Spark Installation in Standalone Mode | Install Apache Spark
1. Objective – Apache Spark Installation
This tutorial contains steps for Apache Spark Installation in Standalone Mode on Ubuntu. The Spark standalone mode sets the system without any existing cluster management software. For example Yarn Resource Manager / Mesos. We have spark master and spark worker who divides driver and executors for Spark application in Standalone mode.
So, let’s start Spark Installation in Standalone Mode.

Spark Installation in Standalone Mode | Install Apache Spark
2. Steps to Apache Spark Installation in Standalone Mode
Let’s Follow the steps given below for Apache Spark Installation in Standalone Mode-
i. Platform
a. Platform Requirements
Operating system: Ubuntu 14.04 or later, we can also use other Linux flavors like CentOS, Redhat, etc.
b. Configure & Setup Platform
If you are using Windows / Mac Operating System, so, you can create a virtual machine and install Ubuntu using VMWare Player, or you can create a virtual machine and install Ubuntu using Oracle Virtual Box.
ii. Software you need to install before installing Spark
a. Install Java
You need to install Java before Spark installation. So, let’s begin by installing Java. So, use the below command to download and install Java-
[php]$ sudo apt-get install python-software-properties[/php]
[php]$ sudo apt-add-repository ppa:webupd8team/java[/php]
[php]$ sudo apt-get update[/php]
[php]$ sudo apt-get install oracle-java7-installer[/php]
On executing this command Java gets start downloading and gets installed.
To check whether installation procedure gets completed and a completely working Java is installed or not and to know the version of Java installed we have to use the below command-
[php] $ java -version[/php]
b. Installing Scala
Download Scala
Download the latest version of Scala from http://www.scala-lang.org/
Apache Spark is written in Scala, so we need to install Scala to built Spark. Follow the steps given below for installing Scala.
Untar the file
[php] $ sudo tar xvf scala-2.10.4.tgz [/php]
Edit Bashrc file
Make an entry for Scala in .bashrc file
[php] nano ~/.bashrc[/php]
And add the following path at the end of the file. It means adding the location, where the Scala software file are located to the PATH variable.
[php] export SCALA_HOME=Path-where-scala-file-is-located[/php]
[php] export PATH=$PATH:$SCALA_HOME/bin[/php]
Source the changed .bashrc file by the command
[php] source ~/.bashrc[/php]
Verifying Scala Installation
After installation, it is good to verify it. Use the following command for verifying Scala installation.
[php] $scala -version[/php]
iii. Installing Spark
Install Spark in standalone mode on a Single node cluster – for Apache Spark Installation in Standalone Mode, simply place Spark setup on the node of the cluster and extract and configure it. Follow this guide If you are planning to install Spark on a multi-node cluster.
a. Download Spark
Download the latest version of Spark from http://spark.apache.org/downloads.html of your choice from the Apache Spark website.
Follow the steps given below for installing Spark.
b. Extracting Spark tar
Use the following command for extracting the spark tar file.
[php] $ tar xvf spark-2.0.0-bin-hadoop2.6.tgz[/php]
c. Setting up the environment for Spark
Make an entry for Spark in .bashrc file
[php]nano ~/.bashrc[/php]
Add the following line to the ~/.bashrc file. It means adding the location, where the spark software files are located to the PATH variable.
[php] export SPARK_HOME=/home/sapna/spark-2.0.0-bin-hadoop2.6/
export PATH=$PATH:$SPARK_HOME/bin[/php]
Use the following command for sourcing the ~/.bashrc file.
[php] $ source ~/.bashrc[/php]
iv. Start Spark Services
a. Starting a Cluster Manually
Now, start a standalone master server by executing-
[php]./sbin/start-master.sh [/php]
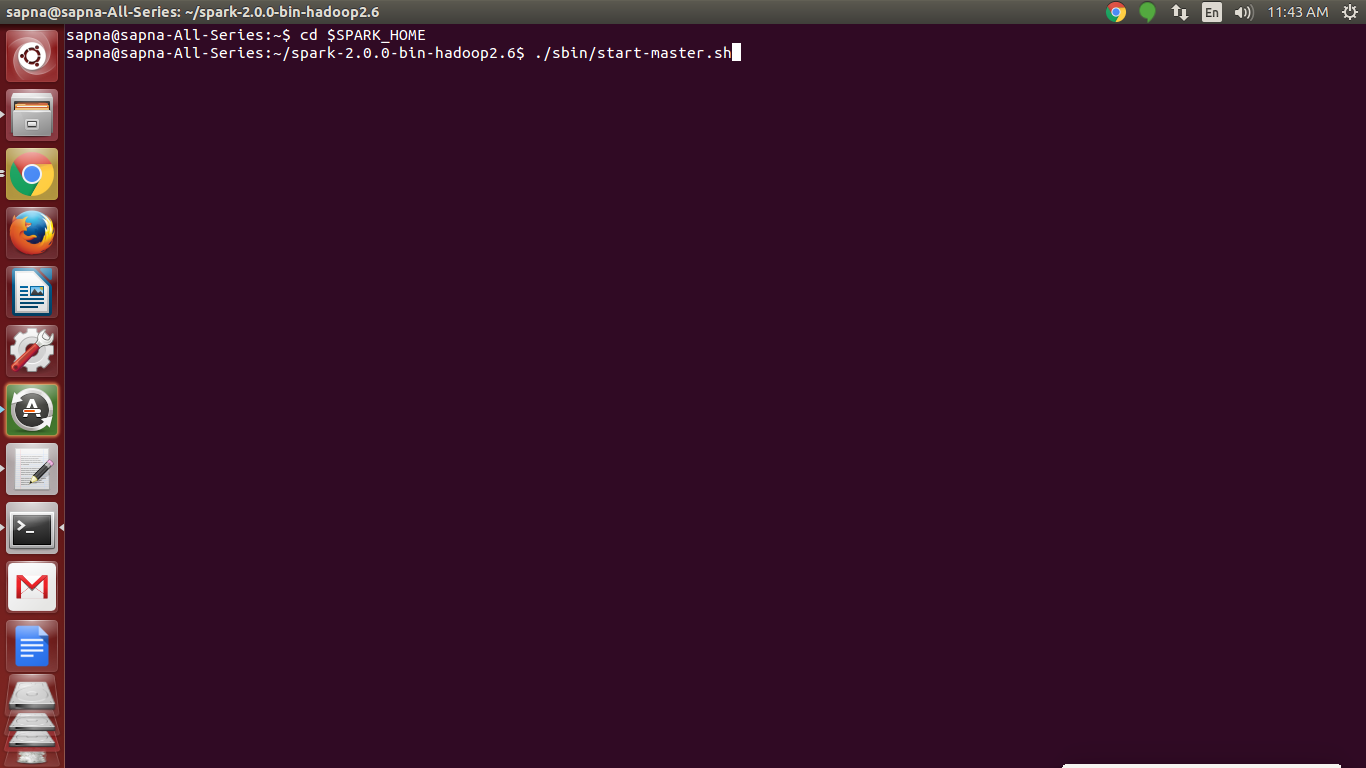
Spark Installation – Starting a standalone master server
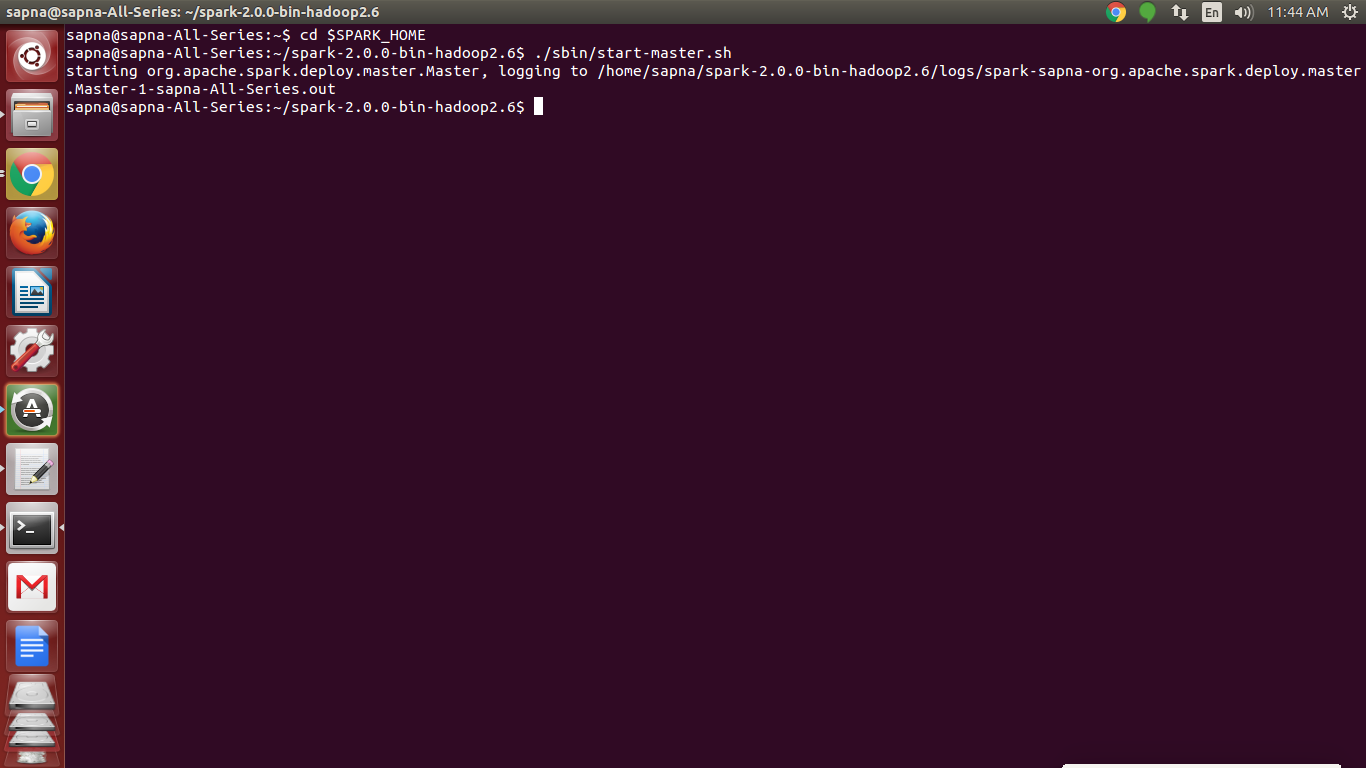
Spark Installation – Start a standalone master server
Apache Spark Installation in Standalone Mode
After running, the master will print out a spark://HOST:PORT URL for itself,
which can be used to connect workers to it, or pass as the “master” argument to SparkContext.
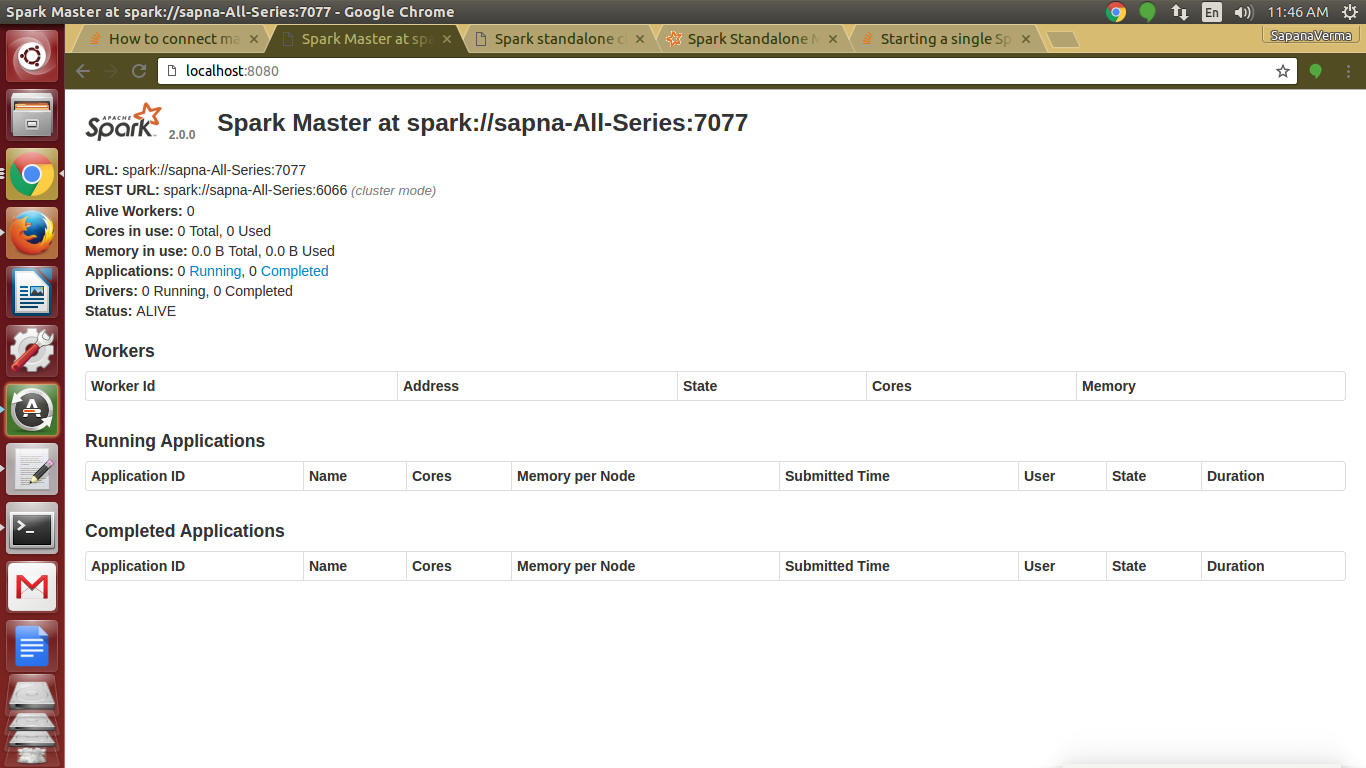
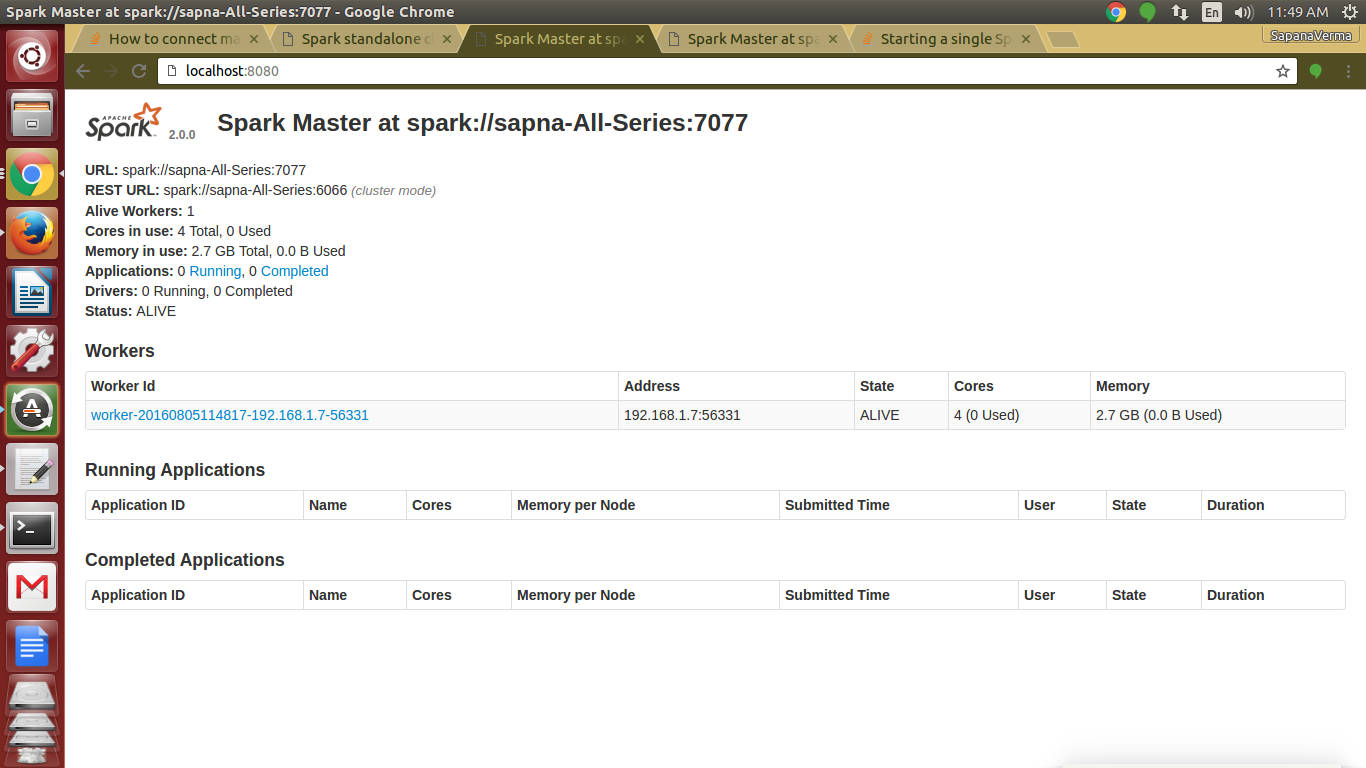
You will get this URL on the master’s web UI, which is http://localhost:8080
Preview of web console of master using local http://localhost:8080
Spark Installation – Preview of web console of master
Similarly, you can start one or more workers and connect them to the master via-
./sbin/start-slave.sh <master-spark-URL>
[php]./sbin/start-slave.sh spark://sapna-All-Series:7077[/php]
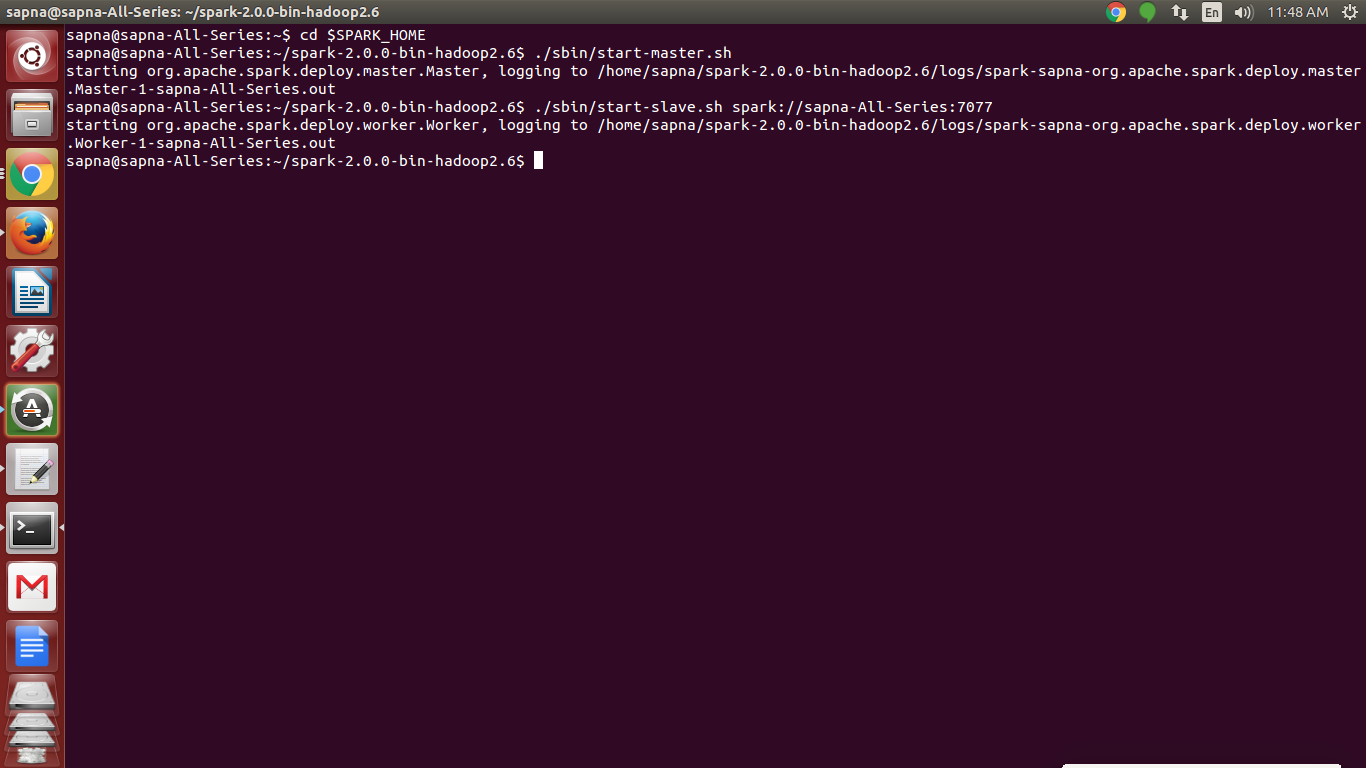
Spark Installation – start one or more workers and connect them to the master
Spark Installation
Note: You can copy master-spark-Url from master web console (http://localhost:8080)
b. Check whether Spark daemons are working
[php]jps
7698 Master
4582 Worker
[/php]
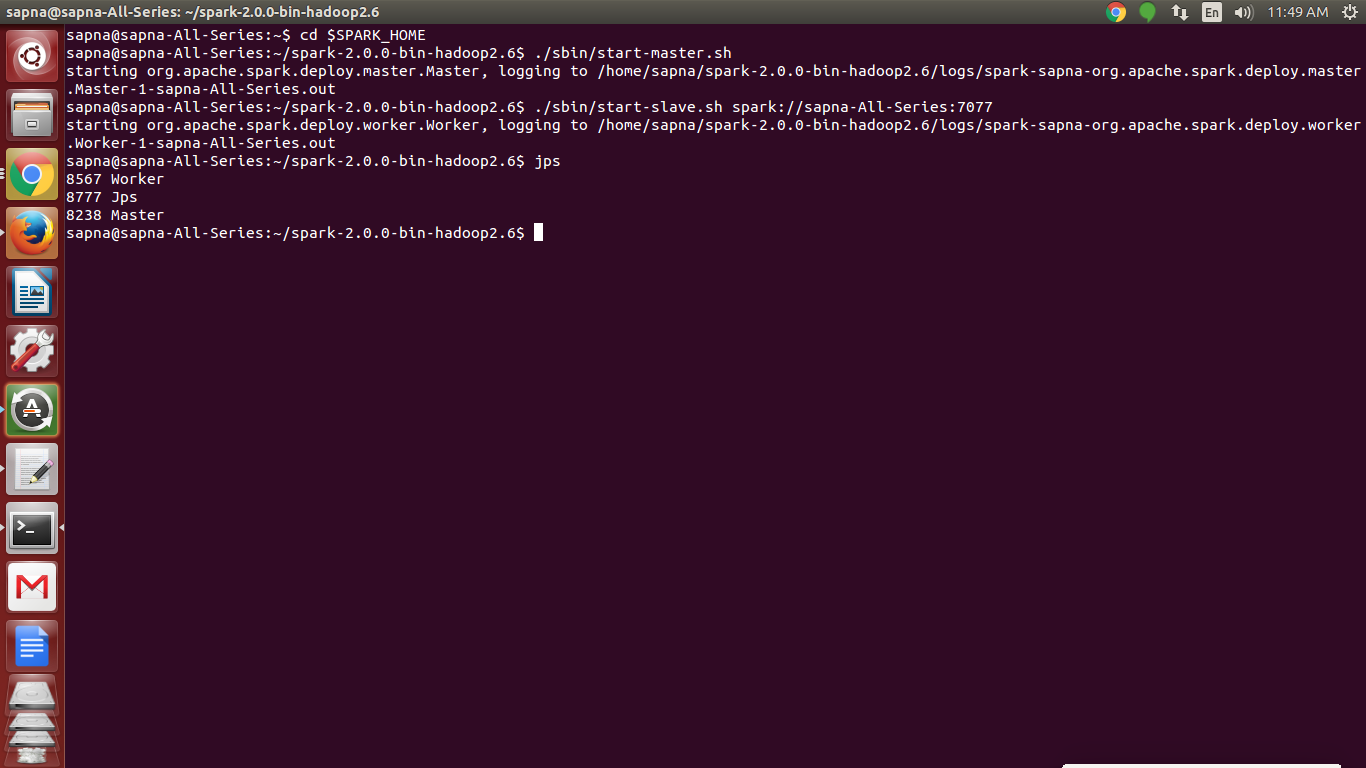
Spark Installation – Check whether the Spark daemons are working or not
v. Running sample Spark application
Once you have done Apache Spark Installation in Standalone Mode Let’s run Apache Spark Pi example (the jar for the example is shipped with Spark)
[php]./bin/spark-submit –class org.apache.spark.examples.SparkPi –master spark://sapna-All-Series:7077 –executor-memory 1G –total-executor-cores 1 /home/sapna/spark-2.0.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.0.0.jar 10[/php]
–class: The entry point for your application.
–master: The master URL for the cluster.
–executor-memory: Specify memory to be allocated for the application.
–total-executor-cores: Specify no. of CPU cores to be allocated for the application.

Spark Installation – Apache Spark Pi example
Result:
Pi is roughly 3.141803141803142
vi. Starting the Spark Shell
[php]$ bin/spark-shell spark://sapna-All-Series:7077[/php]
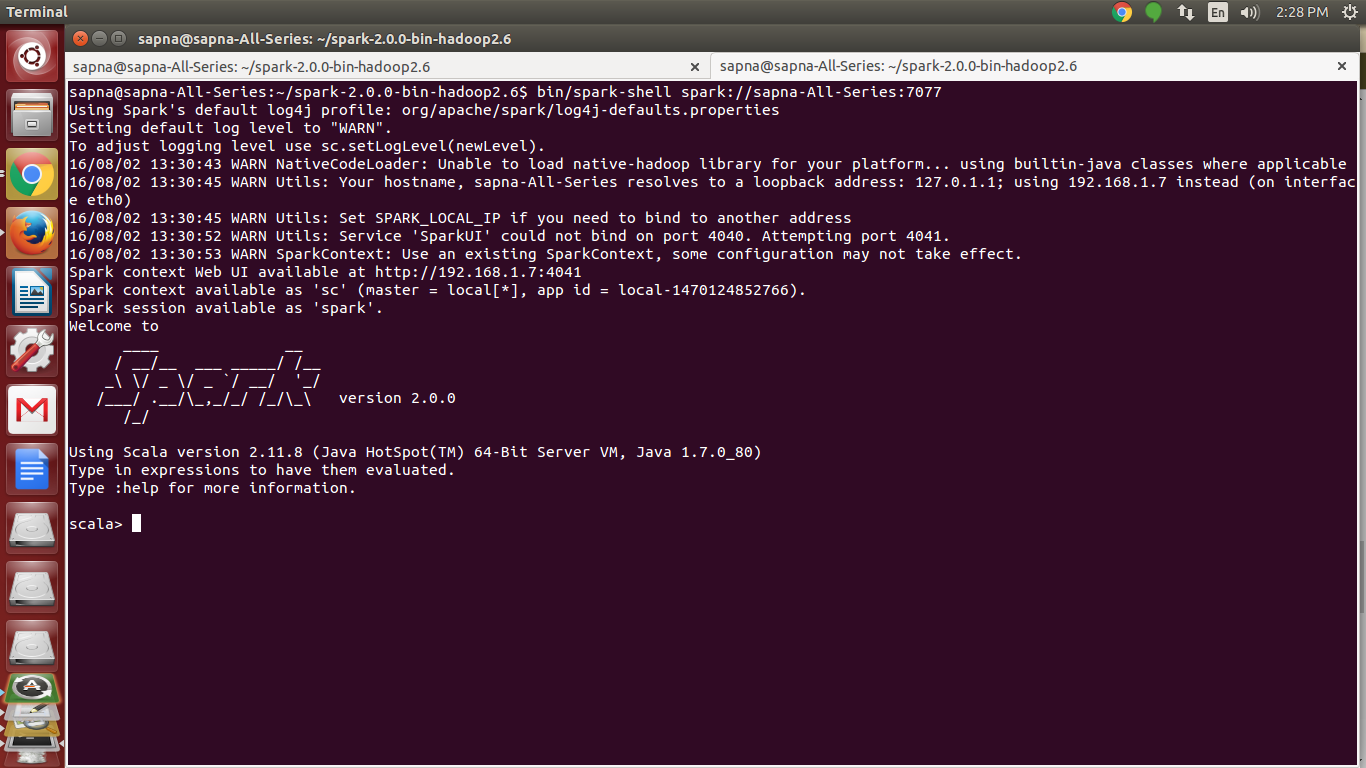
Spark Installation – Starting the Spark Shell
Now to play with Spark, firstly create RDD and perform various RDD operations using this Spark shell commands tutorial.
See Also-
Reference:
http://spark.apache.org/
Your 15 seconds will encourage us to work even harder
Please share your happy experience on Google





Nicely explained how to install Spark2.x on single node.
Nice description.
I installed Spark on my system successfully with your blog. Thanks.
Please let me know few examples for practicing in Spark.
In the section for Scala installation, this adding path command was written
export PATH=$SCALA_HOME/bin:$PATH
It would remove the PATH, Please make it
export PATH=$PATH:$SCALA_HOME/bin
very nicely explained.
I AM GETTING THIS ERROR CAN ANYBODY HELP ME
PLZZZZZZ AFTER RUNNING ./sbin/start-master.sh This command
sumit@sumit-HP-Pavilion-15-Notebook-PC:~/spark-2.2.1-bin-hadoop2.7$ ./sbin/start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /home/sumit/spark-2.2.1-bin-hadoop2.7/logs/spark-sumit-org.apache.spark.deploy.master.Master-1-sumit-HP-Pavilion-15-Notebook-PC.out
failed to launch: nice -n 0 /home/sumit/spark-2.2.1-bin-hadoop2.7/bin/spark-class org.apache.spark.deploy.master.Master –host sumit-HP-Pavilion-15-Notebook-PC –port 7077 –webui-port 8080
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
at sun.launcher.LauncherHelper.checkAndLoadMain(LauncherHelper.java:482)
full log in /home/sumit/spark-2.2.1-bin-hadoop2.7/logs/spark-sumit-org.apache.spark.deploy.master.Master-1-sumit-HP-Pavilion-15-Notebook-PC.out
I am getting an error:-cd $SPARK-HOME
bash: cd: -H: invalid option
cd: usage: cd [-L|[-P [-e]] [-@]] [dir]