How Hadoop MapReduce Works – MapReduce Tutorial
1. Objective
MapReduce is the core component of Hadoop that process huge amount of data in parallel by dividing the work into a set of independent tasks. In MapReduce data flow in step by step from Mapper to Reducer. In this tutorial, we are going to cover how Hadoop MapReduce works internally?
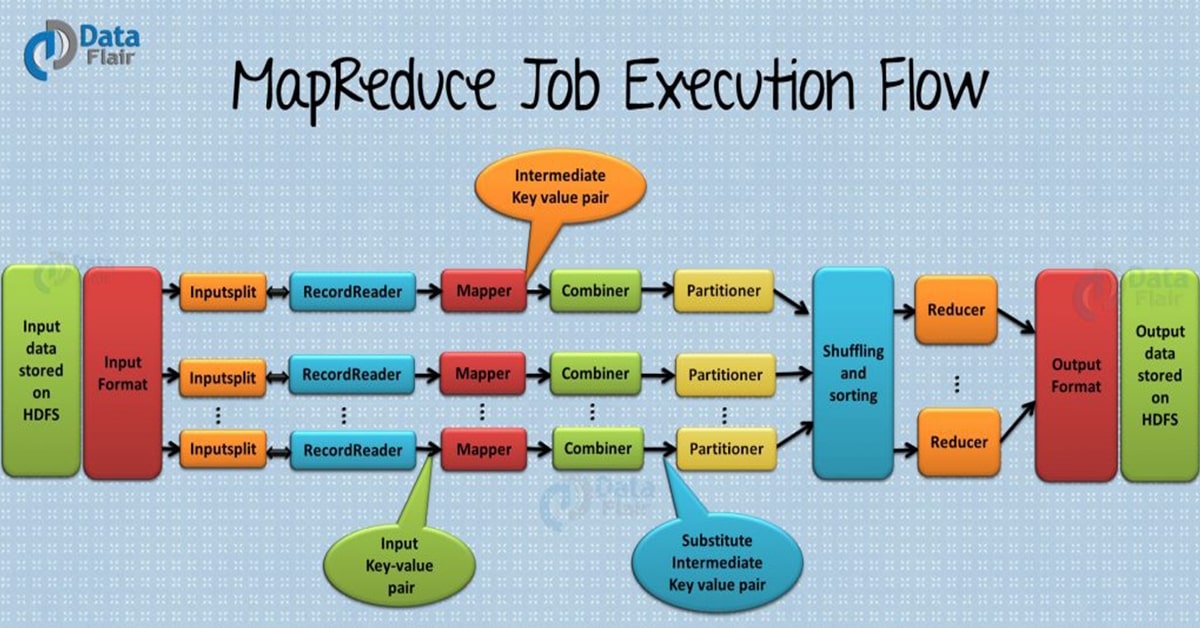
This blog on Hadoop MapReduce data flow will provide you the complete MapReduce data flow chart in Hadoop. The tutorial covers various phases of MapReduce job execution such as Input Files, InputFormat in Hadoop, InputSplits, RecordReader, Mapper, Combiner, Partitioner, Shuffling and Sorting, Reducer, RecordWriter and OutputFormat in detail. We will also learn How Hadoop MapReduce works with the help of all these phases.
How Hadoop MapReduce Works – MapReduce Tutorial
2. What is MapReduce?
MapReduce is the data processing layer of Hadoop. It is a software framework for easily writing applications that process the vast amount of structured and unstructured data stored in the Hadoop Distributed Filesystem (HDFS). It processes the huge amount of data in parallel by dividing the job (submitted job) into a set of independent tasks (sub-job). By this parallel processing speed and reliability of cluster is improved. We just need to put the custom code (business logic) in the way map reduce works and rest things will be taken care by the engine.
3. How Hadoop MapReduce Works?
In Hadoop, MapReduce works by breaking the data processing into two phases: Map phase and Reduce phase. The map is the first phase of processing, where we specify all the complex logic/business rules/costly code. Reduce is the second phase of processing, where we specify light-weight processing like aggregation/summation.
4. MapReduce Flow Chart
Now let us see How Hadoop MapReduce works by understanding the end to end Hadoop MapReduce job execution flow with components in detail:
4.1. Input Files
The data for a MapReduce task is stored in input files, and input files typically lives in HDFS. The format of these files is arbitrary, while line-based log files and binary format can also be used.
4.2. InputFormat
Now, InputFormat defines how these input files are split and read. It selects the files or other objects that are used for input. InputFormat creates InputSplit. Learn MapReduce InputFormat in detail.
4.3. InputSplits
It is created by InputFormat, logically represent the data which will be processed by an individual Mapper (We will understand mapper below). One map task is created for each split; thus the number of map tasks will be equal to the number of InputSplits. The split is divided into records and each record will be processed by the mapper. Learn MapReduce InputSplit in detail.
4.4. RecordReader
It communicates with the InputSplit in Hadoop MapReduce and converts the data into key-value pairs suitable for reading by the mapper. By default, it uses TextInputFormat for converting data into a key-value pair. RecordReader communicates with the InputSplit until the file reading is not completed. It assigns byte offset (unique number) to each line present in the file. Further, these key-value pairs are sent to the mapper for further processing.
4.5. Mapper
It processes each input record (from RecordReader) and generates new key-value pair, and this key-value pair generated by Mapper is completely different from the input pair. The output of Mapper is also known as intermediate output which is written to the local disk. The output of the Mapper is not stored on HDFS as this is temporary data and writing on HDFS will create unnecessary copies (also HDFS is a high latency system). Mappers output is passed to the combiner for further process
Follow this link to learn Data read and write operation in HDFS.
4.6. Combiner
The combiner is also known as ‘Mini-reducer’. Hadoop MapReduce Combiner performs local aggregation on the mappers’ output, which helps to minimize the data transfer between mapper and reducer (we will see reducer below). Once the combiner functionality is executed, the output is then passed to the partitioner for further work. Learn MapReduce Combiner in detail.
4.7. Partitioner
Hadoop MapReduce, Partitioner comes into the picture if we are working on more than one reducer (for one reducer partitioner is not used).
Partitioner takes the output from combiners and performs partitioning. Partitioning of output takes place on the basis of the key and then sorted. By hash function, key (or a subset of the key) is used to derive the partition.
According to the key value in MapReduce, each combiner output is partitioned, and a record having the same key value goes into the same partition, and then each partition is sent to a reducer. Partitioning allows even distribution of the map output over the reducer. Learn MapReduce Partitioner in detail.
4.8. Shuffling and Sorting
Now, the output is Shuffled to the reduce node (which is a normal slave node but reduce phase will run here hence called as reducer node). The shuffling is the physical movement of the data which is done over the network. Once all the mappers are finished and their output is shuffled on the reducer nodes, then this intermediate output is merged and sorted, which is then provided as input to reduce phase.
4.9. Reducer
It takes the set of intermediate key-value pairs produced by the mappers as the input and then runs a reducer function on each of them to generate the output. The output of the reducer is the final output, which is stored in HDFS. Follow this link to learn about Reducer in detail.
4.10. RecordWriter
It writes these output key-value pair from the Reducer phase to the output files.
4.11. OutputFormat
The way these output key-value pairs are written in output files by RecordWriter is determined by the OutputFormat. OutputFormat instances provided by the Hadoop are used to write files in HDFS or on the local disk. Thus the final output of reducer is written on HDFS by OutputFormat instances.
Hence, in this manner, a Hadoop MapReduce works over the cluster.
5. Conclusion
In conclusion, we can say that data flow in MapReduce is the combination of different processing phases of such as Input Files, InputFormat in Hadoop, InputSplits, RecordReader, Mapper, Combiner, Partitioner, Shuffling and Sorting, Reducer, RecordWriter, and OutputFormat. Hence all these components play an important role in the Hadoop mapreduce working.
Since you understand the end to end Mapreduce job flow, test your knowledge by playing the Hadoop Quiz.
If you like this blog or have any query to understand how Hadoop MapReduce works, so leave a comment in a section below. We will be glad to solve them.
See Also-
Your opinion matters
Please write your valuable feedback about DataFlair on Google





This was informative. Please allow me to add to this discussion. Have you heard about Binfer? It is an easy way to transfer big data.
very good tutorial
Good Explanation on Map Reduce part .
Beautifully explained in a comprehensive manner. Hope to see such posts more.
Thanks
Thank you so much,all my doubts got Cleared