NLP (Natural Language Processing) – A Data Science Survival Guide
Machine Learning courses with 100+ Real-time projects Start Now!!
Natural Language Processing (NLP) is one of the most popular fields of Artificial Intelligence. In the past century, NLP was limited to only science fiction, where Hollywood films would portray speaking robots.
However, with the advancements in the field of AI and computing power, NLP has become a thing of reality.
So, today we will discuss the tools and some important algorithms used in this field.
What is Natural Language Processing?
Natural Language Processing is a field that studies and develops methodologies for interactions between computers and humans. Basically, Natural Language Processing deals with the development of ability in computers to understand the human language (Natural Language = Human Language).
There are various fields in Natural Language Processing like parsing, language syntax, semantic mining, machine translation, speech recognition, and speech synthesis.
NLP has transformed the AI industry. Several industries are using NLP for developing virtual assistants and understanding their customer insights. The intelligent personal assistants like Apple Siri, Google Assistant, Amazon Alexa have become highly popular.
The field of NLP has been in evolution since the 1950s when Alan Turing pioneered Artificial Intelligence and came up with the idea of “Turing Test” to measure the intelligence of computers. Let us understand some of the core terminologies that are utilized in Natural Language Processing.
Did you check the latest Artificial intelligence guide?
1. Corpus
A corpus is a large collection of textual data that is structured in nature. There are two types of the corpus – monolingual corpus (containing text from a single language) and multilingual corpus (containing text from multiple languages).
NLTK, which is the most popular tool in NLP provides its users with the Gutenberg dataset, that comprises of over 25,000 free e-books that are available for analysis.
The multilingual corpus is often present in the form of a parallel corpus, meaning that there is a side-by-side translation of the text present in the data-set. This is useful for machine translation where you are required to train your model in parallel data to gain necessary insights about it.
Another important extension of the corpus is with the POS (Parts of Speech) tagger where each word’s part of speech (verb, noun, adjective) are added to the corpus.
2. Semantic & Syntactic Analysis
A Syntactic Analyzer is tasked with validating the sentence structure present in the corpus. Context Free Grammer is an important rule for verifying the sentence structure. The sentences are presented in the form of a tree using parsers like Earley Algorithm, Cocke-Kasami-Younger (CKY), Chart Parser, etc.
Semantic Mining and Analysis is used for finding the meaning of the sentence. Using semantic analysis of information, we can train models that identify the writing styles of authors and are able to classify them.
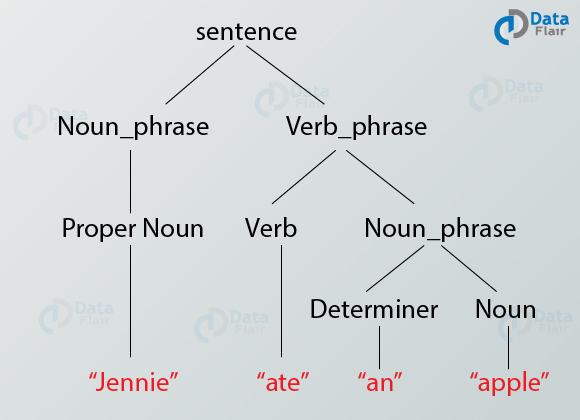
3. Parsing
Language Parsing is a tool or a program that analyzes and works out the structure of sentences in grammar. It is used for finding the right combination of phrases, subject as well as the verb of the sentences.
Using parsing, you can analyze the constituent components of the language based on its underlying grammar. Parsing involves the construction of a parse tree that represents the syntactic structure of the sentence.
Recommended Reading – Top Machine Learning Algorithms
4. Stemming & Lemmatization
Reducing a word to its original word stem is known as stemming. It is also the reduction of a word’s derivations to a common form. For example, democracy, democratic, democratically are different versions of the word democracy.
Therefore, there can be requirements where we are supposed to reduce the words to their original stems.
Lemmatization performs a similar operation but takes into consideration the morphological analysis of the sentence. The most popular algorithm for stemming English sentences is Porter’s Algorithm.
5. Tokenization
In the process of Tokenization, we break down a sentence into its individual components called tokens. For example, for the sentence “Ground Control to Major Tom”, we obtain the following tokens –
[‘Ground’, ‘Control’, ‘to’, ‘Major’, ‘Tom’]
6. Deep Learning and Natural Language Processing
Deep Learning is an advanced machine learning algorithm that makes use of an Artificial Neural Network. It has brought a revolution in the domain of NLP.
Traditionally, statistical approaches and small-scale machine learning algorithms to analyze and derive meaning from the textual information. However, with the growth in data and stagnant performance of these traditional algorithms, Deep Learning was used as an ideal tool for performing NLP operations.
Some of the popular Deep Learning approaches for solving problems of NLP are:
a. Word Embeddings
Word Embeddings share the same principle as the distributional hypothesis which finds words appearing in a similar context to have the same meaning. In word embeddings, words are predicted based on their context.
It takes its input in the form of word vectors that contain syntactical and semantical information about the sentences.
b. Word2Vec
It is a group of models that are used to generate word embeddings. Word2Vec are largely used for producing vector space, that takes a large corpus of text as its input. The vector space is spread out in hundreds of dimensions where each word is assigned a vector.
Word2Vec uses one of the two models – CBOW & skip-gram model. Using CBOW, you can create word embeddings and can also compute the probability of the target word given the context.
Skip-gram model makes use of the neural approach to construct word embeddings where the goal is the prediction of the surrounding context words.
c. Recurrent Neural Networks
Recurrent Neural Networks are designed for processing sequential data like text. An RNN makes use of recursive cycles to compute the instance of an input sequence that is based on the previous inputs.
What makes RNN efficient is its ability to memorize information extracted from the previous computations and use that for the current computations.
Because of this, RNNs are most widely used for machine translation, language modeling, image captioning etc.
However, with the deepening of the RNN networks, it starts to exhibit the problem of vanishing gradient. In order to mitigate this, RNNs are coupled with Long Short Term Memory (LSTMs) which we will discuss further.
d. Long Short Term Memory
A Long Short Term Memory (LSTM) is an improvement over the existing RNN model as it mitigates the issue of vanishing gradient. It does so with the help of three gates – input, forget and output gates.
There are various LSTM models that are used for machine translation, image captioning, question-answering, text summarization etc.
Furthermore, there is an additional extension of LSTM called Bi-directional LSTM that allows the network model to analyze the textual data in both the directions, that is, from start to end and from end to start. This allows the model to capture the context of data properly and make accurate classifications.
Tools for NLP (Natural Language Processing)
Some of the popular tools for Natural Language Processing are –
NLTK

It is a popular natural language processing library that provides support for the Python programming language. NLTK stands for Natural Language Toolkit and provides first-hand solutions to various problems of NLP.
With NLTK, you can tokenize the data, perform Named Entity Recognition and produce parse trees. It provides the Gutenburg corpora of over 2500 titles that are free to be used and can be analyzed.
Gensim

Gensim is an open-source natural language modeling library that is used for unsupervised topic modeling. An important feature of Gensim is that it is able to handle large data collection and manage data streams through incremental algorithms.
Gensim is highly popular and has been widely used in the field of medicine, insurance claim as well as patent search.
Don’t forget to check Bayes’ Theorem for Data Science
spaCy

spaCy is an advanced Natural Language Processing Library. It is written in Python and Cython. While NLTK is mostly used for research prototyping, spaCy is geared towards production and software NLP.
spaCy follows a robust workflow that allows connection with other libraries like TensorFlow, Theano, Keras etc.
Its more recent version, spaCy 2.0 offers convolutional neural networks for parts-of-speech tagging, NER tagging and dependency parsing.
CoreNLP
CoreNLP was developed at Stanford University’s Natural Language Processing Group. It is written in Java and is a production-ready, enterprise solution. CoreNLP is fast, efficient and provides a variety of NLP solutions.
It provides support for performing operations on a number of human languages. It is capable of performing a variety of operations like sentiment analysis, parts-of-speech tagging, Named-entity-recognition, bootstrapped pattern learning and a conference resolution system.
Hope now you understood what natural language processing is. We hope that you benefitted from this article and now you are well versed with the varying aspects of NLP. Still, if you want to ask anything about the same, you can freely ask through the comment section.
Do you know how Netflix is using Data Science?
Did you know we work 24x7 to provide you best tutorials
Please encourage us - write a review on Google





Good Post! , it was so good to read and useful to improve my knowledge as an updated one,
keep blogging.
Good Post! , it was so good to read and useful to improve my knowledge as an updated one,
keep blogging. If you are looking for data science course-related articles,
visit Learnbay. co website, best data science institute.
Upgrade your knowledge by learning the best data science course from the best data science institute in Bangalore (Learnbay).
It’s crazy to think that speaking robots were just a sci-fi trope in old Hollywood films last century, but now NLP is a complete reality thanks to massive leaps in computing power. I’m really interested to see which specific algorithms and tools this survival guide covers next. As someone trying to navigate data science right now, this is super timely.
It’s crazy to think that just a few decades ago, speaking robots were confined to Hollywood sci-fi films, but now NLP is an everyday reality thanks to massive jumps in computing power. I’m really interested in the next part of this guide, especially which specific tools and algorithms you recommend starting with.
It’s wild to think about how NLP went from just being a Hollywood sci-fi trope of speaking robots in the last century to an actual reality we use daily. The leap in computing power has really changed the game, so I’m interested to see which specific algorithms and tools this guide recommends for tackling it.
It’s wild to think how NLP used to be just a sci-fi trope in Hollywood movies with talking robots, but now it’s an everyday reality. The massive leap in computing power has really changed what’s possible with AI. I’m definitely interested in seeing which specific tools and algorithms you recommend as essential for a data science survival guide.
It’s wild to think that NLP was just a Hollywood sci-fi concept with speaking robots last century, but now it’s an everyday reality thanks to massive jumps in computing power. The transition from science fiction to actual data science tools is just mind-blowing. I’m really interested to see which specific algorithms and tools you’ll be highlighting next in this guide.