses the Hierarchical Softmax function which speeds up the classification based on the code optimization. It provides for the most and least frequently used classes.
It is possible that a user might search for a product without adding specifications or filters. Let us take an example where the user has searched for souls.
The user hasn’t specified anything except this word in his search but because of store mapping method results can be generated. The search results could be attached to about 40% of the products which relates to the word.
Conclusion
After learning all this we can conclude that Data science has a lot of potential and still out of which a lot is unexplored. It is definitely The Sexiest Job of the 21st Century.
Now, the thing which is of major concern here is that can Flipkart beat Amazon or not by using Data Science or will Reliance revolutionize everything and take the ball in its court.
Flipkart uses smart algorithms to suggest products. If someone buys a phone, Flipkart may show cases, chargers, or screen guards. This helps increase sales and improve the shopping experience for users.
It also uses data to detect fraud, improve delivery times, and plan discounts during big sales like Big Billion Days. Machine learning models track customer behavior and market trends to keep Flipkart ahead in India’s e-commerce race.
Time will tell whether right moves were made by Flipkart or not, all we can do is hope for the best and shop till we satisfy our (never-ending) quest!
Hope you loved the article. Please mention your thoughts about Data Science at Flipkart through comments.
You give me 15 seconds I promise you best tutorials
Please share your happy experience on Google




