6 Intriguing Applications of Data Science in Banking – [JP Morgan Case Study]
Machine Learning courses with 100+ Real-time projects Start Now!!
Companies need data to develop insights and make data-driven decisions. In order to provide better services to its customers and devise strategies for various banking operations, data science is a mandatory requirement.
Furthermore, banks need data to grow their business and draw more customers. We will go through some of the important areas where banking industries use data science to improve their products. We will see the major role of data science in banking sectors.
Then we will understand the use case of JP Morgan Chase applying data science in banking sector.
Data Science in Banking
Here are 6 interesting data science applications for banking which will guide you how data science is transforming banking industry.
1. Risk Modeling
Risk Modeling a high priority for the banking industry. It helps them to formulate new strategies for assessing their performance. Credit Risk Modeling is one of its most important aspects. Credit Risk Modeling allows banks to analyze how their loan will be repaid.
In credit risks, there is a chance of the borrower not being able to repay the loan. There are many factors in credit risk that makes it a complex task for the banks.
With Risk Modeling, banks are able to analyze the default rate and develop strategies to reinforce their lending schemes. With the help of Big Data and Data Science, banking industries are able to analyze and classify defaulters before sanctioning loan in a high-risk scenario.
Risk Modeling also applies to the overall functioning of the bank where analytical tools used to quantify the performance of the banks and also keep a track of their performance.
2. Fraud Detection
With the advancements in machine learning, it has become easier for companies to detect frauds and irregularities in transactional patterns. Fraud detection involves monitoring and analysis of the user activity to find any usual or malicious pattern.
With the increase in dependency on the internet and e-commerce for transactions, the number of frauds has increased significantly.
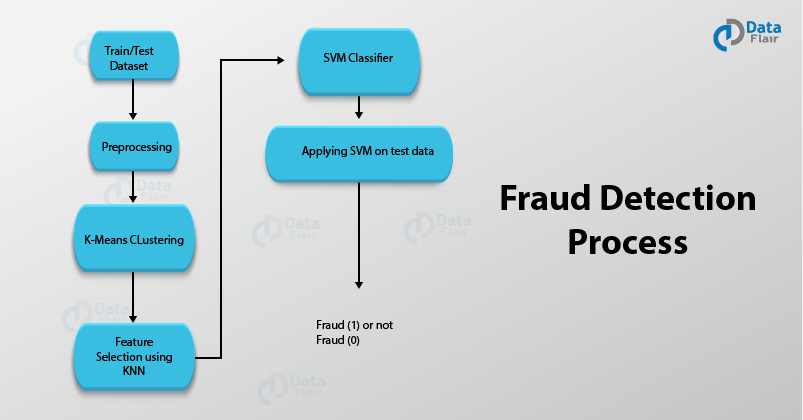
Using data science, industries can leverage the power of machine learning and predictive analytics to create clustering tools that will help to recognize various trends and patterns in the fraud-detection ecosystem.
There are various algorithms like K-means clustering, SVM that is helpful in building the platform for recognizing patterns of unusual activities and transactions. The process of Fraud Detection involves –
- Obtaining the data samples for training the model.
- Training our model on the given datasets. The process of training involves the implementation of several machine learning algorithms for feature selection and further classification.
- Testing and Deploying our model.
For instance, two algorithms like K-means clustering and SVM can be used for data-preprocessing and classification. K-means can be used for feature selection and SVMs are then applied to the data for its classification into a fraudulent class or otherwise.
3. Customer Lifetime Value
Customers are an essential part of the banking industries. They ensure a steady stream of revenues. Formally speaking, a Customer Lifetime Value offers a discounted value of the future revenues that are contributed by the customer. Banks are often required to predict future revenues based on past ones.
Also, banks want to know the retention of customers and if they will help to generate revenues in the future as well. Banks want their customers to be satisfied and nurture them for the current as well as future prospects.
Businesses like banking sectors are required to predict their customer lifetime value. Data Science in banking plays an essential role in this part.
With predictive analytics, banks can classify potential customers and assign them with significant future value in order to invest company resources on them. While the classification algorithms help the banks to acquire potential customers, retaining them is another challenging task.
With the growth in the competition, banks require a comprehensive view of the customers to channel their resources in an optimized manner.
There are various tools that are used in data preprocessing, cleaning and prediction. There are various tools such as Classification and Regression Trees (CART), Generalized Linear Models (GLM), etc.
This allows the banks to monitor their customers and contribute towards the growth and profitability of the company.
4. Customer Segmentation
In customer segmentation, banks group their customers based on their behavior and common characteristics in order to address them appropriately.
In this scenario, machine learning techniques like classification and clustering play a major role in determining potential customers as well as segmenting customers based on their common behaviours.
One popular clustering technique is K-means, that is widely used for clustering similar data points.
It is an unsupervised learning algorithm, meaning that the data on which it is applied does not have any labels and does not possess an input-output mapping. Some of the various ways in which customer segmentation helps the banking institutions are –
- Identification of customers based on their profitability.
- Segmenting customers based on their usage of banking services.
- Strengthening relationships with their customers.
- Providing appropriate schemes and services that appeal to specific customers.
- Analyzing customer segments to implement and improve services.
5. Recommendation Engines
Providing customized experiences to clients is one of the major roles that a bank plays. Based on customer transactions and personal information to suggest offers and extended services.
Banks also estimate what products the customer may be interested in buying after analyzing historical purchases. With this, banks will be able to recommend the product of the companies that have tied up with them.
It also recommends customer centric or product-centric offering based on their preferences. Banks can also recommend offers that are highly appealing to customers. There are two types of recommendation engines that are used by the banks –
- User-Based Collaborative Filtering
- Item-Based Collaborative Filtering
6. Real-Time Predictive Analytics
Predictive Analytics is the process of using computational techniques to predict future events. Machine Learning is the main toolbox of predictive analytics. Machine Learning is an ideal tool for improving the analytical strategy of the banks.
With the rapid increase in data, there is an abundance of use cases and the exigency of analyzing data is at its peak.
There are two types of major analytics techniques –
- Real-time analytics
- Predictive analytics
Real-time analytics allows customers to understand problems that impede businesses. Predictive Analytics, on the other hand, allow the customers to select the right technique to solve the problems.
There are areas like financial management of banking sectors that allow the industries to manage the finances and devise new strategies.
Explore How Data Science is Transforming the Education Sector
Data Science in Banking Case Study
How JP Morgan Chase uses Data Science
JP Morgan Chase is one of the premier banks of the world today. It is one of the largest consumers of data with a staggering 150 petabytes of data holding about 3.5 billion users under its wing.
With such a surplus amount of data, JP Morgan makes use of the Big Data Analytics system that processes unstructured and structured data. It makes extensive use of the popular open-source platform – Hadoop.
Started your Hadoop Training? Learn Big Data and Hadoop with industry veterans
Mobile phones and internet services generate conventional structured data. This type of data is easy to handle.
However, more unconventional data like emails, customer conversations, reviews cannot process with traditional SQL tools. For this reason, Hadoop is an ideal platform for accommodating both types of data.

Some of the areas where JP Morgan Chase is using Hadoop for analyzing data are –
Fraud Detection
With an active tracking of phone calls and emails, JP Morgan Chase is monitoring for unusuality and searching for irregularities in the transactions.
Adding Value for Clients
JP Morgan Chase has been making the best use of the internet platform and digitization. It offers its customers deep insights about their businesses.
JP Morgan uses Big Data to analyze and process customer queries, provides them with cash forecasting, incrementing their turnover and benchmarking their performance against other competitors
You must read about – Latest Big Data Trends
Effective Cash Management
Cash Management is an important concern of customers. Clients want their cash to be effectively managed and be benefitted with capital protection. JP Morgan makes use of predictive analytics to forecast cash flows and provide deep insights about various existing loopholes.
Providing Insights about Trends in Credit Market
“CreditMap” is an application that provides intuitive information to the customers of JP Morgan. It makes use of Datawatch platform to provide the customers with real-time analytics.
Improving Public Economy
JP Morgan Chase is helping the US government by making tools for policy-making using Big Data. It is combining the transactions of 30 million American customers with the economic statistics of the United States.
It will use big data tools to analyze all the public information and help the policymakers to prevent financial disasters.
Summary
Banks use Data Science to keep your money safe and grow their business. One common use is fraud detection. Data Science helps find strange or risky activities, like if your card is used in two cities at the same time. It alerts the bank so they can stop fraud fast and protect your account.
Another use is in giving loans. Banks use your credit score, past spending, and other details to decide if you are fit for a loan. This is done by machine learning models trained on past loan records. These models reduce risk and help the bank offer better loan plans to good customers.
Data Science also improves customer support. Chatbots and virtual assistants in banking apps answer questions quickly. Data also helps suggest better saving or investment plans based on your income and spending. This makes banking smarter and more personal.
Furthermore, we understood how premier banking institutions like JP Morgan Chase are using data science to improve their client experience.
Hope you gathered a good experience of reading this blog. Share your valuable feedback through comments, it means a lot for us.
Your opinion matters
Please write your valuable feedback about DataFlair on Google





Thank you for sharing the wonderful information.