Data Science at Netflix – A Must Read Case Study for Aspiring Data Scientists
Machine Learning courses with 100+ Real-time projects Start Now!!
Data Science Case Study – How Netflix Used Data Science to Improve its Recommendation System?
Do you remember the last movie you watched on Netflix? I don’t want to know the name; just think about it- after watching the movie, were you recommended of similar movies? How does Netflix know what you’d like? The secret here is Data Science.
Netflix uses Data Science to cater relevant and interesting recommendations to you. So, today, in this article, we will discuss the same. Let’s start exploring Data Science at Netflix with a basic introduction to Netflix.
Data Science at Netflix
Netflix initially started as a DVD rental service in 1998. It mostly relied on a third party postal services to deliver its DVDs to the users. This resulted in heavy losses which they soon mitigated with the introduction of their online streaming service in 2007.
In order to make this happen, Netflix invested in a lot of algorithms to provide a flawless movie experience to its users. One of such algorithms is the recommendation system that is used by Netflix to provide suggestions to the users.
A recommendation system understands the needs of the users and provides suggestions of the various cinematographic products.
What is a Recommendation System?
A recommendation system is a platform that provides its users with various contents based on their preferences and likings. A recommendation system takes the information about the user as an input.
This information can be in the form of the past usage of product or the ratings that were provided to the product. It then processes this information to predict how much the user would rate or prefer the product. A recommendation system makes use of a variety of machine learning algorithms.
Another important role that a recommendation system plays today is to search for similarity between different products. In the case of Netflix, the recommendation system searches for movies that are similar to the ones you have watched or have liked previously.
This is an important method for scenarios that involve cold start. In cold start, the company does not have much of the user data available to generate recommendations.
Therefore, based on the movies that are watched, Netflix provides recommendations of the films that share a degree of similarity. There are two main types of Recommendation Systems –
1. Content-based recommendation systems
In a content-based recommendation system, the background knowledge of the products and customer information are taken into consideration. Based on the content that you have viewed on Netflix, it provides you with similar suggestions.
For example, if you have watched a film that has a sci-fi genre, the content-based recommendation system will provide you with suggestions for similar films that have the same genre.
2. Collaborative filtering recommendation systems
Unlike the content based filtering that provided recommendations of similar products, Collaborative Filtering provides recommendations based on the similar profiles of its users. One key advantage of collaborative filtering is that it is independent of the product knowledge.
Rather, it relies on the users with a basic assumption that what the users liked in the past will also like in the future. For example, if a person A watches crime, sci-fi and thriller genres and B watches sci-fi, thriller and action genres then A will also like action and B will like crime genre.
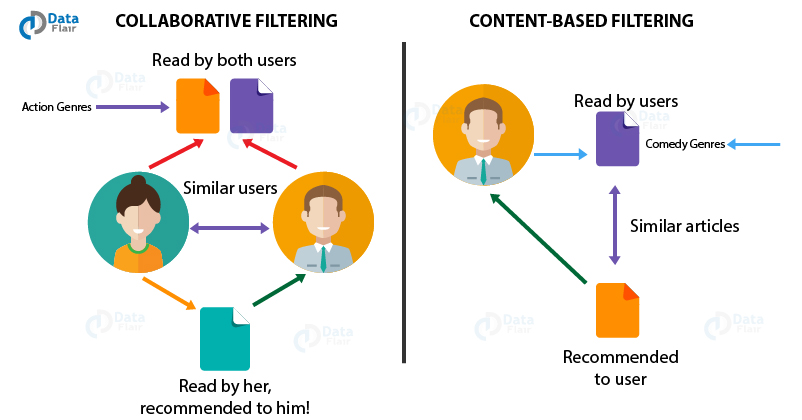
There is also a third type of recommendation system that combines both Content and Collaborative techniques. This form of recommendation system is known as Hybrid Recommendation System. Netflix makes the primary of use Hybrid Recommendation System for suggesting content to its users.
Most recommended – Marks & Spencer using Big Data to Analyze Customer Behaviour
How Netflix Solved its Recommendation Problem with Data Science
Back in 2006 when Netflix wanted to tap into the streaming market, it started off with a competition for movie rating prediction. It provided a prize of $ 1 million to whoever increased the accuracy of their then existing platform ‘Cinematch’ by 10%.
At the end of competition, the BellKor team presented their solution that increased the accuracy of prediction by 10.06%. With over 200 work hours and an ensemble of 107 algorithms provided them with this result.
Their final model gave an RMSE of 0.8712. For their solution, they made use of K-nearest neighbor algorithm for post-processing of the data.
Then they implemented a factorization model which is popularly known as Singular Value Decomposition (SVD) for providing an optimal dimensional embedding to its users.
They also made use of Restricted Boltzmann Machines (RBM) for enhancing the capability of the collaborative filtering model. These two algorithms in the ensemble, SVD and RBM provided them with the best results. A linear combination of these two algorithms reduced the RMSE to 0.88.
However, even after reduction of RMSE and increase in accuracy, Netflix suffered from two major challenges – Firstly, the data that provided during the competition comprised of 100 million movie ratings, as opposed to more than 5 billion ratings that Netflix constituted of.
Furthermore, the algorithms were static, meaning that they only dealt with historical data and did not take into account the dynamicity of users adding reviews in real-time. After Netflix overcame these challenges, it made the winning algorithms a part of its recommendation system.
Don’t struggle for your Job – Easy way to Get your FIRST JOB in Data Science
Using Interleaving to Improve Personalization
Netflix uses Ranking Algorithms to provide a ranked list of movies and TV Shows that appeal the most to its users. However, with the presence of various ranking algorithms, it is often difficult to accommodate all of them and test their performance simultaneously.
While the traditional A/B testing on a reduced set of algorithms could not identify the best algorithms with smaller sample size and also consumed a lot of time, Netflix decided to innovate its algorithmic process.
In order to speed up its experimentation process of its ranking algorithms, Netflix implemented the interleaving technique that allowed it to identify best algorithms. This technique is applied in two stages to provide the best page ranking algorithm to provide personalized recommendations to its users.
In the first stage, experimentations to determine the member preference between the two ranking algorithms is carried out. Unlike the A/B testing where the two groups of viewers are exposed to the two ranking algorithms, Netflix makes use of interleaving to blend the rankings of algorithm A and B.
Netflix provides its users with enriched content based on this interleaving technique that is highly sensitive towards ranking the algorithm quality.
Importance of Context Awareness in Recommendations
Contextual Awareness is one of the key elements in personalizing recommendations for its users.
This not only improves the performance of the recommendation system but also prompts users to provide better feedback that would result in a quality recommendation. There are two categories of contextual classes:
Explicit
- Location
- Language
- Time of the Day
- Device
Inferred
- Binging Patterns
- Companion
In order to predict contexts, we make use of representation learning. It is a deep learning technique that performs feature engineering that discovers features without explicit programming.
Based on the time and periods of watching, Netflix bases its data on various parameters like Day, Week, Season and even longer periods like Olympics, FIFA, and elections.
It is the Right Time to Upgrade your Data Science Skills
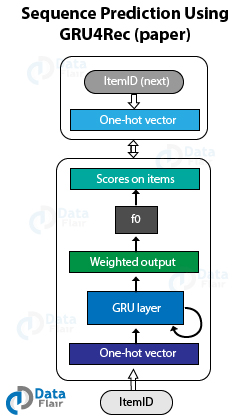
For performing contextual predictions, Netflix treats recommendations as a sequence classification problem. It takes the input as a sequence of user-actions and performs predictions that output the next set of actions.
An example of a sequence problem is Gru4Rec. And in the case of contextual sequence prediction, the input consists of the contextual user actions as well as the current context of the user. This helps the recommendation engine solve the question:
“Based on all the historical actions that are taken by the user what is the most probable video that they will play right now?”
So, this is how Netflix is using Data Science for providing recommendations.
Summary
Netflix uses Data Science to decide what you should watch next. When you watch a movie, it checks what kind of stories, actors, or languages you like. Then, it suggests shows that match your taste. This keeps users watching more and makes them happy.
It also uses data to decide which shows to make. If millions of users love crime stories, Netflix invests in more crime series. This reduces the risk of failure and ensures content that people love. It’s a smart way of using viewer data to drive success.
Netflix tracks how long you watch, when you pause, and what you skip. All this data helps improve their app and fix what’s not working. That’s why Netflix feels so personal—it’s not just guessing, it’s using smart data science.
Hope this data science case study helped you to understand Data Science in a better way. Here are some Data Science Use Cases of Flipkart, Amazon, etc. You must check them to get a clearer knowledge of Data Science.
Anything to ask? Drop queries in the comment section. We will definitely respond.
Did we exceed your expectations?
If Yes, share your valuable feedback on Google





Hi Team,
you guys done a amazing job by providing best material.
How can i make some python projects as i know basic of pythons.
Regards’
Rahul Rawat
You can work on the Top Python Projects with Source Code. The projects are designed from the beginner’s perspective, therefore, you will not have any issues while working on them.
I am an beginner to python language and this information are helpful for me to have a deep knowledge on python. thanks a lot
We are glad that you liked our data science tutorial. Share the tutorial series with your friends & colleagues and help them to become a data scientist.
I recently started off with my Masters in Big Data and iam on the process of learning new stuff. So i was checking out case studies and thats when i came across this topic. At a rookie level can you help me understand the sequence prediction using the GRU4REC as its already explained above but iam still unable to follow.
Thanks in advance.
Hi,
I have a question regarding collaborative recommendation system, As it find the similarity between the users of similar profile and provides a movie suggestion. How the system selects the users, Is it based on the geo location of the user or some other criteria ?
Thanks in advance.
Hi. My name is Pratyush Banerjee. I am an Assistant Professor at T A Pai Management Institute. I am at present writing a book on Python. I am fascinated by the case study showcased in your web-page on Netflix’s recommendation system. I humbly request you to allow me to refer to the content shared in the Netflix recommendation case study in my book. I shall cite your web-page as the source, and shall use only the information, not plagiarise what you have written. If it is all right with you to allow me to use the information, then please revert back inmmy mail stating so. Without your consent, I shall not refer to this material.
hello,
I need some help with my final project,
Final Project Guideline
• Identify a set of data that is suitable for data mining—(at least thousands of records)
• Identify business question(s) that you want to answer.
• Explore data, prepare data, and, analyze data, etc.
• Write a report to summarize the process and discuss your findings.
Final Project report:
I. Cover Page (Title and members)
II. Executive Summary
• Please summarize your findings and main techniques you used
III. Main Report
i. Introduction
• Brief introduction of the business problem
ii. Data exploration and data preparation
• Describe the data and any steps you take to prepare data
iii. Data analysis
• Explain data mining technique(s) you explored and chose
• Show models results
• Assess model performance
iv. Findings and Conclusions
• Discuss the findings/results
• Make recommendations
Sir i want this project base paper (journal paper)
I really love all your posts. You have explained ever concept in a very simple way. I have yrs of experience in Medical coding filed. If I switch my career to Data Science Will I be considered as fresher? Can you please help me to grow in this filed. I have completed my Masters Certification in Data science through online boot camp