What is Data Science? A Complete Data Science Tutorial for Beginners
Machine Learning courses with 100+ Real-time projects Start Now!!
Data Science has become one of the most demanded jobs of the 21st century. It has become a buzzword that almost everyone talks about these days.
But what is Data Science? In this article, we will demystify Data Science, the role of a Data Scientist and have a look at the tools required to master Data Science. Do not forget to check the best data science online course.
So, let’s start Data Science Tutorial.
What is Data Science?
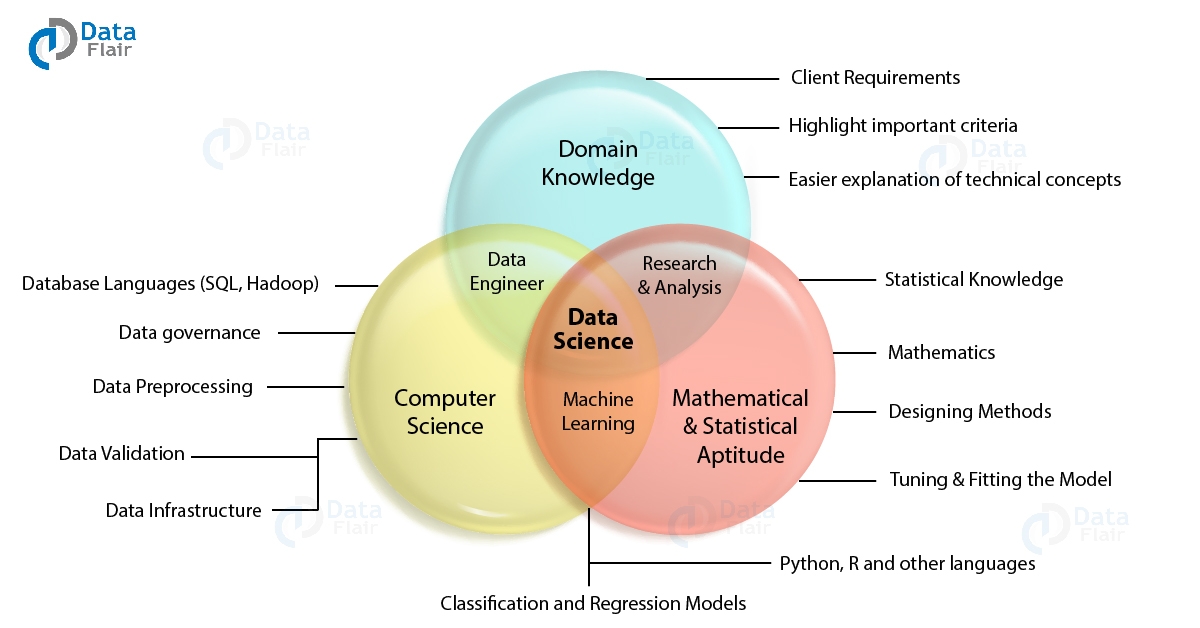
Data Science is a field that uses tools, coding, and thinking skills to find answers from data. In simple words: Data Science is the art and science of turning raw data into useful insights. It brings together three major areas:
- Math & Statistics – to understand data patterns.
- Computer Programming – to clean, organize, and process data.
- Business or Domain Knowledge – to ask the right questions and use results in real life.
With the emergence of new technologies, there has been an exponential increase in data. This has created an opportunity to analyze and derive meaningful insights from data.
It requires special expertise of a ‘Data Scientist’ who can use various statistical & machine learning tools to understand and analyze data. A Data Scientist, specializing in Data Science, not only analyzes the data but also uses machine learning algorithms to predict future occurrences of an event.
Therefore, we can understand Data Science as a field that deals with data processing, analysis, and extraction of insights from the data using various statistical methods and computer algorithms. It is a multidisciplinary field that combines mathematics, statistics, and computer science.
Why Data Science?
So, after knowing what exactly Data Science is, you must explore why Data Science is important. So, data has become the fuel of industries. It is the new electricity. Companies require data to function, grow and improve their businesses.
Data Scientists deal with the data in order to assist companies in making proper decisions. The data-driven approach undertaken by the companies with the help of Data Scientists who analyze a large amount of data to derive meaningful insights.
These insights will be helpful for the companies who wish to analyze themselves and their performance in the market. Other than commercial industries, healthcare industries also use Data Science.
Where the technology is in huge demand to recognize microscopic tumors and deformities at an early stage of diagnosis.
The number of roles for Data Scientists has grown by 650% since 2012. About 11.5 Million jobs will be created by 2026 according to the U.S. Bureau of Labor Statistics.
Also, the job of Data Scientist ranks among top emerging jobs on Linkedin. All the statistics point towards the growing demand for Data Scientists.
Role of a Data Scientist
You might want to know who is a Data Scientist and what are his/her roles in different fields. A Data Scientist deals with both unstructured and structured data.
The unstructured data is present in a raw format that requires extensive data pre-processing, cleaning and organization in order to impart a meaningful structure to a dataset.
The Data Scientist then investigates this organized data and analyzes it thoroughly to derive information from it using various statistical methodologies. We use these statistical methods to describe, visualize and hypothesize information from the data.
Then with the usage of advanced machine learning algorithms, the data scientist predicts the occurrence of events and takes data-driven decisions.
A Data Scientist deploys vast arrays of tools and practices to recognize redundant patterns within the data. These tools range from SQL, Hadoop to Weka, R, and Python.
Data Scientists usually act as consultants employed by companies where they participate in various decision-making processes and creation of strategies. In other words, Data Scientists use meaningful insights from data to assist companies in taking smarter business decisions.
For example – Companies like Netflix, Google and Amazon are using Data Science to develop powerful recommendation systems for their users. Similarly, various financial companies are using predictive analytics and forecasting methods to predict stock prices.
Data Science has helped to create smarter systems that can take autonomous decisions based on historical datasets.
Through its assimilation with emerging technologies like Computer Vision, Natural Language Processing and Reinforcement Learning, it has manifested itself to form a greater picture of Artificial Intelligence.
Solving Problems with Data Science
When solving a real-world problem with Data Science, the first step towards solving it starts with Data Cleaning and Preprocessing. When a Data Scientist is provided with a dataset, it may be in an unstructured format with various inconsistencies.
Organizing the data and removing erroneous information makes it easier to analyze and draw insights. This process involves the removal of redundant data, the transformation of data in a prescribed format, handling missing values etc.
A Data Scientist analyzes the data through various statistical procedures. In particular, two types of procedures used are:
- Descriptive Statistics
- Inferential Statistics
Assume that you are a Data Scientist working for a company that manufactures cell phones. You have to analyze customers using the mobile phones of your company. In order to do so, you will first take a thorough look at the data and understand various trends and patterns involved.
In the end, you will summarize the data and present it in the form of a graph or a chart. You therefore, apply Descriptive Statistics to solve the problem.
You will then draw ‘inferences’ or conclusions from the data. We will understand inferential statistics through the following example – Assume that you wish to find out a number of defects that occurred during manufacturing.
However, individual testing of mobile phones can take time. Therefore, you will consider a sample of the given phones and make a generalization about the number of defective phones in the total sample.
Now, you have to predict the sales of mobile phones over a period of two years. As a result, you will use Regression Algorithms. Based on the given historical sales, you will use regression algorithms to predict the sales over time.
Furthermore, you wish to analyze if customers will purchase the product based on their annual salary, age, gender, and credit score. You will use historical data to find out whether customers will buy (1) or not (0). Since there are two outputs or ‘classes’, you will use a Binary Classification Algorithm.
Also, if there are more than two output classes we use Multivariate Classification Algorithm to solve the problem. Both of the above-stated problems are part of ‘Supervised Learning’.
There are also instances of ‘unlabeled’ data. In this, there is no segregation of output in fixed classes as mentioned above. Suppose that you have to find clusters of potential customers and leads based on their socio-economic background.
Since you do not have a fixed set of classes in your historical data, you will use the Clustering Algorithm to identify clusters or sets of potential clients. Clustering is an ‘Unsupervised Learning’ algorithm.
Self Driving cars have become a trending technology. The principle behind the self-driving car is autonomy, that is, being able to take decisions without human interference. The traditional computers required human input to yield output. Reinforcement Learning has solved the problem of human-dependence.
Reinforcement Learning is about taking specific actions to accumulate maximum reward. You can understand this with the following instance: Assume that you are training a dog to fetch ball. Then you reward the dog with a treat or reward each time it fetches the ball.
You do not give it a treat if it does not fetch the ball. The dog will realize the reward of treats if it fetches the ball back. Reinforcement Learning uses the same principle. We give a reward to the agent based on its action and it will try to maximize the reward.
A Data Scientist will require tools and software to tackle the above-mentioned problems. We will now take a look at some of the tools that a Data Scientist uses to those problems.
Tools for Data Science
Data Scientists use traditional statistical methodologies that form the core backbone of Machine Learning algorithms. They also use Deep Learning algorithms to generate robust predictions. Data Scientists use the following tools and programming languages:
i. R
R is a scripting language that is specifically tailored for statistical computing. It is widely used for data analysis, statistical modeling, time-series forecasting, clustering etc. R is mostly used for statistical operations.
It also possesses the features of an object-oriented programming language. R is an interpreter based language and is widely popular across multiple industries
ii. Python
Like R, Python is an interpreter based high-level programming language. Python is a versatile language. It is mostly used for Data Science and Software Development. Python has gained popularity due to its ease of use and code readability.
As a result, Python is widely used for Data Analysis, Natural Language Processing, and Computer Vision. Python comes with various graphical and statistical packages like Matplotlib, Numpy, SciPy and more advanced packages for Deep Learning such as TensorFlow, PyTorch, Keras etc.
For the purpose of data mining, wrangling, visualizations and developing predictive models, we utilize Python. This makes Python a very flexible programming language.
iii. SQL
SQL stands for Structured Query Language. Data Scientists use SQL for managing and querying data stored in databases. Being able to extract information from databases is the first step towards analyzing the data. Relational Databases are a collection of data organized in tables.
We use SQL for extracting, managing and manipulating the data. For example A Data Scientist working in the banking industry uses SQL for extracting information of customers. While Relational Databases use SQL, ‘NoSQL’ is a popular choice for non-relational or distributed databases.
Recently NoSQL has been gaining popularity due to its flexible scalability, dynamic design, and open source nature. MongoDB, Redis, and Cassandra are some of the popular NoSQL languages.
iv. Hadoop
Big data is another trending term that deals with management and storage of huge amount of data. Data is either structured or unstructured. A Data Scientist must have a familiarity with complex data and must know tools that regulate the storage of massive datasets.
One such tool is Hadoop. While being open-source software, Hadoop utilizes a distributed storage system using a model called ‘MapReduce’. There are several packages in Hadoop such as Apache Pig, Hive, HBase etc.
Due to its ability to process colossal data quickly, its scalable architecture and low-cost deployment, Hadoop has grown to become the most popular software for Big Data.
v. Tableau
Tableau is a Data Visualization software specializing in graphical analysis of data. It allows its users to create interactive visualizations and dashboards.
This makes Tableau an ideal choice for showing various trends and insights of the data in the form of interactable charts such as Treemaps, Histograms, Box plots etc. An important feature of Tableau is its ability to connect with spreadsheets, relational databases, and cloud platforms.
This allows Tableau to process data directly, making it easier for the users.
vi. Weka
For Data Scientists looking forward to getting familiar with Machine Learning in action, Weka is can be an ideal option. Weka is generally used for Data Mining but also consists of various tools required for Machine Learning operations.
It is completely open-source software that uses GUI Interface making it easier for users to interact with, without requiring any line of code.
Applications of Data Science
Data Science has created a strong foothold in several industries such as medicine, banking, manufacturing, transportation etc. It has immense applications and has variety of uses. Some of the following applications of Data Science are:
i. Data Science in Healthcare
Data Science has been playing a pivotal role in the Healthcare Industry. With the help of classification algorithms, doctors are able to detect cancer and tumors at an early stage using Image Recognition software.
Genetic Industries use Data Science for analyzing and classifying patterns of genomic sequences. Various virtual assistants are also helping patients to resolve their physical and mental ailments.
ii. Data Science in E-commerce
Amazon uses a recommendation system that recommends users various products based on their historical purchase. Data Scientists have developed recommendation systems predict user preferences using Machine Learning.
iii. Data Science in Manufacturing
Industrial robots have made taken over mundane and repetitive roles required in the manufacturing unit. These industrial robots are autonomous in nature and use Data Science technologies such as Reinforcement Learning and Image Recognition.
iv. Data Science as Conversational Agents
Amazon’s Alexa and Siri by Apple use Speech Recognition to understand users. Data Scientists develop this speech recognition system, that converts human speech into textual data. Also, it uses various Machine Learning algorithms to classify user queries and provide an appropriate response.
v. Data Science in Transport
Self Driving Cars use autonomous agents that utilize Reinforcement Learning and Detection algorithms. Self-Driving Cars are no longer fiction due to advancements in Data Science.
vi. Data Science in Finance
Data Science helps in analyzing market trends, fraud detection and financial institutions access business more accurately.
Summary
While Data Science is a vast subject, being an aggregate of several technologies and disciplines, it is possible to acquire these skills with the right approach.
In the end, Data Science is a very robust field that best fits people who have a knack for experimentation and problem-solving. With a large number of applications, Data Science has become the most versatile career.
If you are Happy with DataFlair, do not forget to make us happy with your positive feedback on Google





Nice information….having good connectivity and flow…precise information
It’s really useful for those who are planning to start a career in data science. And this is really useful for me. I thank those who suggested me this Data Science tutorial.
We are glad that you liked our data science tutorial. We have 370+ Data Science tutorials that can help you become a data science expert. You can check them here – https://data-flair.training/blogs/data-science-tutorials-home/
this is information really useful for me and actually I want to start my career in Data Science, So this information useful for those who were planning to start a career in data science.
We are glad that our readers are liking the data science tutorial. We have 370+ Data Science tutorials that will bring you one step closer to your dream of becoming a data scientist. You can check them here – https://data-flair.training/blogs/data-science-tutorials-home/
thank you
Thanks for the feedback. If you liked the data science tutorial, share it on Facebook and Linkedin.
Hi
Do you have a online course for data science ?
The best way to start your data science journey is by learning Python programming. And, to gain strong theoretical & practical knowledge of Python that will help you to get top Python jobs in the industry, enroll now for the Certified Python Training Course
Very informative article. Smooth flow between topics is observed. It is nice of the author to introduce the names of concepts and terms without going deep into them. This introduces the Terms and kindles interest for further reading.
i did b.tech in cse, i wanna to do pg . which one one is the best specialization data science or artificial intelligence for m.tech?but i cant decide that which one is better. so kindly give me advice. thanks
I am also looking for this Free Data Science Training and Tutorial.
Very interesting.
And I will like to take Data Science a Job. from the information gotten above, I really enjoy the field.
This is useful,course for me I want study datascience.
Thank you
I am glad to get an into what data science is really about. When I read , the whole concept of data science was talking me and fully relates to what I want to pursue. Thanks for tis information
If possible please add “Next ” and ” previous” button at end of every articles. It will help user for easy access.
thank you Data flair
I am teaching Statistics to BS/MS level students. When I read , the whole concept of data science was talking me and fully relates to what I want to pursue. Thanks for tis information.