Detecting Fake News with Python and Machine Learning
Machine Learning courses with 100+ Real-time projects Start Now!!
Do you trust all the news you hear from social media?
All news are not real, right?
How will you detect fake news?
The answer is Python. By practicing this advanced python project of detecting fake news, you will easily make a difference between real and fake news.
Before moving ahead in this machine learning project, get aware of the terms related to it like fake news, tfidfvectorizer, PassiveAggressive Classifier.
Also, I like to add that DataFlair has published a series of machine learning Projects where you will get interesting and open-source advanced ml projects. Do check, and then share your experience through comments. Here is the list of top Python projects:
- Fake News Detection Python Project
- Parkinson’s Disease Detection Python Project
- Color Detection Python Project
- Speech Emotion Recognition Python Project
- Breast Cancer Classification Python Project
- Age and Gender Detection Python Project
- Handwritten Digit Recognition Python Project
- Chatbot Python Project
- Driver Drowsiness Detection Python Project
- Traffic Signs Recognition Python Project
- Image Caption Generator Python Project
What is Fake News?
A type of yellow journalism, fake news encapsulates pieces of news that may be hoaxes and is generally spread through social media and other online media. This is often done to further or impose certain ideas and is often achieved with political agendas. Such news items may contain false and/or exaggerated claims, and may end up being viralized by algorithms, and users may end up in a filter bubble.
What is a TfidfVectorizer?
TF (Term Frequency): The number of times a word appears in a document is its Term Frequency. A higher value means a term appears more often than others, and so, the document is a good match when the term is part of the search terms.
IDF (Inverse Document Frequency): Words that occur many times a document, but also occur many times in many others, may be irrelevant. IDF is a measure of how significant a term is in the entire corpus.
The TfidfVectorizer converts a collection of raw documents into a matrix of TF-IDF features.
What is a PassiveAggressiveClassifier?
Passive Aggressive algorithms are online learning algorithms. Such an algorithm remains passive for a correct classification outcome, and turns aggressive in the event of a miscalculation, updating and adjusting. Unlike most other algorithms, it does not converge. Its purpose is to make updates that correct the loss, causing very little change in the norm of the weight vector.
Detecting Fake News with Python
To build a model to accurately classify a piece of news as REAL or FAKE.
About Detecting Fake News with Python
This advanced python project of detecting fake news deals with fake and real news. Using sklearn, we build a TfidfVectorizer on our dataset. Then, we initialize a PassiveAggressive Classifier and fit the model. In the end, the accuracy score and the confusion matrix tell us how well our model fares.
The fake news Dataset
The dataset we’ll use for this python project- we’ll call it news.csv. This dataset has a shape of 7796×4. The first column identifies the news, the second and third are the title and text, and the fourth column has labels denoting whether the news is REAL or FAKE. The dataset takes up 29.2MB of space and you can download it here.
Project Prerequisites
You’ll need to install the following libraries with pip:
pip install numpy pandas sklearn
You’ll need to install Jupyter Lab to run your code. Get to your command prompt and run the following command:
C:\Users\DataFlair>jupyter lab
You’ll see a new browser window open up; create a new console and use it to run your code. To run multiple lines of code at once, press Shift+Enter.
Steps for detecting fake news with Python
Follow the below steps for detecting fake news and complete your first advanced Python Project –
1. Make necessary imports:
import numpy as np import pandas as pd import itertools from sklearn.model_selection import train_test_split from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.linear_model import PassiveAggressiveClassifier from sklearn.metrics import accuracy_score, confusion_matrix
Screenshot:
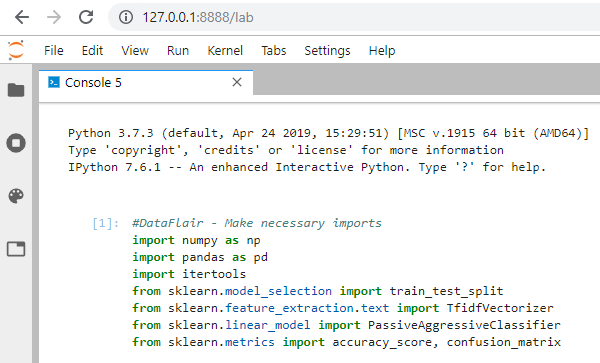
2. Now, let’s read the data into a DataFrame, and get the shape of the data and the first 5 records.
#Read the data
df=pd.read_csv('D:\\DataFlair\\news.csv')
#Get shape and head
df.shape
df.head()Output Screenshot:
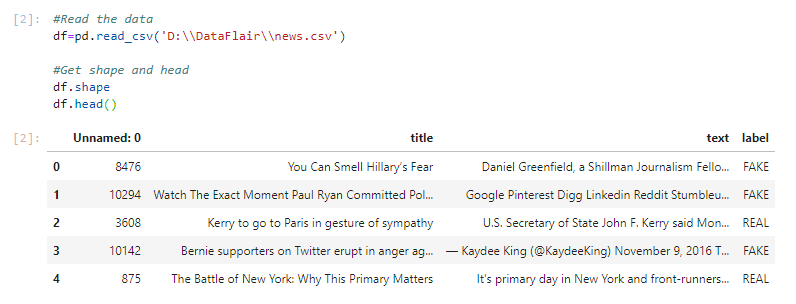
3. And get the labels from the DataFrame.
#DataFlair - Get the labels labels=df.label labels.head()
Output Screenshot:
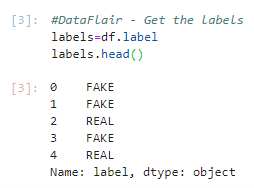
4. Split the dataset into training and testing sets.
#DataFlair - Split the dataset x_train,x_test,y_train,y_test=train_test_split(df['text'], labels, test_size=0.2, random_state=7)
Screenshot:

5. Let’s initialize a TfidfVectorizer with stop words from the English language and a maximum document frequency of 0.7 (terms with a higher document frequency will be discarded). Stop words are the most common words in a language that are to be filtered out before processing the natural language data. And a TfidfVectorizer turns a collection of raw documents into a matrix of TF-IDF features.
Now, fit and transform the vectorizer on the train set, and transform the vectorizer on the test set.
#DataFlair - Initialize a TfidfVectorizer tfidf_vectorizer=TfidfVectorizer(stop_words='english', max_df=0.7) #DataFlair - Fit and transform train set, transform test set tfidf_train=tfidf_vectorizer.fit_transform(x_train) tfidf_test=tfidf_vectorizer.transform(x_test)
Screenshot:

6. Next, we’ll initialize a PassiveAggressiveClassifier. This is. We’ll fit this on tfidf_train and y_train.
Then, we’ll predict on the test set from the TfidfVectorizer and calculate the accuracy with accuracy_score() from sklearn.metrics.
#DataFlair - Initialize a PassiveAggressiveClassifier
pac=PassiveAggressiveClassifier(max_iter=50)
pac.fit(tfidf_train,y_train)
#DataFlair - Predict on the test set and calculate accuracy
y_pred=pac.predict(tfidf_test)
score=accuracy_score(y_test,y_pred)
print(f'Accuracy: {round(score*100,2)}%')Output Screenshot:
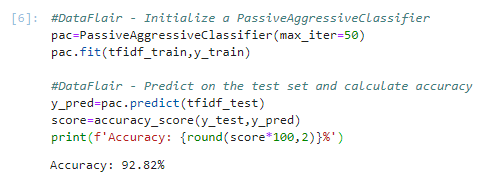
7. We got an accuracy of 92.82% with this model. Finally, let’s print out a confusion matrix to gain insight into the number of false and true negatives and positives.
#DataFlair - Build confusion matrix confusion_matrix(y_test,y_pred, labels=['FAKE','REAL'])
Output Screenshot:
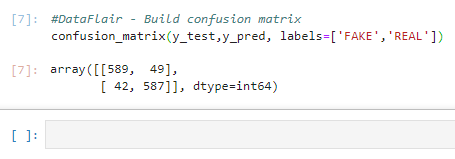
So with this model, we have 589 true positives, 587 true negatives, 42 false positives, and 49 false negatives.
Summary
Fake news spreads quickly on the internet and can cause serious problems. It can confuse people, create panic, or spread lies. A Machine Learning project in Python can help solve this issue. Using Natural Language Processing (NLP), we can build a model that reads the news headline or article and predicts if it’s real or fake. This project helps people and media companies check information before trusting it.
Today, we learned to detect fake news with Python. We took a political dataset, implemented a TfidfVectorizer, initialized a PassiveAggressiveClassifier, and fit our model. We ended up obtaining an accuracy of 92.82% in magnitude.
This project is very useful in today’s digital world. You can also make a simple website using Flask where users paste a news headline and see if it’s fake or not. It’s a practical and timely project to learn NLP, text classification, and real-world machine learning. Plus, it helps make the internet a safer place for information sharing.
Hope you enjoyed the fake news detection python project. Keep visiting DataFlair for more interesting python, data science, and machine learning projects.
Your opinion matters
Please write your valuable feedback about DataFlair on Google





how to create dataset?
Dataset cannot be created, it is a collection of existing data. Data can be collected mainly in two ways – 1) generated data that are observed (say, milk packets coming out of a packing machine with weights), and 2) asking questions to people.
I am getting following error, Kindly help.
ValueError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_388/4183239203.py in
3
4 # Fit and transform the vectorizer on the train set, and transform the vectorizer on the test set
—-> 5 tfidf_train = tfidf_vectorizer.fit_transform(x_train)
6 tfidf_test = tfidf_vectorizer.transform(x_test)
~\anaconda3\lib\site-packages\sklearn\feature_extraction\text.py in fit_transform(self, raw_documents, y)
1844 “””
1845 self._check_params()
-> 1846 X = super().fit_transform(raw_documents)
1847 self._tfidf.fit(X)
1848 # X is already a transformed view of raw_documents so
~\anaconda3\lib\site-packages\sklearn\feature_extraction\text.py in fit_transform(self, raw_documents, y)
1200 max_features = self.max_features
1201
-> 1202 vocabulary, X = self._count_vocab(raw_documents,
1203 self.fixed_vocabulary_)
1204
~\anaconda3\lib\site-packages\sklearn\feature_extraction\text.py in _count_vocab(self, raw_documents, fixed_vocab)
1104 vocabulary.default_factory = vocabulary.__len__
1105
-> 1106 analyze = self.build_analyzer()
1107 j_indices = []
1108 indptr = []
~\anaconda3\lib\site-packages\sklearn\feature_extraction\text.py in build_analyzer(self)
425
426 elif self.analyzer == ‘word’:
–> 427 stop_words = self.get_stop_words()
428 tokenize = self.build_tokenizer()
429 self._check_stop_words_consistency(stop_words, preprocess,
~\anaconda3\lib\site-packages\sklearn\feature_extraction\text.py in get_stop_words(self)
358 A list of stop words.
359 “””
–> 360 return _check_stop_list(self.stop_words)
361
362 def _check_stop_words_consistency(self, stop_words, preprocess, tokenize):
~\anaconda3\lib\site-packages\sklearn\feature_extraction\text.py in _check_stop_list(stop)
177 return ENGLISH_STOP_WORDS
178 elif isinstance(stop, str):
–> 179 raise ValueError(“not a built-in stop list: %s” % stop)
180 elif stop is None:
181 return None
ValueError: not a built-in stop list: English
its english in small letters
Do I get the source code please?
i didnt get any source code
Source code of this fake news project is published in the article, please copy and use
where is article?i also need the source code please
# So with this model, we have 589 true positives, 587 true negatives, 42 false positives, and 49 false negatives.
this is your statement. I believe you have misinterpreted, you have given (y_test, pred_y) in the confusion matrix which justifies 589 is True Negative, 587 True Positive, 49 False Positive and 42 False Negatives.
Please reconfirm.
Thank you for the article it is worth of million.
I also have same doubt
Hi , can you please help me with below error
ValueError: Found input variables with inconsistent numbers of samples: [5068, 1267]
check if your code is the same as mine, then make corrections.
y_pred = pac.predict(tfidf_test)
How can I use this on other news articles? I mean, if I find an article online and I want to see what percentage chance is there that it’s fake news?
if you can get the dataset of that particular news article, you can insert the dataset into this source code, and you can know if its real or fake.
i am getting this error. help
—————————————————————————
ModuleNotFoundError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_9696/3872586496.py in
—-> 1 import intertools
2 from sklearn.model_selection import train_test_split
3 from sklearn.feature_extraction.text import TfidfVectorizer
4 from sklearn.linear_model import PassiveAggressiveClassifier
5 from sklearn.metrics import accuracy_score, confusion_matrix
ModuleNotFoundError: No module named ‘intertools’
pleasee
type ‘import itertools’ not ‘import intertools’ – it was a spelling mistake
you misspelled itertools as intertools.
tfidf_train=tfidf_vectorizer.fit_transform(x_train)
tfidf_test=tfidf_vectorizer.transform(x_test)
I kept receiving an error message when running this
package install is not check the installation once
How to give input to model for prediction
Hello,
If I understood correctly, we have a dataset with a text and a label to know if the text is truthful or sensationalist. One of the methods to find the truthfulness of a text is to calculate the frequency of words in the text.
What I don’t understand is what we are supposed to do with it. And how the PassiveAggressiveClassifier impacts this.
I have this as project for a data mining course, I hate my professor, but thank you all for the article it really helped a lot <3
satara is the biggest city
Getting this after executing
tfidf_train=tfidf_vectorizer.fit_transform(x_train)
tfidf_test=tfidf_vectorizer.fit_transform(x_test)
pac=PassiveAggressiveClassifier(max_iter= 50)
pac.fit(tfidf_train,y_train)
y_pred=pac.predict(tfidf_test)
score=accuracy_score(y_test,y_pred)
print(f’Accuracy: {round(score*100,2)}%’)
ValueError: X has 33518 features, but PassiveAggressiveClassifier is expecting 61651 features as input.
this project are hopefully collected
Good
Thank you for sharing your insightful article on “Leveraging Python and Machine Learning for Detecting Fake News.” This fascinating topic highlights the crucial role Python plays in web agency marketing by enabling the identification and mitigation of misinformation. By harnessing the power of advanced algorithms and data analysis techniques, we can enhance our ability to combat fake news effectively. Your valuable insights and methodologies contribute to the ongoing battle against misinformation, while also showcasing the potential of Python in empowering web agency marketing efforts. Keep up the excellent work in utilizing Python to promote truth and accuracy in the digital landscape!
How will I be able to characterize the confusion matrix? I want to find which specific data points in the CSV file which were used for testing ended up as false negatives / positives so I can perform some further analysis on those specific data points.
Hello
I want the python code to improve the accuracy of cyber threat intelligence against onion services to detect malware attacks using deep learning
Can you help me to find the F score and recall to the same data set
It is a very useful website who didn’t complete the project. They can easily understand by reading this website.
I really liked this project! I think I did it right but I adapted it a little bit so I could try inputting some news articles on my own, but every time I got the article was “FAKE” even when from reputable sources (BBC, NYT, Washington Post). Wonder how I could fix that.
How can I add a new data to see how it predict?
#Read the data
df = pd.read_csv(‘C:/Users/Downloads/news/news.csv’)
#Get shape and head
df.shape
df.head()
I have the same error file not found even after updation of the correct path
How would you deploy this on streamlit?
How would you deploy this on streamlit??
how to deploy this,please help
how to deploy this,please help??
excellent code. but this has too many errors. i will consult ai to assist me in using this via vscode. bye.
actually i have learnt a lot from this code my apologies. it was a typo on a few lines. i have not built a nice app. i want to use tkinter to make a beautiful interface!