Python Project – Music Genre Classification
Machine Learning courses with 100+ Real-time projects Start Now!!
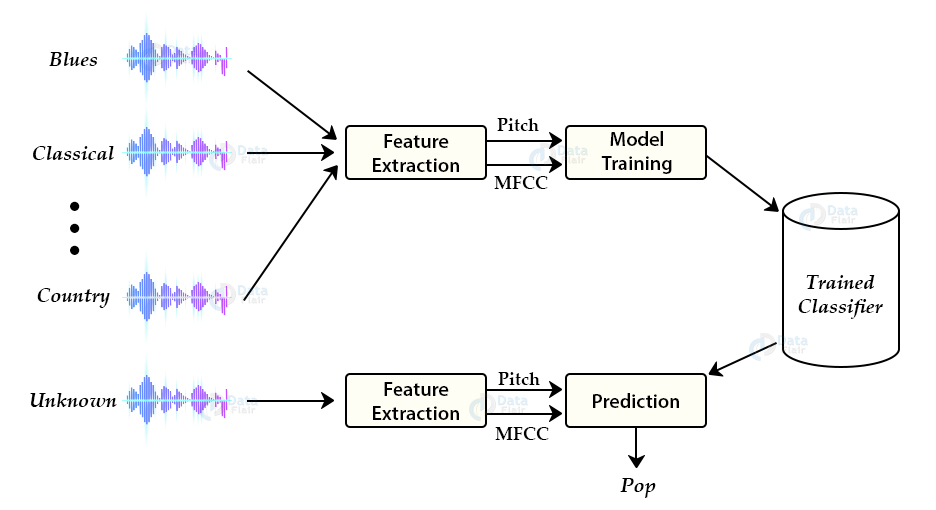
Music Genre Classification – Automatically classify different musical genres
In this tutorial we are going to develop a deep learning project to automatically classify different musical genres from audio files. We will classify these audio files using their low-level features of frequency and time domain.
For this project we need a dataset of audio tracks having similar size and similar frequency range. GTZAN genre classification dataset is the most recommended dataset for the music genre classification project and it was collected for this task only.
Music Genre Classification
About the dataset:
The GTZAN genre collection dataset was collected in 2000-2001. It consists of 1000 audio files each having 30 seconds duration. There are 10 classes ( 10 music genres) each containing 100 audio tracks. Each track is in .wav format. It contains audio files of the following 10 genres:
- Blues
- Classical
- Country
- Disco
- Hiphop
- Jazz
- Metal
- Pop
- Reggae
- Rock
Music Genre Classification approach:
There are various methods to perform classification on this dataset. Some of these approaches are:
- Multiclass support vector machines
- K-means clustering
- K-nearest neighbors
- Convolutional neural networks
We will use K-nearest neighbors algorithm because in various researches it has shown the best results for this problem.
K-Nearest Neighbors is a popular machine learning algorithm for regression and classification. It makes predictions on data points based on their similarity measures i.e distance between them.
Feature Extraction:
The first step for music genre classification project would be to extract features and components from the audio files. It includes identifying the linguistic content and discarding noise.
Mel Frequency Cepstral Coefficients:
These are state-of-the-art features used in automatic speech and speech recognition studies. There are a set of steps for generation of these features:
- Since the audio signals are constantly changing, first we divide these signals into smaller frames. Each frame is around 20-40 ms long
- Then we try to identify different frequencies present in each frame
- Now, separate linguistic frequencies from the noise
- To discard the noise, it then takes discrete cosine transform (DCT) of these frequencies. Using DCT we keep only a specific sequence of frequencies that have a high probability of information.
Steps to build Music Genre Classification:
Download the GTZAN dataset from the following link:
Create a new python file “music_genre.py” and paste the code described in the steps below:
1. Imports:
from python_speech_features import mfcc import scipy.io.wavfile as wav import numpy as np from tempfile import TemporaryFile import os import pickle import random import operator import math import numpy as np
2. Define a function to get the distance between feature vectors and find neighbors:
def getNeighbors(trainingSet, instance, k):
distances = []
for x in range (len(trainingSet)):
dist = distance(trainingSet[x], instance, k )+ distance(instance, trainingSet[x], k)
distances.append((trainingSet[x][2], dist))
distances.sort(key=operator.itemgetter(1))
neighbors = []
for x in range(k):
neighbors.append(distances[x][0])
return neighbors
3. Identify the nearest neighbors:
def nearestClass(neighbors):
classVote = {}
for x in range(len(neighbors)):
response = neighbors[x]
if response in classVote:
classVote[response]+=1
else:
classVote[response]=1
sorter = sorted(classVote.items(), key = operator.itemgetter(1), reverse=True)
return sorter[0][0]
4. Define a function for model evaluation:
def getAccuracy(testSet, predictions):
correct = 0
for x in range (len(testSet)):
if testSet[x][-1]==predictions[x]:
correct+=1
return 1.0*correct/len(testSet)
5. Extract features from the dataset and dump these features into a binary .dat file “my.dat”:
directory = "__path_to_dataset__"
f= open("my.dat" ,'wb')
i=0
for folder in os.listdir(directory):
i+=1
if i==11 :
break
for file in os.listdir(directory+folder):
(rate,sig) = wav.read(directory+folder+"/"+file)
mfcc_feat = mfcc(sig,rate ,winlen=0.020, appendEnergy = False)
covariance = np.cov(np.matrix.transpose(mfcc_feat))
mean_matrix = mfcc_feat.mean(0)
feature = (mean_matrix , covariance , i)
pickle.dump(feature , f)
f.close()
6. Train and test split on the dataset:
dataset = []
def loadDataset(filename , split , trSet , teSet):
with open("my.dat" , 'rb') as f:
while True:
try:
dataset.append(pickle.load(f))
except EOFError:
f.close()
break
for x in range(len(dataset)):
if random.random() <split :
trSet.append(dataset[x])
else:
teSet.append(dataset[x])
trainingSet = []
testSet = []
loadDataset("my.dat" , 0.66, trainingSet, testSet)
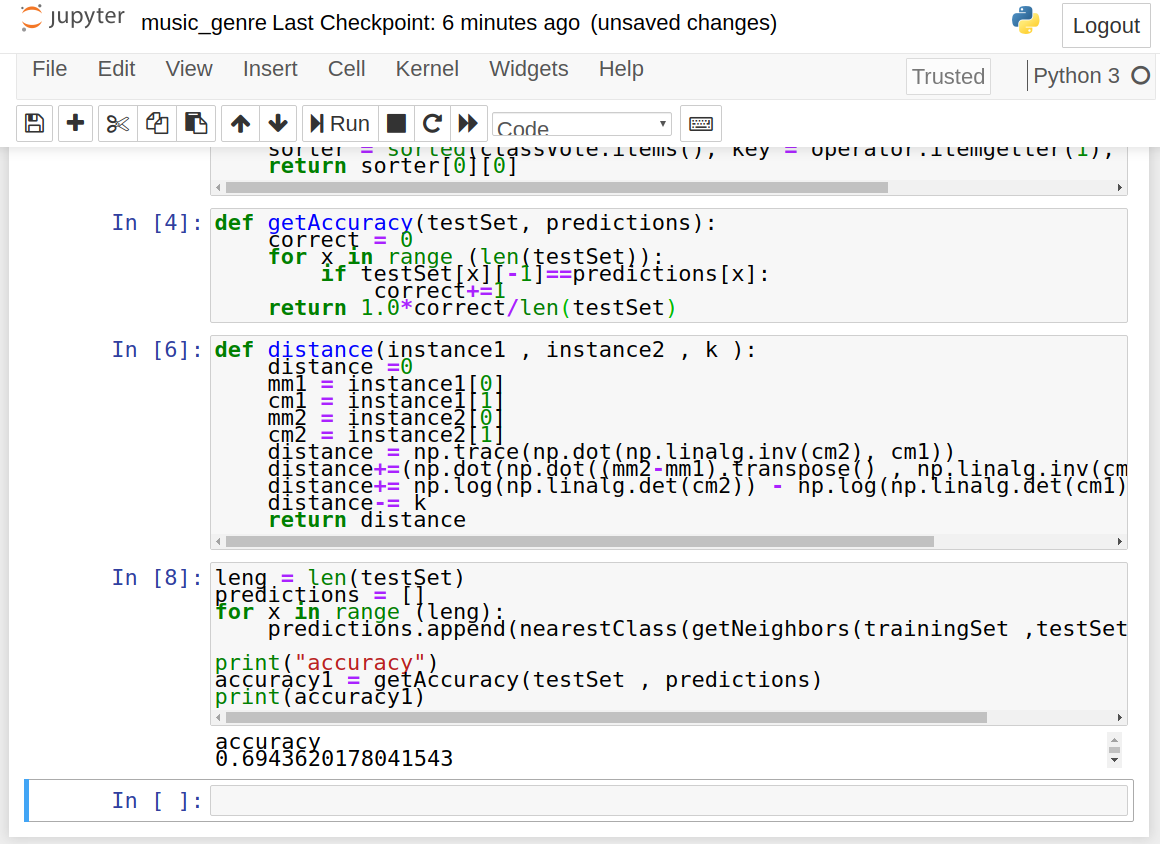
7. Make prediction using KNN and get the accuracy on test data:
leng = len(testSet)
predictions = []
for x in range (leng):
predictions.append(nearestClass(getNeighbors(trainingSet ,testSet[x] , 5)))
accuracy1 = getAccuracy(testSet , predictions)
print(accuracy1)
Test the classifier with new audio file
Save the new audio file in the present directory. Make a new file test.py and paste the below script:
from python_speech_features import mfcc
import scipy.io.wavfile as wav
import numpy as np
from tempfile import TemporaryFile
import os
import pickle
import random
import operator
import math
import numpy as np
from collections import defaultdict
dataset = []
def loadDataset(filename):
with open("my.dat" , 'rb') as f:
while True:
try:
dataset.append(pickle.load(f))
except EOFError:
f.close()
break
loadDataset("my.dat")
def distance(instance1 , instance2 , k ):
distance =0
mm1 = instance1[0]
cm1 = instance1[1]
mm2 = instance2[0]
cm2 = instance2[1]
distance = np.trace(np.dot(np.linalg.inv(cm2), cm1))
distance+=(np.dot(np.dot((mm2-mm1).transpose() , np.linalg.inv(cm2)) , mm2-mm1 ))
distance+= np.log(np.linalg.det(cm2)) - np.log(np.linalg.det(cm1))
distance-= k
return distance
def getNeighbors(trainingSet , instance , k):
distances =[]
for x in range (len(trainingSet)):
dist = distance(trainingSet[x], instance, k )+ distance(instance, trainingSet[x], k)
distances.append((trainingSet[x][2], dist))
distances.sort(key=operator.itemgetter(1))
neighbors = []
for x in range(k):
neighbors.append(distances[x][0])
return neighbors
def nearestClass(neighbors):
classVote ={}
for x in range(len(neighbors)):
response = neighbors[x]
if response in classVote:
classVote[response]+=1
else:
classVote[response]=1
sorter = sorted(classVote.items(), key = operator.itemgetter(1), reverse=True)
return sorter[0][0]
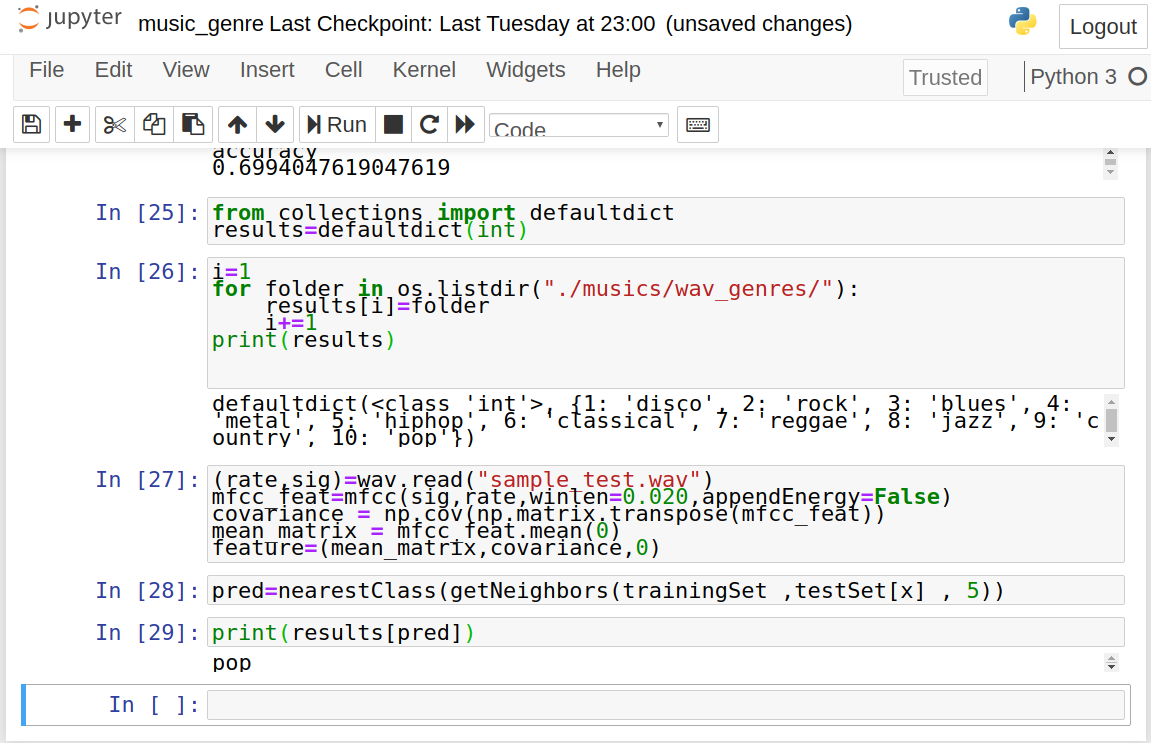
results=defaultdict(int)
i=1
for folder in os.listdir("./musics/wav_genres/"):
results[i]=folder
i+=1
(rate,sig)=wav.read("__path_to_new_audio_file_")
mfcc_feat=mfcc(sig,rate,winlen=0.020,appendEnergy=False)
covariance = np.cov(np.matrix.transpose(mfcc_feat))
mean_matrix = mfcc_feat.mean(0)
feature=(mean_matrix,covariance,0)
pred=nearestClass(getNeighbors(dataset ,feature , 5))
print(results[pred])
Now, run this script to get the prediction:
python3 test.py
Summary:
Music has different types like rock, jazz, pop, or classical. This project helps a machine recognize the genre of a song using sound features. Using Python and libraries like librosa and Keras, we can build a model that listens to a song clip and tells its category.
In this music genre classification project, we have developed a classifier on audio files to predict its genre. We work through this project on GTZAN music genre classification dataset. This tutorial explains how to extract important features from audio files. In this deep learning project we have implemented a K nearest neighbor using a count of K as 5.
This project is perfect for music lovers and ML beginners. It teaches audio data handling, feature extraction, classification, and music signal processing. It also helps explore how AI interacts with the world of sound.
What Next?
Let’s proceed ahead to next-level, work on a capstone project: Driver Drowsiness Detection project
Did we exceed your expectations?
If Yes, share your valuable feedback on Google





There is a error that the file cant be found in extract features
can use please print the error stack after the running the code.
can you please print the error stack after running the code.
Traceback (most recent call last):
File “music_genre.py”, line 61, in
(rate, sig) = wav.read(directory+”/”+folder+”/”+file)
File “/usr/local/lib/python3.7/site-packages/scipy/io/wavfile.py”, line 236, in read
file_size, is_big_endian = _read_riff_chunk(fid)
File “/usr/local/lib/python3.7/site-packages/scipy/io/wavfile.py”, line 168, in _read_riff_chunk
“understood.”.format(repr(str1)))
ValueError: File format b’\xcb\x15\x1e\x16’… not understood.
Can you help me with this error ?
I faced the same issue. The file jazz.0054 in jazz folder was causing the issue. I removed it and the code ran fine. Try removing that file and running the code.
PermissionError Traceback (most recent call last)
in
7 break
8 for file in os.listdir(directory+folder):
—-> 9 (rate,sig) = wav.read(directory+folder+”/”+file)
10 mfcc_feat = mfcc(sig,rate ,winlen=0.020, appendEnergy = False)
11 covariance = np.cov(np.matrix.transpose(mfcc_feat))
c:\users\home\appdata\local\programs\python\python38\lib\site-packages\scipy\io\wavfile.py in read(filename, mmap)
262 mmap = False
263 else:
–> 264 fid = open(filename, ‘rb’)
265
266 try:
PermissionError: [Errno 13] Permission denied: ‘D:$RECYCLE.BIN/S-1-5-21-2747400840-3922816497-3937391489-1003’
got this error while Extracting features from the dataset and dumping
Try to run the code as a super user or in windows power shell. If that also does not work, use a different module such as “simpleaudio” to read the wav file, by installing it using pip as “pip install simpleaudio”.
directory = “C:/Users/HP/Desktop/music_speech/”
f= open(“my.dat” ,’wb’)
i=0
for folder in os.listdir(directory):
i+=1
if i==11 :
break
for file in os.listdir(directory+folder):
(rate,sig) = wav.read(directory+folder+”/”+file)
mfcc_feat = mfcc(sig,rate ,winlen=0.020, appendEnergy = False)
covariance = np.cov(np.matrix.transpose(mfcc_feat))
mean_matrix = mfcc_feat.mean(0)
feature = (mean_matrix , covariance , i)
pickle.dump(feature , f)
f.close()
For my code error as follow:
————————————————————————–
NameError Traceback (most recent call last)
in
2 f= open(“my.dat” ,’wb’)
3 i=0
—-> 4 for folder in os.listdir(directory):
5 i+=1
6 if i==11 :
NameError: name ‘os’ is not defined
try writing this before the code:
import os
How To solve this error
ValueError Traceback (most recent call last)
in
7 break
8 for file in os.listdir(directory+folder):
—-> 9 (rate,sig) = wav.read(directory+folder+”/”+file)
10 mfcc_feat = mfcc(sig,rate ,winlen=0.020, appendEnergy = False)
11 covariance = np.cov(np.matrix.transpose(mfcc_feat))
c:\users\rahul\appdata\local\programs\python\python37\lib\site-packages\scipy\io\wavfile.py in read(filename, mmap)
265
266 try:
–> 267 file_size, is_big_endian = _read_riff_chunk(fid)
268 fmt_chunk_received = False
269 data_chunk_received = False
c:\users\rahul\appdata\local\programs\python\python37\lib\site-packages\scipy\io\wavfile.py in _read_riff_chunk(fid)
166 # There are also .wav files with “FFIR” or “XFIR” signatures?
167 raise ValueError(“File format {}… not ”
–> 168 “understood.”.format(repr(str1)))
169
170 # Size of entire file
ValueError: File format b'{\n “‘… not understood.
I faced the same issue. The file jazz.0054 in jazz folder was causing the issue. I removed it and the code ran fine. Try removing that file and running the code.
Traceback (most recent call last):
File “music_genre.py”, line 61, in
(rate, sig) = wav.read(directory+”/”+folder+”/”+file)
File “/usr/local/lib/python3.7/site-packages/scipy/io/wavfile.py”, line 236, in read
file_size, is_big_endian = _read_riff_chunk(fid)
File “/usr/local/lib/python3.7/site-packages/scipy/io/wavfile.py”, line 168, in _read_riff_chunk
“understood.”.format(repr(str1)))
ValueError: File format b’\xcb\x15\x1e\x16’… not understood.
Getting this error
Can anyone help ?
I faced the same issue. The file jazz.0054 in jazz folder was causing the issue. I removed it and the code ran fine. Try removing that file and running the code.
Hey Thanks! It is working. May i know how you figured it out?
He printed each file as it was being iterated till the corrupt file came up and the execution halted
nvm my bad missing line
I’m trying to run this in google colab and I don’t know what to write for this line-
directory = “__path_to_dataset__”
Could someone please help me? I uploaded the genres.tar dataset to colab and even tried pasting it’s file location. But it isn’t working.
This is the error I’m getting:
—————————————————————————
NotADirectoryError Traceback (most recent call last)
in ()
4 i=0
5
—-> 6 for folder in os.listdir(directory):
7 i+=1
8 if i==11 :
NotADirectoryError: [Errno 20] Not a directory: ‘/content/genres.tar’
you shod give directory path
ex:
directory = “D:/music_genre_project/original/”
you shod give directory path of data set
ex:
directory = “D:/music_genre_project/original/”
could someone tell me what i’m supposed to write in this line?
directory = “__path_to_dataset__”
I’m getting this error:
—————————————————————————
NotADirectoryError Traceback (most recent call last)
in ()
4 i=0
5
—-> 6 for folder in os.listdir(directory):
7 i+=1
8 if i==11 :
NotADirectoryError: [Errno 20] Not a directory: ‘/content/genres.tar’
Traceback (most recent call last):
File “C:/Users/MYPC/AppData/Local/Programs/Python/Python38/music_genre.py”, line 46, in
(rate,sig) = wav.read(directory+folder+”/”+file)
File “C:\Users\MYPC\AppData\Local\Programs\Python\Python38\lib\site-packages\scipy\io\wavfile.py”, line 267, in read
file_size, is_big_endian = _read_riff_chunk(fid)
File “C:\Users\MYPC\AppData\Local\Programs\Python\Python38\lib\site-packages\scipy\io\wavfile.py”, line 167, in _read_riff_chunk
raise ValueError(“File format {}… not ”
ValueError: File format b’.snd’… not understood.
can anyone help me with this
in distance(instance1, instance2, k)
12 cm2 = instance2[1]
13 distance = np.trace(np.dot(np.linalg.inv(cm2), cm1))
—> 14 distance+=(np.dot(np.dot((mm2-mm1),transpose() , np.linalg.inv(cm2-cm1))))
15 distance+= np.log(np.linalg.det(cm2)) – np.log(np.linalg.det(cm1))
16 distance-= k
NameError: name ‘transpose’ is not defined
please resolve the problem.
When running step 5 (dumping features into my.dat), I get an error that I just can’t understand. Also, I’m confused; am I supposed to replace “folder + “/” + file” with the names of folders on my machine or does that resolve to the respective files automatically?
—————————————————————————
ValueError Traceback (most recent call last)
in
8 break
9 for file in os.listdir(directory + folder):
—> 10 (rate,sig) = wav.read(directory + folder + “/” + file)
11 mfcc_feat = mfcc(sig, rate, winlen = 0.020, appendEnergy = False)
12 covariance = np.cov(np.matrix.transpose(mfcc_feat))
/path/to/virtual/environment/python3.6/site-packages/scipy/io/wavfile.py in read(filename, mmap)
545
546 try:
–> 547 file_size, is_big_endian = _read_riff_chunk(fid)
548 fmt_chunk_received = False
549 data_chunk_received = False
/path/to/virtual/environment/python3.6/site-packages/scipy/io/wavfile.py in _read_riff_chunk(fid)
444 else:
445 # There are also .wav files with “FFIR” or “XFIR” signatures?
–> 446 raise ValueError(f”File format {repr(str1)} not understood. Only ”
447 “‘RIFF’ and ‘RIFX’ supported.”)
448
ValueError: File format b’/Use’ not understood. Only ‘RIFF’ and ‘RIFX’ supported.
(I’m using 3.6 because I couldn’t get python_speech_features to install on any newer versions)
Any help is appreciated
Hey, were you able to figure this out? I am facing the same error and I don’t understand how to fix it
I got this error
dist = distances(trainingSet[x], instance, k )+ distances(instance, trainingSet[x], k)
‘list’ object is not callable
Can Anybody Help me out with this
NotADirectoryError: [Errno 20] Not a directory: ‘/content/drive/MyDrive/genres/bextract_single.mf’
Since The Dataset Folder consists of .mf Files its causing this error please help me out ASAP
You can use os.walk() instead of the method described here
In part 2, within the ‘getNeighbors’ function, you call another function ‘distance()’, yet you fail to show define function in the tutorial. I have noticed that a lot of these DataFlair tutorials don’t actually run properly. The code that is used has very little readability or transparency. Very confusing if a beginner were to come on here to try to learn.
where are the tutorials?
And also, what all did he compute in the distance function, I could identify (after a lot of googling), two of the three values he calculates.
What is the logic behind the “distance” and “getNeighbours” functions? Seems like a lot of mathematics, especially with the inverses and traces and all that. Can you post a link explaining it or something?
i got this error, can anyone help
ZeroDivisionError Traceback (most recent call last)
in
5 predictions.append(nearest_class(getNeighbors(training_set, testing_set[x], 5)))
6
—-> 7 accuracy = get_accuracy(testing_set, predictions)
8 print(accuracy)
in get_accuracy(testing_set, predictions)
6 correct += 1
7
—-> 8 return 1.0*correct/length
ZeroDivisionError: float division by zero
dataset path isnt pathed well
Can Anyoone please help me with this error
Traceback (most recent call last):
File “C:\Users\91738\OneDrive\Desktop\PYTHON\Program Assignments\Music genre classifivcation\Attempt 1.py”, line 24, in
loadDataset(“my.dat”)
File “C:\Users\91738\OneDrive\Desktop\PYTHON\Program Assignments\Music genre classifivcation\Attempt 1.py”, line 16, in loadDataset
with open(“my.dat” , ‘rb’) as f:
FileNotFoundError: [Errno 2] No such file or directory: ‘my.dat’
I think that i am not able to make the program access the data set .
plz help me on this.
I need machine genre classification by machine learning in java
Traceback (most recent call last):
File “D:\Music Genre Classification\music_genre.py”, line 65, in
(rate,sig) = wav.read(directory+folder+”/”+file)
File “C:\Users\\AppData\Local\Programs\Python\Python310\lib\site-packages\scipy\io\wavfile.py”, line 650, in read
file_size, is_big_endian = _read_riff_chunk(fid)
File “C:\Users\\AppData\Local\Programs\Python\Python310\lib\site-packages\scipy\io\wavfile.py”, line 521, in _read_riff_chunk
raise ValueError(f”File format {repr(str1)} not understood. Only ”
ValueError: File format b’/Use’ not understood. Only ‘RIFF’ and ‘RIFX’ supported.
CAN ANYONE PLEASE HELP TO SOLVE THIS ERROR??
Traceback (most recent call last):
File “D:\Music Genre Classification\music_genre.py”, line 65, in
(rate,sig) = wav.read(directory+folder+”/”+file)
File “C:\Users\\AppData\Local\Programs\Python\Python310\lib\site-packages\scipy\io\wavfile.py”, line 650, in read
file_size, is_big_endian = _read_riff_chunk(fid)
File “C:\Users\\AppData\Local\Programs\Python\Python310\lib\site-packages\scipy\io\wavfile.py”, line 521, in _read_riff_chunk
raise ValueError(f”File format {repr(str1)} not understood. Only ”
ValueError: File format b’/Use’ not understood. Only ‘RIFF’ and ‘RIFX’ supported.
Can you help me how to solve this error?
CAN ANYONE HELP ME SOLVE THIS ERROR. I’VE TRIED REMOVING JAZZ FILE TOO.IT’S NOT WORKING.
Traceback (most recent call last):
File “D:\Music Genre Classification\music_genre.py”, line 65, in
(rate,sig) = wav.read(directory+folder+”/”+file)
File “C:\Users\Divya\AppData\Local\Programs\Python\Python310\lib\site-packages\scipy\io\wavfile.py”, line 650, in read
file_size, is_big_endian = _read_riff_chunk(fid)
File “C:\Users\Divya\AppData\Local\Programs\Python\Python310\lib\site-packages\scipy\io\wavfile.py”, line 521, in _read_riff_chunk
raise ValueError(f”File format {repr(str1)} not understood. Only ”
ValueError: File format b’/Use’ not understood. Only ‘RIFF’ and ‘RIFX’ supported.
unable to download dataset from the link
yes dood. I can’t reach that site.
could anyone send it?
same question,are you solve now?
Can I get help regarding the below mentioned error..!!
Traceback (most recent call last):
File “c:\Users\Harshan\OneDrive\Desktop\mu\music_genre.py”, line 54, in
(rate,sig) = wav.read(directory+folder+”/”+file)
File “C:\Users\Harshan\AppData\Local\Programs\Python\Python310\lib\site-packages\scipy\io\wavfile.py”, line 650, in read
file_size, is_big_endian = _read_riff_chunk(fid)
File “C:\Users\Harshan\AppData\Local\Programs\Python\Python310\lib\site-packages\scipy\io\wavfile.py”, line 521, in _read_riff_chunk
raise ValueError(f”File format {repr(str1)} not understood. Only ”
ValueError: File format b’.snd’ not understood. Only ‘RIFF’ and ‘RIFX’ supported.
heyy plz help how should i solve this error, step no:7
3 for x in range (leng):
4 predictions.append(nearestClass(getNeighbors(trainingSet ,testSet[x] , 5)))
—-> 5 accuracy0 = getAccuracy(testSet , predictions)
6 print(accuracy0)
Cell In[9], line 6, in getAccuracy(testSet, predictions)
4 if testSet[x][-1]==predictions[x]:
5 correct+=1
—-> 6 return 1.0*correct/len(testSet)
ZeroDivisionError: float division by zero
Can anyone help how to run this project python3 test.py next step after this