Sharpen your Data Science Skills with Apache Spark
Machine Learning courses with 100+ Real-time projects Start Now!!
This 7-min Spark Tutorial is specially designed for those who want to become the next data scientist. It contains a hands-on overview of Spark, its features and components for Data Science.
I personally recommend, that when you add Spark skill in the resume, there are 60% more chances that you will get selected in the interview as compared to others.
Data Science has transformed the world. It has contributed towards the massive growth of data and the potential to harness that data to develop intelligent systems. The various tools of Data Science enable data scientists to analyze large amounts of data.
In this article, we will see how Spark has revolutionized the Data Science industry and various components of Spark. In the end, we will take a brief look at a use case that involves the use of Data Science with Apache Spark.
Introduction to Data Science
Data Science is one of the many technical buzzwords that have taken the world by storm. This is contributed by the massive increase in data and the many technological innovations that have contributed towards this growth.
Furthermore, Data Science has become a premier technology for mining insights from the dataset and assisting industries in solving their business problems. You can learn everything about Data Science by the FREE Data Science Tutorials Library.
After the introduction of data science, let’s take a brief intro to Apache Spark.
What is Apache Spark?
When Apache released its open-source Big Data framework called Hadoop in 2011, Big Data became a buzzword and a reigning technology. The framework makes use of MapReduce that was developed by Google.
The MapReduce framework in Hadoop suffered from certain shortcomings and in order to overcome them, Apache released Spark which was an advanced framework.
Learn everything about Apache Spark in detail.
Spark is an open-source, that is capable of processing data efficiently with lighting speed which comes loaded with several development APIs. The data streaming capability gives Spark an edge over other predecessor Big Data platforms.
You can also carry out machine learning operations and SQL workloads that allow you to access the datasets.
Spark also allows you to integrate with big data platforms like Hadoop Clusters. With this, it is able to address the drawbacks of MapReduce through stream processing and facilitation of iterative queries.
Hadoop is used by Spark but only for the storage of massive data in its cluster management system. This is an in-memory computation platform that makes use of the management system. Spark is developed on application levels through multiple languages like Python, Java, R, and Scala.
Components of Apache Spark for Data Science
Now, we will have a look at some of the important components of Spark for Data Science. These are 6 main components – Spark Core, Spark SQL, Spark Streaming, Spark MLlib, Spark R and Spark GraphX.
Spark Core
This is the foundation block of Spark. It contains an API that houses the Resilient Distributed Datasets or RDD. Spark Core is capable of carrying out memory management, storage system integration and fault recovery.
You must check how to create RDD in Apache Spark
Spark SQL
With the help of Spark SQL, you can perform querying and processing of structured data. You can also avail it for unstructured data. Through this, you can access HIVE, JSON, table using SparkSQL.
Spark Streaming
For many industrial applications, Spark Streaming is an important feature that makes it an ideal big data platform. Using this, you can perform easy manipulation of data that is stored in the disks. Spark makes use of micro-batching that allows real-time streaming of data.
MLlib
Machine Learning is the quintessential part of Data Science. For performing machine learning operations, Spark contains a sub-project called MLlib. With this, the programmer can perform various operations like regression, classification and clustering. We will discuss MLlib in more details ahead.
GraphX
For performing Graph Execution, we make use of the GraphX library. It is a Spark library that facilitates the use of computing graphs and their manipulation. The various algorithms that are used to make graphs are clustering, classification, searching, and pathfinding.
SparkR
With SparkR, data scientists can analyze large datasets using the R shell. It makes use of the combination of the usability of R with its scalability.
This is the right time to start learning Apache Spark with industry veterans
Features of Spark for Data Science
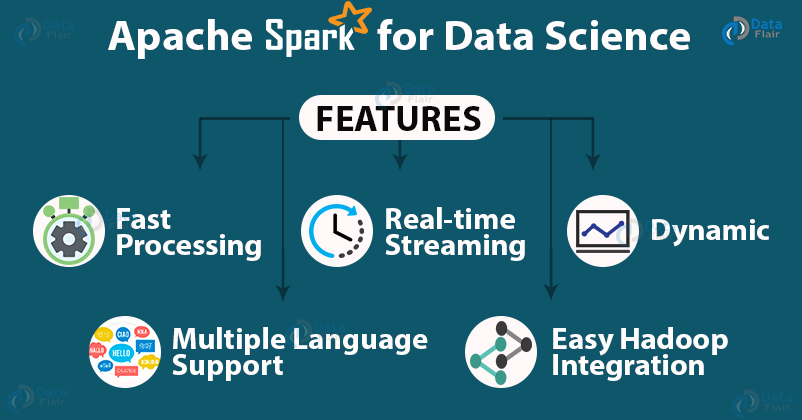
Lighting Fast Processing
With the help of Apache Spark, you can avail lightning-fast and efficient processing of big data. Spark is capable of processing the data 100 times more than MapReduce. This allows a significant decrease in the read-write operations that are appended to the disk.
Spark is Dynamic
Using Spark, one can develop parallel application. This is facilitated by the 80 high-level operators of the Spark platform.
Fault Tolerance
Through Spark RDD, Spark facilitates full-scale fault-tolerance. With the help of this, Spark ensures its capability to handle the failure of any working node in the Spark Platform. With this, there is a certainty of minimal data loss in the system.
Real-time streaming
Spark provides improvement over the older platforms like Hadoop. That is, Spark allows the data to be processed in real-time in the form of data streams as opposed to batch files.
Support for Multiple Languages
Through several programmable APIs in Java, R, Python, Spark provides a wide array of dynamic functionalities. This allows it to not only be programmed in Java but in many languages.
Easy Integration with Hadoop
There are several essential features in Spark that allow it to be connected to Hadoop Clusters. This allows Spark to be an efficient option for upgrading infrastructure that might otherwise cost fortune to the industries.
Data Science with Spark
One of the most important areas where Apache Spark is being used in Data Science is in the field of Text Analytics. Apache Spark is very well apt at handling unstructured information.
This unstructured data is mostly collected through conversations, phone calls, tweets, posts etc. In order to make sense of this information, Spark provides a scalable distributed computing platform.
Some of the various techniques that are supported by Spark for text analytics –
Text Mining
This technique involves the clustering of textual data. (i.e. Text clustering, data-driven topics)
Categorization
It involves tagging of the unstructured data into different categories and sub-categories, hierarchies and taxonomies.
Entity Extraction
This involves the extraction of patterns such as phrases, addresses, phone numbers etc.
Sentiment Analysis
In Sentiment Analysis, we tag positive, negative or neutral text with different magnitudes of sentiments.
Practice Data Science Sentiment Analysis Project for Free
Deep Linguistics
This technique involves semantics, casualty understanding, time and purpose.
Another important avenue of Data Science that is supported by Spark is Distributed Machine Learning. Spark provides support for machine learning operations through the MLlib subproject. Some of the algorithms that are available within the MLlib project are –
- Classification – Logistic Regression, linear SVM, least squares, classification trees.
- Regression – Generalized Linear Models, Regression Tree
- Collaborative Filtering – Alternating Least Squares, non-negative matrix factorization.
- Clustering – k-means clustering
- Decomposition – SVD, PCA
- Optimization Techniques – Stochastic Gradient Descent
With Spark 1.1, you can train linear models in a streaming manner as Spark supports MLlib + Streaming capability. Furthermore, Spark also supports MLlib + SQL as well as MLlib + GraphX library.
Conclusion
Apache Spark is a powerful tool used in big data and real-time data science projects. It helps process large datasets quickly across many computers. Unlike traditional tools, Spark doesn’t just read and write data—it does complex operations like filtering, aggregating, and machine learning at massive scale. Many companies use Spark to handle web logs, sensor data, or customer transactions in real-time.
Spark works with different languages like Python (using PySpark), Scala, and Java. You can build machine learning models using its MLlib library, run SQL queries, and even create dashboards using its structured streaming engine. Spark is especially useful when data is too big for one machine, or when you need fast processing like fraud detection or ad targeting. It supports in-memory processing, which makes it faster than older technologies like Hadoop MapReduce.
Learning Spark gives you the power to work with enterprise-level data. It helps you solve problems that other tools can’t handle due to scale or speed. If you’re serious about data science and want to go beyond small datasets, mastering Spark is a must. Many roles in big tech companies now demand Spark as a key skill, and having it on your resume opens doors to high-impact data projects.
So, now you know the importance of Spark for Data Scientists. What are you waiting for? Start learning Spark with industry experts and become a master of this technology.
Did we exceed your expectations?
If Yes, share your valuable feedback on Google




