Everything You Need to Know About Data Mining and Data Science
Machine Learning courses with 100+ Real-time projects Start Now!!
n this article, we will understand the two concepts of Data Mining and Data Science. Most of the times, people come across these two terms on the internet.
Considering that both of them deal with data, it almost causes ambiguity to the readers. In this article, we will demystify the concepts behind Data Mining and Data Science.
Data Mining and Data Science
Data Mining and Data Science are two of the most important topics in technology. Both of these fields revolve around data. However, the way they use data is different.
Furthermore, the knowledge required to carry out operations in these fields is also different. Therefore, we will understand the concepts behind these two fields and analyze their key differences.
What is Data Mining?
Mining in its casual terms refers to the extraction of valuable minerals. In the 21st century, Data is the most expensive mineral. To extract usable data from a given set of raw data, we use Data Mining.
Through Data Mining, we extract useful information in a given dataset to extract patterns and identify relationships.
The process of data mining is a complex process that involves intensive data warehousing as well as powerful computational technologies.
Furthermore, data mining is not only limited to the extraction of data but is also used for transformation, cleaning, data integration, and pattern analysis. Another terminology for Data Mining is Knowledge Discovery.
There are various important parameters in Data Mining, such as association rules, classification, clustering, and forecasting. Some of the key features of Data Mining are –
- Prediction of Patterns based on trends in the data.
- Calculating the predictions for the outcomes.
- Creating information in response to the analysis
- Focusing on greater databases.
- Clustering the visual data
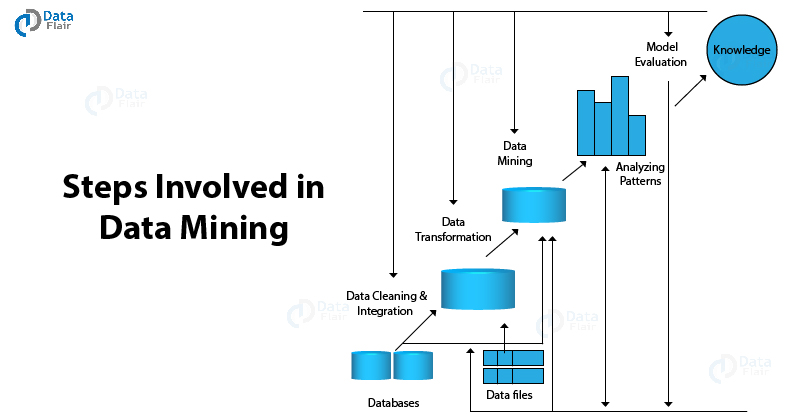
Data Mining Steps
Knowledge discovery is an essential part of Data Mining. The important steps involved in Data Mining are –
1: Data Cleaning – In this step, data is cleaned such that there is no noise or irregularity present within the data.
2: Data Integration – In the process of Data Integration, we combine multiple data sources into one.
3: Data Selection – In this step, we extract our data from the database.
4: Data Transformation – In this step, we transform the data to perform summary analysis as well as aggregatory operations.
5: Data Mining – In this step, we extract useful data from the pool of existing data.
6: Pattern Evaluation – We analyze several patterns that are present in the data.
7: Knowledge Representation – In the final step, we represent the knowledge to the user in the form of trees, tables, graphs, and matrices.
Data Mining Applications
There are various applications of Data Mining such as –
- Market and Stock Analysis
- Fraud Detection
- Risk Management and Corporate Analysis
- Analyzing the Customer Lifetime Value
Explore 10 more Data mining Applications
Data Mining Tools
Some of the popular tools used for Data Mining are –

1. RapidMiner
It is one of the most popular tools for data mining. It is written in Java but requires no coding to operate it. Furthermore, it provides various data mining functionalities like data-preprocessing, data representation, filtering, clustering, etc.
2. Weka
Weka is an open-source data mining software developed at the University of Wichita. Like RapidMiner, it has a no-coding and a simple to use GUI.
Using Weka, you can either call the machine learning algorithms directly or import them with your Java code. It provides a variety of tools like visualization, pre-processing, classification, clustering, etc.
3. KNime
KNime is a robust data mining suite that is primarily used for data preprocessing, that is, ETL: Extraction, Transformation & Loading. Furthermore, it integrates various components of Machine Learning and Data Mining to provide an inclusive platform for all suitable operations.
4. Apache Mahout
Apache Mahout is an extension of the Hadoop Big Data Platform. The developers at Apache developed Mahout to address the growing need for data mining and analytical operations in Hadoop. As a result, it contains various machine learning functionalities like classification, regression, clustering, etc.
Learn more about Hadoop and Big Data
5. Oracle DataMining
Oracle Datamining is an excellent tool for classifying, analyzing and predicting data. It allows its users to perform data-mining on its SQL databases to extract views and schemas.
6. TeraData
For data-ming, warehousing is a necessary requirement. TeraData, also known as TeraData Database provides warehouse services that consist of data mining tools.
It can store data based on their usage, that is, it stores less-frequently used data in its ‘slow’ section and gives fast access to frequently used data.
7. Orange
Orange software is most famous for integrating machine learning and data mining tools. It is written in Python and offers interactive and aesthetic visualizations to its users.
What is Data Science?
Data Science is one of the trending jobs of the 21st century. It has been dubbed as the “sexiest job of the 21st century” by Harvard Business Review. Over the past few years, it has become a buzzword that has gained a lot of attraction.
The emergence of advanced technologies in the field of computer science has contributed to a massive increase in data. Companies need to analyze and derive meaningful information out of the data.
This special position is qualified for a Data Scientist who is well versed with statistical and computational tools. With the knowledge of machine learning, a data scientist is able to predict future events.
Data Science, is, therefore, a vast discipline that involves various data operations like data extraction, data processing, data analysis and prediction of data.
Data Science holds its roots in multiple disciplines like Mathematics, Statistics and Computer Programming. Industries need Data Scientists who can help them to take powerful data-driven decisions.
There are abundant positions in the field of data science. This is because data is omnipresent. It has expanded exponentially and has created a need for its analysis.
Understand – Data Science with Real-Life Analogies
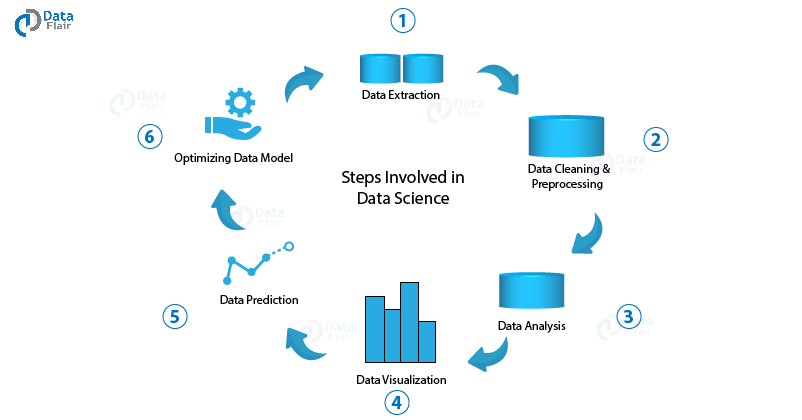
Data Science Steps
Following are the 5 steps in Data Science –
Step 1: Data Extraction – The first step in data science is the retrieval of data. The data retrieved can be in the form of structured and non-structured data. There are several databases that support data retrieval queries like SQL and NoSQL.
Do want to learn about SQL? Check – SQL Guide.
Step 2: Data Preprocessing – This step involves data cleaning, data transformation and replacement of the missing values. This is the most important step as it organizes the data and makes it useful for further analysis.
Step 3: Data Analysis – Data Analysis involves the usage of several statistical methods like inferential statistics and descriptive statistics to find patterns and trends within data.
Step 4: Generating Predictions – The next important step is to generate predictions using Machine Learning Algorithms. There are several types of predictions and classifications that are performed on the historical data to forecast future events as well as capture patterns within the data.
Step 5: Optimizing Models – The final step is optimizing the machine learning model to improve its performance and deliver accurate results.
Data Science Tools
Some of the important tools used in data science are –
1. Python – Python is the most popular programming language that is used for data science as well as software development. It offers a wide variety of libraries that support data science operation.
2. R – R is an open-source statistical programming language that offers various packages that can assist you in visualizing and analyzing data.
3. SAS – SAS stands for Statistical Analysis System, which is a software suite developed by SAS Institute to facilitate various statistical operations. It is a closed-source proprietary tool that is the first choice of many organizations due to its stability and reliability.
4. Apache Spark – Apache Spark is an advanced Big Data tool that provides data processing and analysis capabilities. It is most widely known for its ability to perform stream processing as opposed to batch processing performed by previous platforms.
5. D3.js – D3.js is a javascript based library for creating interactive visualizations. Using this tool, you can embed aesthetic graphs in your web application.
6. Tableau – Tableau is visualization software that is used for making interactive graphs and charts. It is capable of interfacing with OLAPs, spreadsheets and SQL databases. Furthermore, Tableau is capable of plotting longitude and latitudes in maps.
7. TensorFlow – TensorFlow is a powerful machine learning library that is used for implementing deep learning algorithms. It is a fast processing library that is supported by Graphical Processing Units (GPUs).
Data Mining vs Data Science
- Data Science is a pool of data operations that also involves Data Mining.
- A Data Scientist is responsible for developing data products for the industry. On the other hand, data mining is responsible for extracting useful data out of other unnecessary information.
- While Data Science is a quantitative field, Data Mining is limited to only business roles that require specific information to be mined.
- A Data Scientist is required to perform multiple operations like analysis of data, development of predictive models, discovering hidden patterns, etc. On the contrary, Data Mining involves statistical modeling to unearth useful information.
- A Data Scientist has to deal with both structured as well as unstructured data. On the other hand, Data Mining only deals with structured information.
Summary
Data mining and data science are often used together, but they are not the same. Data mining is a key step inside the data science process. It is the method of discovering patterns, trends, and useful insights from large datasets using statistical and mathematical techniques. Data mining uses algorithms to identify hidden relationships and structures in data that would be hard to notice manually. It helps businesses make smart decisions by showing what’s happening behind the numbers.
In the broader field of data science, data mining works along with other steps like data cleaning, data preparation, visualization, and model building. Data science includes more than just pattern discovery—it covers the entire process of collecting, understanding, and using data for solving real-world problems. Data scientists use mining techniques to gather useful features and feed them into predictive models or machine learning algorithms. So, while data mining is part of the toolkit, data science is the full workshop.
In this article, we went through the different concepts behind Data Mining and Data Science. Furthermore, we studied the applications of data mining, the steps involved and several tools that are used in both data science and data mining.
We hope that you enjoyed the article and are now well versed with the concepts of these two fields. Share your experience of reading this blog through comments. You may also like to read about Data Science Tools.
Your opinion matters
Please write your valuable feedback about DataFlair on Google




