HBase Tutorial For Beginners | Learn Apache HBase in 12 min
Let’s explore the new trending technology i.e. Apache HBase. Today, in this Apache HBase tutorial, we will see HBase introduction and find out why HBase is popular. Moreover, we will see HBase history and why we should learn HBase Programming.
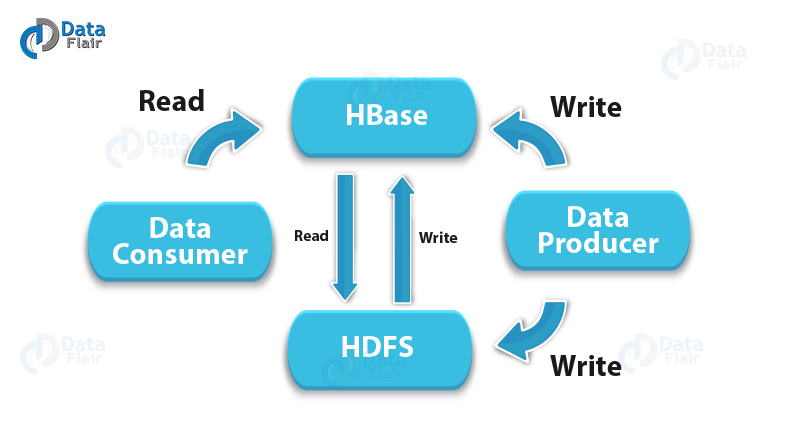
HBase is part of the Hadoop ecosystem which offers random real-time read/write access to data in the Hadoop File System.
Also, this HBase tutorial teaches us how to use HBase. Along with this, we will discuss HBase features & architecture of HBase. At last, we will learn comparisons in HBase technology. So, in this HBase tutorial, we will learn the whole concept of Apache HBase.
So, let’ s start Apache HBase tutorial.
What is Apache HBase?
HBase is a Hadoop project which is Open Source, distributed Hadoop database which has its genesis in the Google’sBigtable.
- Its programming language is Java.
- Now, it is an integral part of the Apache Software Foundation and the Hadoop ecosystem.
- Also, it is a high availability database which exclusively runs on top of the HDFS.
- It is a column-oriented database built on top of HDFS.
HBase Tutorial – What is HBase
Moreover, HBase is an extremely fault-tolerant way as well as good for storing sparse data. On defining Sparse data, it is something like looking for a piece of a specific paper in a huge pile of documents.
HBase Tutorial – History
- Initially, in Nov 2006, Google released the paper on BigTable.
- The first HBase prototype was created as a Hadoop contribution in the year Feb 2007.
- The first usable HBase was released in the same year Oct 2007 along with Hadoop 0.15.0.
- HBase became the subproject of Hadoop, in Jan 2008.
- In the year 2010, May HBase became Apache top-level project.
Why Apache HBase?
HBase features like working with sparse data in an extremely fault-tolerant and resilient way and the way it can work on multiple types of data also making it useful for varied business scenarios.
i. Prerequisites
- Hadoop’s architecture and APIs
- Know to write basic applications using Java
- Working knowledge of any database.
ii. Right Audience
- Those who are Software developers and Mainframe professionals.
- Moreover, Project managers, Big Data analysts as well as Testing professionals.
- Also, Java Developers and Data Management Professional.
Why should you use HBase Technology?
Along with HDFS and MapReduce, HBase is one of the core components of the Hadoop ecosystem. Here are some salient features of HBase which make it significant to use:
- Apache HBase has a completely distributed architecture.
- It can easily work on extremely large scale data.
- HBase offers high security and easy management which results in unprecedented high write throughput.
- For both structured and semi-structured data types we can use it.
- Moreover, the MapReduce jobs can be backed with HBase Tables.
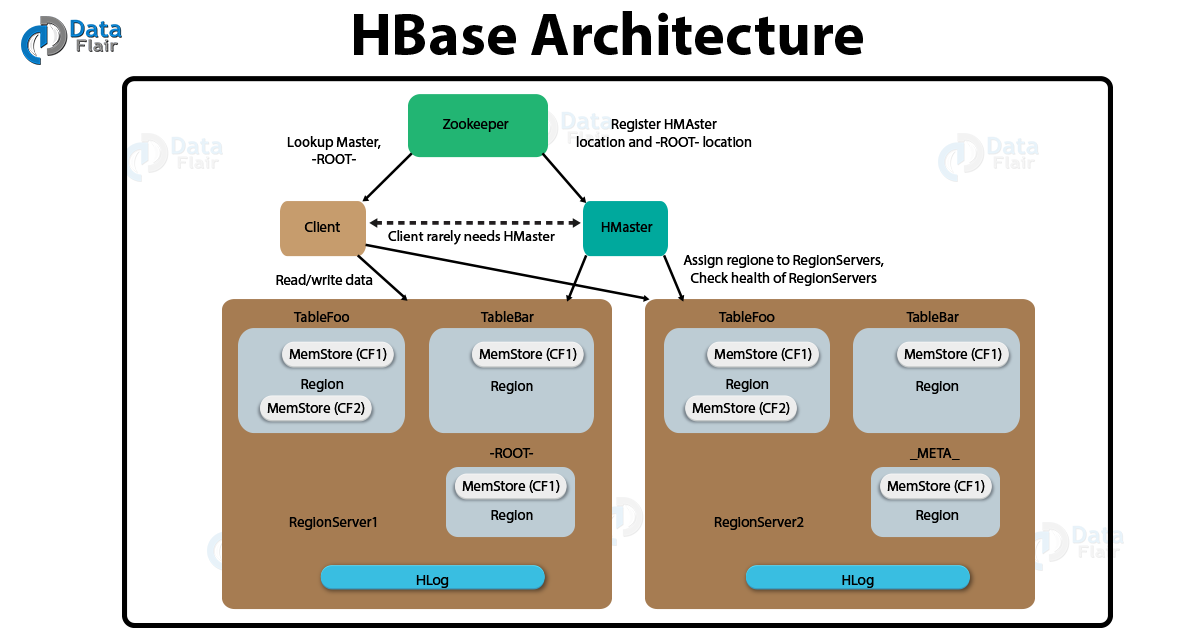
Apache HBase Architecture
HBase Architecture is basically a column-oriented key-value data store and also it is the natural fit for deploying as a top layer on HDFS because it works extremely fine with the kind of data that Hadoop process.
Moreover, when it comes to both read and write operations it is extremely fast and even it does not lose this extremely important quality with humongous datasets.
There are 3 major components of HBase Architecture:
- Zookeeper
- HMaster server
- Region servers
HBase tutorial – The architecture of Apache HBase
HBase Tutorial – Storage Mechanism
Basically, HBase is a column-oriented database. Moreover, the tables in it are sorted by row. Here, the table schema defines only column families, which are the key-value pairs. However, it is possible that a table has multiple column families and here each column family can have any number of columns.
Moreover, here on the disk, subsequent column values are stored contiguously. And, also each cell value of the table has a timestamp here.
In an HBase:
- The table refers to the collection of rows.
- Row refers to the collection of column families.
- Column family refers to the collection of columns.
- The column refers to the collection of key-value pairs.
Databases in HBase which store data tables as sections of columns of data, instead of rows of data are Column-oriented Databases. In simple words, they will have column families.
- Column-Oriented vs Row Oriented
a. Suitable for
- Row Oriented
Especially for Online Transaction Process (OLTP).
- Column-Oriented
Whereas it is the right choice for Online Analytical Processing (OLAP).
b. Designed for
- Row Oriented
It is designed for the small number of rows and columns.
- Column-Oriented
Whereas it is designed for huge tables.
HBase Features
Below given are some important features of Apache HBase are:
- Apache HBase is linearly scalable.
- Moreover, it provides automatic failure support.
- It also offers consistent read and writes.
- We can integrate it with Hadoop, both as a source as well as the destination.
- Also, it has easy java API for the client.
- HBase also offers data replication across clusters.
Uses of HBase
Most Use cases of Apache HBase are:
- While we want to have random, real-time read/write access to Big Data, we use Apache HBase.
- It is possible to host very large tables on top of clusters of commodity hardware with Apache HBase.
- After Google’s Bigtable, HBase is a non-relational database modeled. Basically, as Bigtable acts up on Google File System, in same way HBase works on top of Hadoop and HDFS.
Applications of HBase
Here, we are listing some applications of HBase:
- While it is must write-heavy applications, we can use Apache HBase.
- Moreover, while we need to provide fast random access to available data, we use HBase.
- Also, some companies use HBase internally, like Facebook, Twitter, Yahoo, and Adobe etc.
HBase Comparisons
Below given are some comparisons with HBase Technology:
i. HBase vs HDFS

HBase Tutorial –
a. Built on
- HBase
It is built on top of the HDFS.
- HDFS
Whereas, it is suitable for storing large files.
b. lookups
- HBase
Basically, for larger tables, it offers fast lookups.
- HDFS
Whereas, HDFS does not offer fast lookups.
C. Latency
- HBase
HBase offers low latency access.
- HDFS
Moreover, it offers high latency batch processing; but does not support batch processing.
ii. HBase vs RDBMS
HBase vs HDFS
a. Structure
- HBase
It is schema-less
- RDBMS
Generally, it is governed by its schema, that describes the whole structure of tables.
b. Scalability
- HBase
It is built for wide tables. Moreover, it is horizontally scalable.
- RDBMS
Whereas, RDBMS is thin and built for small tables. And it is Hard to scale.
c. Transaction
- HBase
There are No transactions in HBase.
- RDBMS
Whereas, it is transactional.
D. Data Type
- HBase
HBase is good for both semi-structured as well as structured data.
- RDBMS
RDBMS is very good for structured data only.
HBase Tutorial – Career in HBase
As we know, day by day Hadoop deployment is rising and we can say HBase is the perfect platform for working on top of the HDFS (Hadoop Distributed File System). Hence, at this time, learning HBase will be very helpful in growth.
Even companies are looking for candidates who can deploy HBase data models at scale on large Hadoop clusters consisting of commodity hardware.
So, learning this HBase technology will help us to perform several operations, like deploy Load Utility to load a file, integrate it with Hive, learn about the HBase API and the HBase Shell. Hence, learning it will take our career to the next level.
So, this was all in HBase tutorial. Hope you like our explanation.
Conclusion
Hence, in this HBase tutorial, we saw the whole concept of HBase in this introductory guide. Moreover, we discussed the HBase introduction, uses, architecture, and features.
Keep visiting DataFlair for more tutorial blogs on HBase Technology. Next, we will see HBase Architecture. Also, if any doubt occurs, feel free to ask in the comment type.
Your opinion matters
Please write your valuable feedback about DataFlair on Google




