Transfer Learning for Deep Learning with CNN
Machine Learning courses with 100+ Real-time projects Start Now!!
In this blog, we will study Transfer Learning. As this Transfer Learning concept relates with deep learning and CNN also. Although, will use graphs and images to understand Transfer Learning concept.
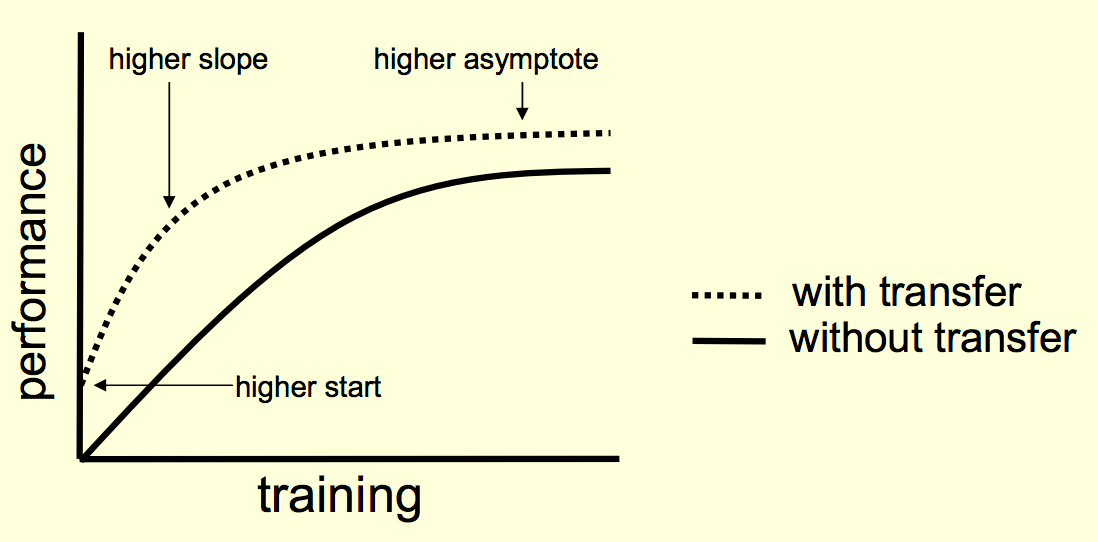
Introduction to Transfer Learning
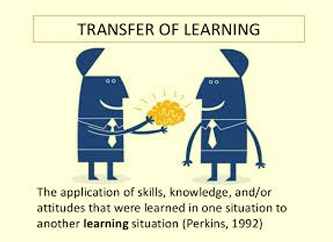
Introduction to Transfer Learning
Introduction to Transfer Learning

Introduction to Transfer Learning
What is a Pre-Trained Model?
How can I use Pre-trained Models?
As there is a predefined aim to use a pre-trained model. Also, a concept of transfer learning plays an important role in a pre-trained model.
While choosing a pre-trained model, one should be careful in their case. If the problem statement we have at hand is very different from the one on which the pre-trained model was trained – the prediction we would get would be very inaccurate.
As already many pre-trained architectures are directly available for use in the Keras library. Imagenet data set has been widely used to build various architectures since it is large enough (1.2M images) to create a generalized model. Although, the problem statement comes in training a model.
That can correctly classify the images into 1,000 separate object categories. Moreover, these 1,000 image categories represent object classes that we come across in our day-to-day lives. Such as species of dogs, cats, various household objects, vehicle types etc.
We use transfer learning to generalize into images outside the ImageNet dataset. This happens only in case of a pre-trained model. Also, we use fine-tuning model for the modifications in a pre-trained model. Since we assume that the pre-trained network has been trained quite well.
Thus, we don’t want to modify the weights too soon and too much. While modifying we generally use a learning rate smaller than the one used for initially training the model.
Ways to Fine tune the model
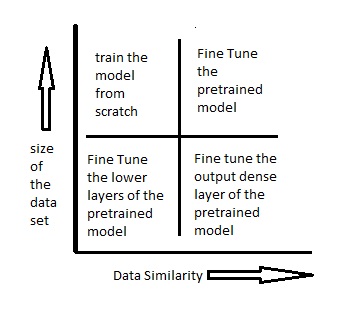
Ways to Fine tune the model
a. Feature extraction – For a feature extraction mechanism, we use a pre-trained model as in this we can remove the output layer. Further, we have to use the entire network as a fixed feature extractor for the new data set.
b. Use the Architecture of the pre-trained model – According to a dataset, at the time of initializing and training model, we use its architecture.
c. Train some layers while freeze others – There is one more way to use a pre-trained model i.e to train model partially. Further, we have to keep the weights of initial layers of the model frozen. While have to retrain only higher layers. We can try and test as to how many layers to be frozen and how many to be trained.
The below diagram should help you decide on how to proceed with using the pre-trained model in your case –
Scenario 1 – Size of the Dataset is small while the Data similarity is very high – As in this particular case, we do not require to retain the model, as data similarity is very high.
Although, according to our problem statement, we need to customize and modify the output layers. As we have use pre-trained model here as a feature extractor.
Further, to identify the new set of images have cat or dogs, we use trained models on Imagenet. Here we require similar images to Imagenet to categorize the two outputs – cats or dogs.
Finally, at last in this case, we have to modify dense layers. Also, have to put the final softmax layers to output 2 categories instead of 1000.
Scenario 2 – Size of the data is small as well as data similarity is very low – As in this case, we have to freeze the initial (let’s say k) layers of the pre-trained model. Also, as freezing complete, then train the remaining(n-k) layers again.
Although, keep in mind that the top layers would be customized to the new data set. Also, initial layers are kept pre-trained by their smaller size. But, keep frozen weights of those layers.
Scenario 3 – Size of the data set is large however the Data similarity is very low – Particularly, in this case, neural network training would be more effective. As it’s having a large data set. Also, the main thing is that the data we use is different.
As we use data is different from data we use in training. Hence, its best to train the neural network from scratch according to your data.
Scenario 4 – Size of the data is large as well as there is high data similarity – We can say this is the final and the ideal situation. As pre-trained models are more effective in this case. Also, we can use this model in very good manner.
We have to just use the model is to retain the architecture of the model and the initial weights of the model. Moreover, we can retrain this model using the weights as initialized in the pre-trained model.
Inductive learning and Inductive Transfer
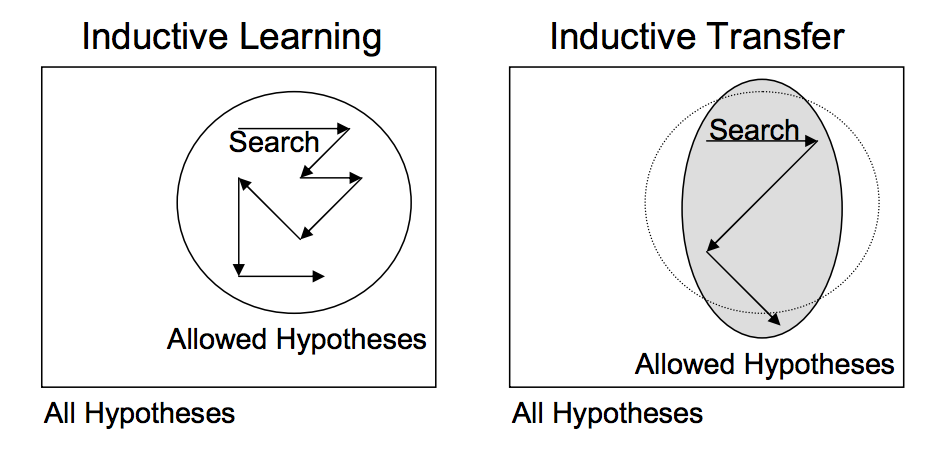
Inductive learning and Inductive Transfer
How to Use Transfer Learning?
- Develop Model Approach
- Pre-trained Model Approach
a. Develop Model Approach
b. Pre-trained Model Approach
When to Use Transfer Learning?
Transfer Learning for Deep Learning with CNN
Conclusion
Did you like this article? If Yes, please give DataFlair 5 Stars on Google





svp je suis débutante en programmation je travaille sur la détection des feux en utilisant les cnn esque je peux utiliser l’apprentissage par transfert ?