Directed Acyclic Graph DAG in Apache Spark
1. Objective
In this Apache Spark tutorial, we will understand what is DAG in Apache Spark, what is DAG Scheduler, what is the need of directed acyclic graph in Spark, how to create DAG in Spark and how it helps in achieving fault tolerance. We will also learn how DAG works in RDD, the advantages of DAG in Spark which creates the difference between Apache Spark and Hadoop MapReduce.
(Directed Acyclic Graph) DAG in Apache Spark is a set of Vertices and Edges, where vertices represent the RDDs and the edges represent the Operation to be applied on RDD. In Spark DAG, every edge directs from earlier to later in the sequence. On the calling of Action, the created DAG submits to DAG Scheduler which further splits the graph into the stages of the task.
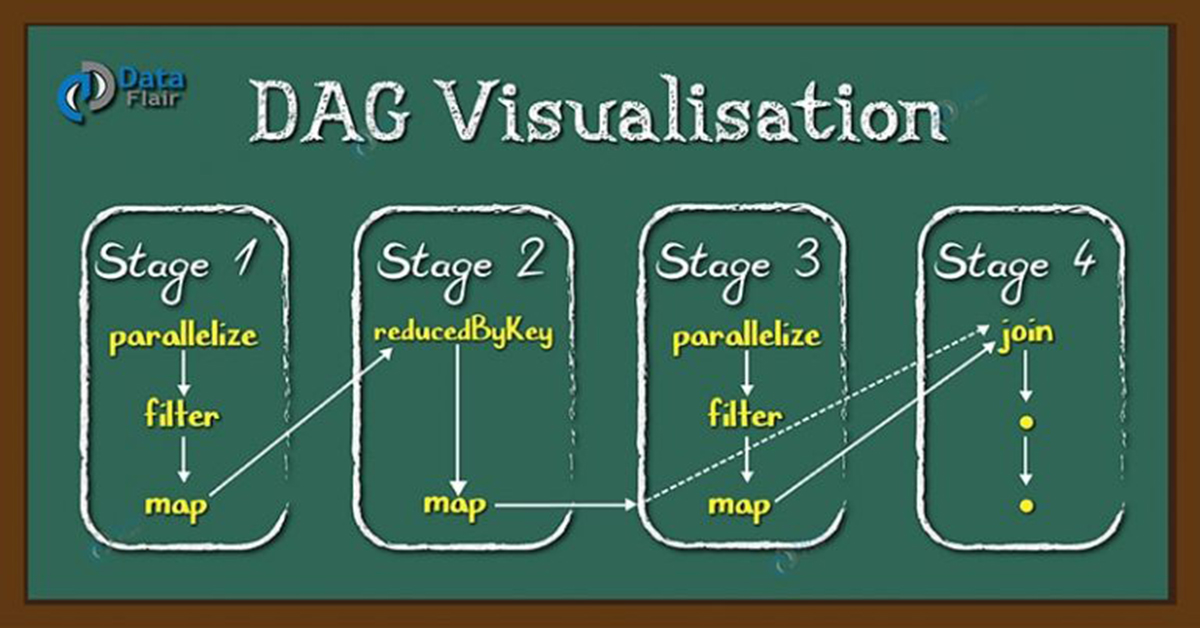
Directed Acyclic Graph DAG in Apache Spark
2. What is DAG in Apache Spark?
DAG a finite direct graph with no directed cycles. There are finitely many vertices and edges, where each edge directed from one vertex to another. It contains a sequence of vertices such that every edge is directed from earlier to later in the sequence. It is a strict generalization of MapReduce model. DAG operations can do better global optimization than other systems like MapReduce. The picture of DAG becomes clear in more complex jobs.
Apache Spark DAG allows the user to dive into the stage and expand on detail on any stage. In the stage view, the details of all RDDs belonging to that stage are expanded. The Scheduler splits the Spark RDD into stages based on various transformation applied. (You can refer this link to learn RDD
Transformations and Actions in detail) Each stage is comprised of tasks, based on the partitions of the RDD, which will perform same computation in parallel. The graph here refers to navigation, and directed and acyclic refers to how it is done.
3. Need of Directed Acyclic Graph in Spark
The limitations of Hadoop MapReduce became a key point to introduce DAG in Spark. The computation through MapReduce in three steps:
- The data is read from HDFS.
- Then apply Map and Reduce operations.
- The computed result is written back to HDFS.
Each MapReduce operation is independent of each other and HADOOP has no idea of which Map reduce would come next. Sometimes for some iteration, it is irrelevant to read and write back the immediate result between two map-reduce jobs. In such case, the memory in stable storage (HDFS) or disk memory gets wasted.
In multiple-step, till the completion of the previous job all the jobs block from the beginning. As a result, complex computation can require a long time with small data volume.
While in Spark, a DAG (Directed Acyclic Graph) of consecutive computation stages is formed. In this way, we optimize the execution plan, e.g. to minimize shuffling data around. In contrast, it is done manually in MapReduce by tuning each MapReduce step.
4. How DAG works in Spark?
- The interpreter is the first layer, using a Scala interpreter, Spark interprets the code with some modifications.
- Spark creates an operator graph when you enter your code in Spark console.
- When we call an Action on Spark RDD at a high level, Spark submits the operator graph to the DAG Scheduler.
- Divide the operators into stages of the task in the DAG Scheduler. A stage contains task based on the partition of the input data. The DAG scheduler pipelines operators together. For example, map operators schedule in a single stage.
- The stages pass on to the Task Scheduler. It launches task through cluster manager. The dependencies of stages are unknown to the task scheduler.
- The Workers execute the task on the slave.
The image below briefly describes the steps of How DAG works in the Spark job execution.
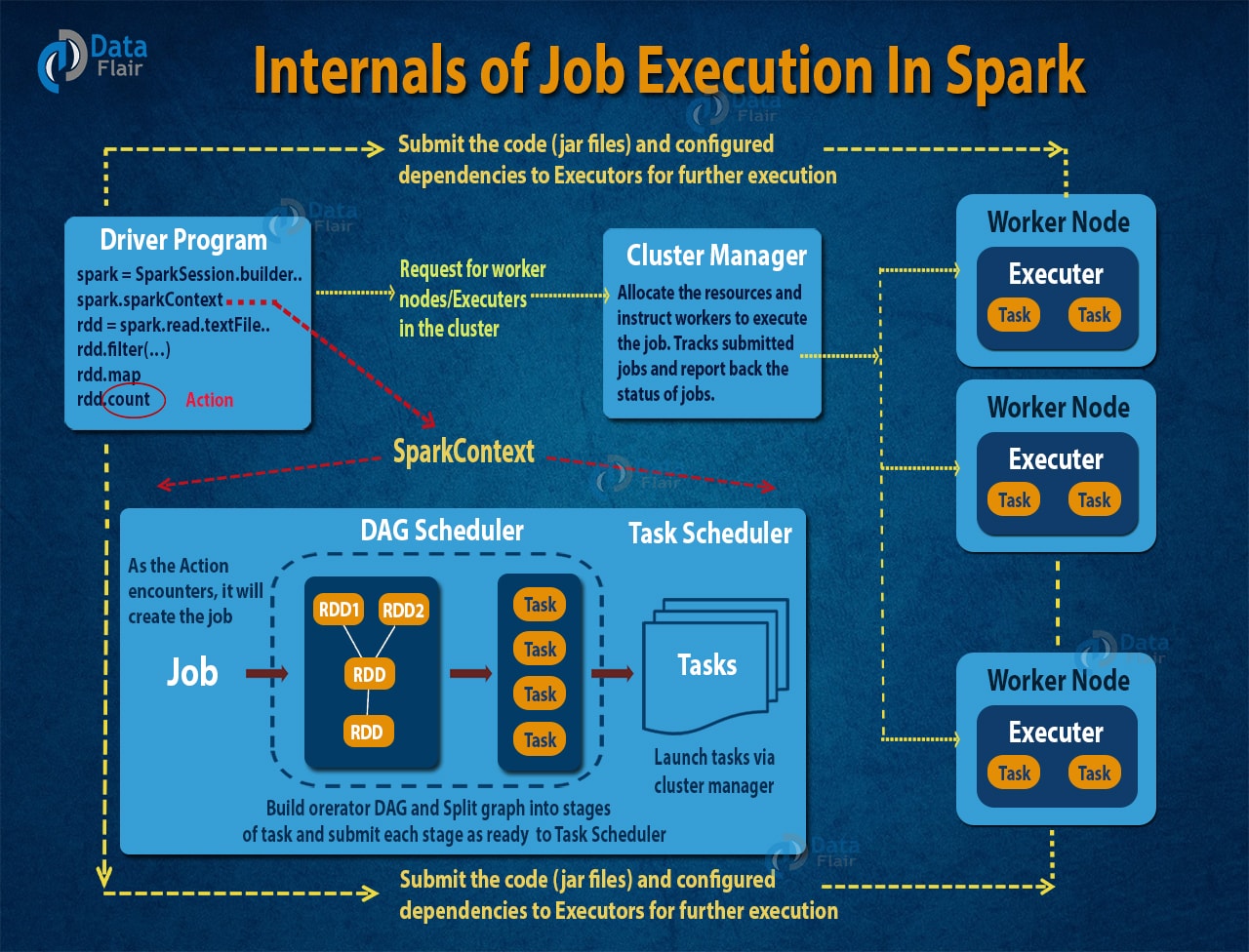
An Introduction to Job execution flow in Apache Spark
At higher level, we can apply two type of RDD transformations: narrow transformation (e.g. map(), filter() etc.) and wide transformation (e.g. reduceByKey()). Narrow transformation does not require the shuffling of data across a partition, the narrow transformations will group into single stage while in wide transformation the data shuffles. Hence, Wide transformation results in stage boundaries.
Each RDD maintains a pointer to one or more parent along with metadata about what type of relationship it has with the parent. For example, if we call val b=a.map() on an RDD, the RDD b keeps a reference to its parent RDD a, that’s an RDD lineage.
5. How to Achieve Fault Tolerance through DAG?
RDD splits into the partition and each node operates on a partition at any point in time. Here, the series of Scala function executes on a partition of the RDD. These operations compose together and Spark execution engine view these as DAG (Directed Acyclic Graph).
When any node crashes in the middle of any operation say O3 which depends on operation O2, which in turn O1. The cluster manager finds out the node is dead and assign another node to continue processing. This node will operate on the particular partition of the RDD and the series of operation that it has to execute (O1->O2->O3). Now there will be no data loss.
You can refer this link to learn Fault Tolerance in Apache Spark.
6. Working of DAG Optimizer in Spark
We optimize the DAG in Apache Spark by rearranging and combining operators wherever possible. For, example if we submit a spark job which has a map() operation followed by a filter operation. The DAG Optimizer will rearrange the order of these operators since filtering will reduce the number of records to undergo map operation.
7. Advantages of DAG in Spark
There are multiple advantages of Spark DAG, let’s discuss them one by one:
- The lost RDD can recover using the Directed Acyclic Graph.
- Map Reduce has just two queries the map, and reduce but in DAG we have multiple levels. So to execute SQL query, DAG is more flexible.
- DAG helps to achieve fault tolerance. Thus we can recover the lost data.
- It can do a better global optimization than a system like Hadoop MapReduce.
8. Conclusion
DAG in Apache Spark is an alternative to the MapReduce. It is a programming style used in distributed systems. In MapReduce, we just have two functions (map and reduce), while DAG has multiple levels that form a tree structure. Hence, DAG execution is faster than MapReduce because intermediate results does not write to disk.
If in case you have any confusion about DAG in Apache Spark, then feel free to share with us. We will be glad to solve your queries.
See Also-
Reference:
http://spark.apache.org/
Did you know we work 24x7 to provide you best tutorials
Please encourage us - write a review on Google


What if the dag becomes too large will it reduce the performance ? In spark sql if we do A join B = C then C join D= E and so on it is not giving good performance .
Really grt information source for data scientist
Glad Vaibhav. We appreciate you for this positive feedback on Spark DAG and we are happy that you find our DAG Spark Article helpful for Data Scientist. You can explore more on Apache Spark, keep visiting Data Flair.
Hi all, here every person is sharing such experience,
so it’s good to read this blog, and I used to pay a visit this website all the
time.
Hii Cheri,
Thank you for visiting Data Flair regularly and reading the complete DAG Spark Article. Really glad to hear such positive words for our Spark Tutorial. Cheri, if you find any query while reading Spark or any other technology, feel free to share with us.
Its very good & helpful information. Thanks for sharing.
Compared to hadoop it will be still efficient and faster
Hello ! I really enjoyed a lot reading through your spark notes and I truly appreciate all the efforts you and your team has put through. Just one suggestion here in regards to content writing, which I observed as there were a lot of areas which needs further sophistication on the writing style. Since me being a technical guy I wouldn’t worry much about it but if you think you up for it then please do look into fine tuning the grammar usage.
Please do not apply video ads on this page. This is creating so much disturbance while reading.
btw thank you for providing such great content!!..
Thank you for making good article. Very good contents, easy-to-understand explanations.
(You have typo, ‘orerator’ in figure “An Introduction to Job execution flow in Apache Spark”)
hi