Python Mini Project – Speech Emotion Recognition with librosa
Machine Learning courses with 100+ Real-time projects Start Now!!
Speech emotion recognition, the best ever python mini project. The best example of it can be seen at call centers. If you ever noticed, call centers employees never talk in the same manner, their way of pitching/talking to the customers changes with customers. Now, this does happen with common people too, but how is this relevant to call centers? Here is your answer, the employees recognize customers’ emotions from speech, so they can improve their service and convert more people. In this way, they are using speech emotion recognition. So, let’s discuss this project in detail.
Speech emotion recognition is a simple Python mini-project, which you are going to practice with DataFlair. Before, I explain to you the terms related to this mini python project, make sure you bookmarked the complete list of Python Projects.
- Fake News Detection Python Project
- Parkinson’s Disease Detection Python Project
- Color Detection Python Project
- Speech Emotion Recognition Python Project
- Breast Cancer Classification Python Project
- Age and Gender Detection Python Project
- Handwritten Digit Recognition Python Project
- Chatbot Python Project
- Driver Drowsiness Detection Python Project
- Traffic Signs Recognition Python Project
- Image Caption Generator Python Project
What is Speech Emotion Recognition?
Speech Emotion Recognition, abbreviated as SER, is the act of attempting to recognize human emotion and affective states from speech. This is capitalizing on the fact that voice often reflects underlying emotion through tone and pitch. This is also the phenomenon that animals like dogs and horses employ to be able to understand human emotion.
SER is tough because emotions are subjective and annotating audio is challenging.
What is librosa?
librosa is a Python library for analyzing audio and music. It has a flatter package layout, standardizes interfaces and names, backwards compatibility, modular functions, and readable code. Further, in this Python mini-project, we demonstrate how to install it (and a few other packages) with pip.
What is JupyterLab?
JupyterLab is an open-source, web-based UI for Project Jupyter and it has all basic functionalities of the Jupyter Notebook, like notebooks, terminals, text editors, file browsers, rich outputs, and more. However, it also provides improved support for third party extensions.
To run code in the JupyterLab, you’ll first need to run it with the command prompt:
C:\Users\DataFlair>jupyter lab
This will open for you a new session in your browser. Create a new Console and start typing in your code. JupyterLab can execute multiple lines of code at once; pressing enter will not execute your code, you’ll need to press Shift+Enter for the same.
Speech Emotion Recognition – Objective
To build a model to recognize emotion from speech using the librosa and sklearn libraries and the RAVDESS dataset.
Speech Emotion Recognition – About the Python Mini Project
In this Python mini project, we will use the libraries librosa, soundfile, and sklearn (among others) to build a model using an MLPClassifier. This will be able to recognize emotion from sound files. We will load the data, extract features from it, then split the dataset into training and testing sets. Then, we’ll initialize an MLPClassifier and train the model. Finally, we’ll calculate the accuracy of our model.
The Dataset
For this Python mini project, we’ll use the RAVDESS dataset; this is the Ryerson Audio-Visual Database of Emotional Speech and Song dataset, and is free to download. This dataset has 7356 files rated by 247 individuals 10 times on emotional validity, intensity, and genuineness. The entire dataset is 24.8GB from 24 actors, but we’ve lowered the sample rate on all the files, and you can download it here.
Prerequisites
You’ll need to install the following libraries with pip:
pip install librosa soundfile numpy sklearn pyaudio
If you run into issues installing librosa with pip, you can try it with conda.
Steps for speech emotion recognition python projects
1. Make the necessary imports:
import librosa import soundfile import os, glob, pickle import numpy as np from sklearn.model_selection import train_test_split from sklearn.neural_network import MLPClassifier from sklearn.metrics import accuracy_score
Screenshot:

2. Define a function extract_feature to extract the mfcc, chroma, and mel features from a sound file. This function takes 4 parameters- the file name and three Boolean parameters for the three features:
- mfcc: Mel Frequency Cepstral Coefficient, represents the short-term power spectrum of a sound
- chroma: Pertains to the 12 different pitch classes
- mel: Mel Spectrogram Frequency
Learn more about Python Sets and Booleans
Open the sound file with soundfile.SoundFile using with-as so it’s automatically closed once we’re done. Read from it and call it X. Also, get the sample rate. If chroma is True, get the Short-Time Fourier Transform of X.
Let result be an empty numpy array. Now, for each feature of the three, if it exists, make a call to the corresponding function from librosa.feature (eg- librosa.feature.mfcc for mfcc), and get the mean value. Call the function hstack() from numpy with result and the feature value, and store this in result. hstack() stacks arrays in sequence horizontally (in a columnar fashion). Then, return the result.
#DataFlair - Extract features (mfcc, chroma, mel) from a sound file
def extract_feature(file_name, mfcc, chroma, mel):
with soundfile.SoundFile(file_name) as sound_file:
X = sound_file.read(dtype="float32")
sample_rate=sound_file.samplerate
if chroma:
stft=np.abs(librosa.stft(X))
result=np.array([])
if mfcc:
mfccs=np.mean(librosa.feature.mfcc(y=X, sr=sample_rate, n_mfcc=40).T, axis=0)
result=np.hstack((result, mfccs))
if chroma:
chroma=np.mean(librosa.feature.chroma_stft(S=stft, sr=sample_rate).T,axis=0)
result=np.hstack((result, chroma))
if mel:
mel=np.mean(librosa.feature.melspectrogram(X, sr=sample_rate).T,axis=0)
result=np.hstack((result, mel))
return resultScreenshot:

3. Now, let’s define a dictionary to hold numbers and the emotions available in the RAVDESS dataset, and a list to hold those we want- calm, happy, fearful, disgust.
#DataFlair - Emotions in the RAVDESS dataset
emotions={
'01':'neutral',
'02':'calm',
'03':'happy',
'04':'sad',
'05':'angry',
'06':'fearful',
'07':'disgust',
'08':'surprised'
}
#DataFlair - Emotions to observe
observed_emotions=['calm', 'happy', 'fearful', 'disgust']Screenshot:

Facing Failure in Interview?
Prepare with DataFlair – Frequently Asked Python Interview Questions
4. Now, let’s load the data with a function load_data() – this takes in the relative size of the test set as parameter. x and y are empty lists; we’ll use the glob() function from the glob module to get all the pathnames for the sound files in our dataset. The pattern we use for this is: “D:\\DataFlair\\ravdess data\\Actor_*\\*.wav”. This is because our dataset looks like this:
Screenshot:
So, for each such path, get the basename of the file, the emotion by splitting the name around ‘-’ and extracting the third value:
Screenshot:
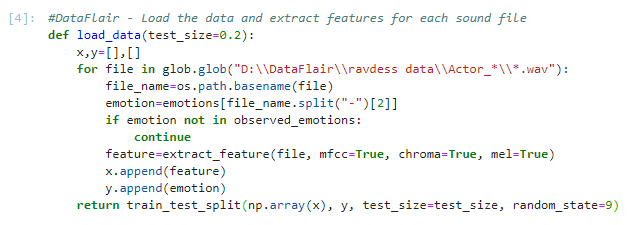
Using our emotions dictionary, this number is turned into an emotion, and our function checks whether this emotion is in our list of observed_emotions; if not, it continues to the next file. It makes a call to extract_feature and stores what is returned in ‘feature’. Then, it appends the feature to x and the emotion to y. So, the list x holds the features and y holds the emotions. We call the function train_test_split with these, the test size, and a random state value, and return that.
#DataFlair - Load the data and extract features for each sound file
def load_data(test_size=0.2):
x,y=[],[]
for file in glob.glob("D:\\DataFlair\\ravdess data\\Actor_*\\*.wav"):
file_name=os.path.basename(file)
emotion=emotions[file_name.split("-")[2]]
if emotion not in observed_emotions:
continue
feature=extract_feature(file, mfcc=True, chroma=True, mel=True)
x.append(feature)
y.append(emotion)
return train_test_split(np.array(x), y, test_size=test_size, random_state=9)Screenshot:
5. Time to split the dataset into training and testing sets! Let’s keep the test set 25% of everything and use the load_data function for this.
#DataFlair - Split the dataset x_train,x_test,y_train,y_test=load_data(test_size=0.25)
Screenshot:

6. Observe the shape of the training and testing datasets:
#DataFlair - Get the shape of the training and testing datasets print((x_train.shape[0], x_test.shape[0]))
Screenshot:

7. And get the number of features extracted.
#DataFlair - Get the number of features extracted
print(f'Features extracted: {x_train.shape[1]}')Output Screenshot:

8. Now, let’s initialize an MLPClassifier. This is a Multi-layer Perceptron Classifier; it optimizes the log-loss function using LBFGS or stochastic gradient descent. Unlike SVM or Naive Bayes, the MLPClassifier has an internal neural network for the purpose of classification. This is a feedforward ANN model.
#DataFlair - Initialize the Multi Layer Perceptron Classifier model=MLPClassifier(alpha=0.01, batch_size=256, epsilon=1e-08, hidden_layer_sizes=(300,), learning_rate='adaptive', max_iter=500)
Screenshot:

9. Fit/train the model.
#DataFlair - Train the model model.fit(x_train,y_train)
Output Screenshot:

10. Let’s predict the values for the test set. This gives us y_pred (the predicted emotions for the features in the test set).
#DataFlair - Predict for the test set y_pred=model.predict(x_test)
Screenshot:

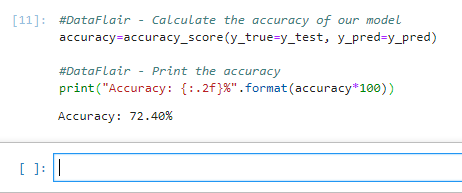
11. To calculate the accuracy of our model, we’ll call up the accuracy_score() function we imported from sklearn. Finally, we’ll round the accuracy to 2 decimal places and print it out.
#DataFlair - Calculate the accuracy of our model
accuracy=accuracy_score(y_true=y_test, y_pred=y_pred)
#DataFlair - Print the accuracy
print("Accuracy: {:.2f}%".format(accuracy*100))Output Screenshot:
Summary
Humans express emotions in their voice—like happy, sad, angry, or calm. A machine learning project can listen to voice recordings and tell the emotion behind them. This is called Speech Emotion Recognition (SER). Using Python and a library called librosa, we can analyze sound waves and extract features from speech to detect emotions. This project is useful for call centers, chatbots, and even smart assistants.
In this Python mini project, we learned to recognize emotions from speech. We used an MLPClassifier for this and made use of the soundfile library to read the sound file, and the librosa library to extract features from it. As you’ll see, the model delivered an accuracy of 72.4%. That’s good enough for us yet.
Hope you enjoyed the mini python project.
Want to become next Python Developer??
Enroll for Best Online Python Course NOW!!
Reference – Zenodo
Your 15 seconds will encourage us to work even harder
Please share your happy experience on Google





I got nan’s. How can I fix that?
Can you give us the link to the full code, and elaborate more on where are you getting Nan? Maybe then we can help you.
hi. I’m Muhammad Nazam Maqbool. I’m wants to know that is any one share complete code with you? are you develop this project successfully? if yes then please help me if you can do.
i am also getting this error, please help me me in removing this error !
—————————————————————————
ValueError Traceback (most recent call last)
in
54
55 #DataFlair – Split the dataset
—> 56 x_train,x_test,y_train,y_test=load_data(test_size=0.25)
57
58 #DataFlair – Get the shape of the training and testing datasets
in load_data(test_size)
51 x.append(feature)
52 y.append(emotion)
—> 53 return train_test_split(np.array(x), y, test_size=test_size, random_state=9)
54
55 #DataFlair – Split the dataset
~\Anaconda3\lib\site-packages\sklearn\model_selection\_split.py in train_test_split(*arrays, **options)
2098 n_samples = _num_samples(arrays[0])
2099 n_train, n_test = _validate_shuffle_split(n_samples, test_size, train_size,
-> 2100 default_test_size=0.25)
2101
2102 if shuffle is False:
~\Anaconda3\lib\site-packages\sklearn\model_selection\_split.py in _validate_shuffle_split(n_samples, test_size, train_size, default_test_size)
1780 ‘resulting train set will be empty. Adjust any of the ‘
1781 ‘aforementioned parameters.’.format(n_samples, test_size,
-> 1782 train_size)
1783 )
1784
ValueError: With n_samples=0, test_size=0.25 and train_size=None, the resulting train set will be empty. Adjust any of the aforementioned parameters.
you are getting nan because there might be some missing data that needs to be removed by taking mean.
I doubt which of the places I have to give the filename and which file I have to give.
Hey, I am so I ran the function load_data to split the data set but I am getting the following error:
—————————————————————————
ValueError Traceback (most recent call last)
in
#DataFlair – Split the dataset
—-> x_train,x_test,y_train,y_test=load_data(test_size=0.25)
in load_data(test_size)
x.append(feature)
y.append(emotion)
—> return train_test_split(np.array(x), y, test_size=test_size, random_state=9)
~\Anaconda3.0\lib\site-packages\sklearn\model_selection\_split.py in train_test_split(*arrays, **options)
n_samples = _num_samples(arrays[0])
n_train, n_test = _validate_shuffle_split(n_samples, test_size, train_size,
-> default_test_size=0.25)
if shuffle is False:
~\Anaconda3.0\lib\site-packages\sklearn\model_selection\_split.py in _validate_shuffle_split(n_samples, test_size, train_size, default_test_size)
‘resulting train set will be empty. Adjust any of the ‘
‘aforementioned parameters.’.format(n_samples, test_size,
-> train_size)
)
ValueError: With n_samples=0, test_size=0.25 and train_size=None, the resulting train set will be empty. Adjust any of the aforementioned parameters.
so did u removed this error, if yes then how !
“D:\\DataFlair\\ravdess data\\Actor_*\\*.wav”
replace this line from your path
Hi. I’m Muhammad Nazam Maqbool. Are you develop this project successfully?
I am getting this error. Please help. I guess it is not reading the file correctly that is why this is happening. I tried to search this error on the internet and it suggested resampling. I resampled the data using cosine transformation but nothing happened. I guess it is not able to read the file correctly. Please help.
—————————————————————————
ParameterError Traceback (most recent call last)
in ()
—-> 1 x_train,x_test,y_train,y_test=load_data(test_size=0.25)
in load_data(test_size)
6 if emotion not in observed_emotions:
7 continue
—-> 8 feature=extract_feature(file, mfcc=True, chroma=True, mel=True)
9 x.append(feature)
10 y.append(emotion)
in extract_feature(file_name, mfcc, chroma, mel)
5 sample_rate=sound_file.samplerate
6 if chroma:
—-> 7 stft=np.abs(librosa.stft(X))
8 result=np.array([])
9 if mfcc:
C:\Users\lenovo\Anaconda2\envs\py2\lib\site-packages\librosa\core\spectrum.pyc in stft(y, n_fft, hop_length, win_length, window, center, dtype, pad_mode)
213
214 # Check audio is valid
–> 215 util.valid_audio(y)
216
217 # Pad the time series so that frames are centered
C:\Users\lenovo\Anaconda2\envs\py2\lib\site-packages\librosa\util\utils.pyc in valid_audio(y, mono)
266 if mono and y.ndim != 1:
267 raise ParameterError(‘Invalid shape for monophonic audio: ‘
–> 268 ‘ndim={:d}, shape={}’.format(y.ndim, y.shape))
269
270 elif y.ndim > 2 or y.ndim == 0:
ParameterError: Invalid shape for monophonic audio: ndim=2, shape=(172972L, 2L)
This (ndim =2 ) is an error caused by a few audio files that are larger than normal on the disk. Only check the song files dimension or size , seen that.
Original source File error with invalid dim
This is what i found..
Original source data error with invalid ndim ( ndim=2 )
Error at file: 03-01-08-01-02-02-01.wav
Error at file: 03-01-02-01-01-02-01.wav
Error at file: 03-01-02-01-02-02-05.wav
Error at file: 03-01-06-01-01-02-20.wav
Error at file: 03-01-03-01-02-01-20.wa
Invalid shape for monophonic audio: ndim=2, shape=(203403, 2)
what should we do when we have this error ?
we appreciate your work bro , but its gonna be easier if you made a vedios of these projects i think it will be more helpful
please share the full code for removing my error
Please share full code
Is it possible to see in percentage, the value of each category(ex. for calm category)?
i am getting following error while executing the code, how should i rectify this
x_train,x_test,y_train,y_test=load_data(test_size=0.2)
x_train,x_test,y_train,y_test=load_data(test_size=0.2)
—————————————————————————
TypeError Traceback (most recent call last)
in
—-> 1 x_train,x_test,y_train,y_test=load_data(test_size=0.2)
in load_data(test_size)
9 x.append(feature)
10 y.append(emotion)
—> 11 return train_test_split(np.array[x], y, test_size, test_size, random_state=9)
TypeError: ‘builtin_function_or_method’ object is not subscriptable
How can get the pathname in linux?
Open terminal and type command pwd
ValueError: With n_samples=0, test_size=0.25 and train_size=None, the resulting train set will be empty. Adjust any of the aforementioned parameters.
Hello, because of a small dataset I got values of accuracy from 35 to 59 %. It’s curious.
Hey Evgency P,
I would recommend you to follow along the article step by step and make sure you haven’t missed anything because you are getting very low accuracy which means that there is some mistake in the approach you are using.
Hi, I ran your given example and it worked. But when I downloaded the original RAVDESS dataset from here: https://zenodo.org/record/1188976 and tried to use it as a training dataset but it gives me an error “librosa.util.exceptions.ParameterError: Invalid shape for monophonic audio: ndim=2, shape=(172972, 2)”.
I tried .mp3 files to be predicted on but it says invalid format(Used your dataset to train). So I converted .mp3 to .wav and tried still above type error. I read that you had lowered the sample rate so I tried every sample rate between 8000khz to 9900khz still no output. Then I used online text to speech converter to get a .wav file. And it ran but always got “fearfull” as an output.
Can you please tell me how can I train the model on the original dataset and also how can I predict on .mp3 or other .wav files. I am thinking once it starts training on the original dataset
it will not have problem in predicting for the other .wav files.
Make sure to use the data that they have lowered the sample rate of (link above) – not the original RAVDESS data. Cheers.
I used their data and got the result. I want to know what lowered sample rate they are using and How can I train this model on the original RAVDESS Dataset and predict on the real world voice data(Sound file).
i am also getting the same error, please tell me me how to remove this error now!
—————————————————————————
ValueError Traceback (most recent call last)
in
54
55 #DataFlair – Split the dataset
—> 56 x_train,x_test,y_train,y_test=load_data(test_size=0.25)
57
58 #DataFlair – Get the shape of the training and testing datasets
in load_data(test_size)
51 x.append(feature)
52 y.append(emotion)
—> 53 return train_test_split(np.array(x), y, test_size=test_size, random_state=9)
54
55 #DataFlair – Split the dataset
~\Anaconda3\lib\site-packages\sklearn\model_selection\_split.py in train_test_split(*arrays, **options)
2098 n_samples = _num_samples(arrays[0])
2099 n_train, n_test = _validate_shuffle_split(n_samples, test_size, train_size,
-> 2100 default_test_size=0.25)
2101
2102 if shuffle is False:
~\Anaconda3\lib\site-packages\sklearn\model_selection\_split.py in _validate_shuffle_split(n_samples, test_size, train_size, default_test_size)
1780 ‘resulting train set will be empty. Adjust any of the ‘
1781 ‘aforementioned parameters.’.format(n_samples, test_size,
-> 1782 train_size)
1783 )
1784
ValueError: With n_samples=0, test_size=0.25 and train_size=None, the resulting train set will be empty. Adjust any of the aforementioned parameters.
Did you solve the error?
Hi guys, just downgrade the scikit-learn package and check the code properly it will work.
Hi, just downgrade your scikit learn it will work.
Hi, guys just downgrade oyur scikit learn package and then check the code properly it will work.
thank you very much, no error now
Hi Avantika,
We are happy to help you. Refer to our other Python projects also from the sidebar for gaining some more real-time experience.
Hi, I have done created the model, then how to use the model with new voice file ? thanks
Why this error??
PS C:\Users\PREM> & C:/Users/PREM/AppData/Local/Programs/Python/Python38/python.exe c:/Users/PREM/Downloads/Student-Management-System-Project-In-Python-master/pyaudio.py
File “c:/Users/PREM/Downloads/Student-Management-System-Project-In-Python-master/pyaudio.py”, line 25
return result
^
SyntaxError: ‘return’ outside function
why im facing this error??
—————————————————————————
NameError Traceback (most recent call last)
in
20 chroma=np.mean(librosa.feature.chroma_stft(S=stft, sr=sample_rate).T,axis=0)
21 result=np.hstack((result, chroma))
—> 22 if mel:
23 mel=np.mean(librosa.feature.melspectrogram(X, sr=sample_rate).T,axis=0)
24 result=np.hstack((result, mel))
NameError: name ‘mel’ is not defined
Hi ,
i get error in the command x_train,x_test,y_train,y_test=load_data(test_size=0.2)
x_train,x_test,y_train,y_test=load_data(test_size=0.2)
it’s say it’s not define
pleas help my
while giving a path name of the file use foreword double slash “\\” and run the program.
def load_data(test_size=0.2):
x, y = [], []
for file in glob.glob(“F:\\PyCharm Community Edition 2019.3\\MyProjects\\audio\\Actor_*\\*.wav”):
file_name = os.path.basename(file)
emotion = emotions[file_name.split(“-“)[2]]
if emotion not in observed_emotions:
continue
feature = extract_feature(file, mfcc=True, chroma=True, mel=True)
x.append(feature)
y.append(emotion)
return train_test_split(np.array(x), y, test_size=test_size, random_state=9)
x_train, x_test, y_train, y_test = load_data(test_size=0.25)
# print((x_train.shape[0], x_test.shape[0]))
“D:\\DataFlair””\ravdess data\\Actor_*\\*.wav”
replace this line from your path
like “C:\\Users\\ashok\\speech emotion\\speech-emotion-recognition-ravdess-data\\Actor_*\\*.wav
“
Hi Data Flair Team,
I am trying to implement your code but I am getting ‘Parameter Error’ when I run the code. Please help me in fixing the error. See the below error
x_train,x_test,y_train,y_test=load_data(0.25)
ParameterError Traceback (most recent call last)
in
1 #split the dataset into train and test
2
—-> 3 x_train,x_test,y_train,y_test=load_data(0.25)
in load_data(test_size)
8 #if emotion not in observed_emotions:
9 # continue
—> 10 feature=extract_feature(file, mfcc=True, chroma=True, mel=True)
11 x.append(feature)
12 y.append(emotion)
in extract_feature(file_name, mfcc, chroma, mel)
6 sample_rate=sound_file.samplerate
7 if chroma:
—-> 8 stft=np.abs(librosa.stft(y=X))
9 result=np.array([])
10 if mfcc:
~/envs/Dissertation/lib/python3.7/site-packages/librosa/core/spectrum.py in stft(y, n_fft, hop_length, win_length, window, center, dtype, pad_mode)
213
214 # Check audio is valid
–> 215 util.valid_audio(y)
216
217 # Pad the time series so that frames are centered
~/envs/Dissertation/lib/python3.7/site-packages/librosa/util/utils.py in valid_audio(y, mono)
266 if mono and y.ndim != 1:
267 raise ParameterError(‘Invalid shape for monophonic audio: ‘
–> 268 ‘ndim={:d}, shape={}’.format(y.ndim, y.shape))
269
270 elif y.ndim > 2 or y.ndim == 0:
ParameterError: Invalid shape for monophonic audio: ndim=2, shape=(156956, 2)
How can you test the trained data for the custom inputs voice files we provided?
can you please provide another slide regarding the manual usage of the model which we trained here
Thank you
File “/Users/sohailhussain/anaconda3/lib/python3.7/site-packages/sklearn/model_selection/_split.py”, line 1804, in _validate_shuffle_split
class PredefinedSplit(BaseCrossValidator):
ValueError: With n_samples=0, test_size=0.25 and train_size=None, the resulting train set will be empty. Adjust any of the aforementioned parameters.
HEY , how do i fix this error ?????
—————————————————
NameError Traceback (most recent call last)
in
13 chroma=np.mean(librosa.feature.chroma_stft(S=stft, sr=sample_rate).T,axis=0)
14 result=np.hstack((result, chroma))
—> 15 if mel:
16 mel=np.mean(librosa.feature.melspectrogram(X, sr=sample_rate).T,axis=0)
17 result=np.hstack((result, mel))
NameError: name ‘mel’ is not defined
Hello your code is working really nice
Thank you !!!
If I want to create a .h5 filehow to do it.
Also if i want to input a single file from ravdess and check the emotion how to proceed
Your help would be appreciated!!!!