Convert Text to Speech in Python
Master Python with 70+ Hands-on Projects and Get Job-ready - Learn Python
Learn how to convert your Text into Voice with Python and Google APIs
Text to speech is a process to convert any text into voice. Text to speech project takes words on digital devices and convert them into audio with a button click or finger touch. Text to speech python project is very helpful for people who are struggling with reading.
Project Prerequisites
To implement this project, we will use the basic concepts of Python, Tkinter, gTTS, and playsound libraries.
- Tkinter is a standard GUI Python library that is one of the fastest and easiest ways to build GUI applications using Tkinter.
- gTTS (Google Text-to-Speech) is a Python library, which is a very easy library that converts the text into audio.
- The playsound module is used to play audio files. With this module, we can play a sound file with a single line of code.
To install the required libraries, you can use pip install command:
pip install tkinter pip install gTTS pip install playsound
Download Python Text to Speech Project Code
Please download the source code of Text to Speech Project: Python Text to Speech
Text to Speech Python Project
The objective of this project is to convert the text into voice with the click of a button. This project will be developed using Tkinter, gTTs, and playsound library.
In this project, we add a message which we want to convert into voice and click on play button to play the voice of that text message.
- Importing the modules
- Create the display window
- Define functions
So these are the basic steps that we will do in this Python project. Let’s start.
1. Import Libraries
Let’s start by importing the libraries: tkinter, gTTS, and playsound
from tkinter import * From gtts import gTTS From playsound import playsound
2. Initializing window
root = Tk()
geometry root.("350x300")
root.configure(bg='ghost white')
root.title("DataFlair - TEXT TO SPEECH")
- Tk() to initialized tkinter which will be used for GUI
- geometry() used to set the width and height of the window
- configure() used to access window attributes
- bg will used to set the color of the background
- title() set the title of the window
Label(root, text = "TEXT_TO_SPEECH", font = "arial 20 bold", bg='white smoke').pack() Label(text ="DataFlair", font = 'arial 15 bold', bg ='white smoke' , width = '20').pack(side = 'bottom') Msg = StringVar() Label(root,text ="Enter Text", font = 'arial 15 bold', bg ='white smoke').place(x=20,y=60) entry_field = Entry(root, textvariable = Msg ,width ='50') entry_field.place(x=20,y=100)
Label() widget is used to display one or more than one line of text that users can’t able to modify.
- root is the name which we refer to our window
- text which we display on the label
- font in which the text is written
- pack organized widget in block
- Msg is a string type variable
- Entry() used to create an input text field
- textvariable used to retrieve the current text to entry widget
- place() organizes widgets by placing them in a specific position in the parent widget
3. Function to Convert Text to Speech in Python
def Text_to_speech():
Message = entry_field.get()
speech = gTTS(text = Message)
speech.save('DataFlair.mp3')
playsound('DataFlair.mp3')
- Message variable will stores the value of entry_field
- text is the sentences or text to be read.
- lang takes the language to read the text. The default language is English.
- slow use to reads text more slowly. The default is False.
As we want the default value of lang, so no need to give that to gTTS.
- speech stores the converted voice from the text
- speech.save(‘DataFlair.mp3’) will saves the converted file as DataFlair as mp3 file
- playsound() used to play the sound
4. Function to Exit
def Exit():
root.destroy()
root.destroy() will quit the program by stopping the mainloop().
5. Function to Reset
def Reset():
Msg.set("")
Reset function set Msg variable to empty strings.
6. Define Buttons
Button(root, text = "PLAY", font = 'arial 15 bold' , command = Text_to_speech ,width = '4').place(x=25,y=140) Button(root, font = 'arial 15 bold',text = 'EXIT', width = '4' , command = Exit, bg = 'OrangeRed1').place(x=100 , y = 140) Button(root, font = 'arial 15 bold',text = 'RESET', width = '6' , command = Reset).place(x=175 , y = 140)
Button() widget used to display button on the window
root.mainloop()
root.mainloop() is a method that executes when we want to run our program.
Python Text to Speech Project Output
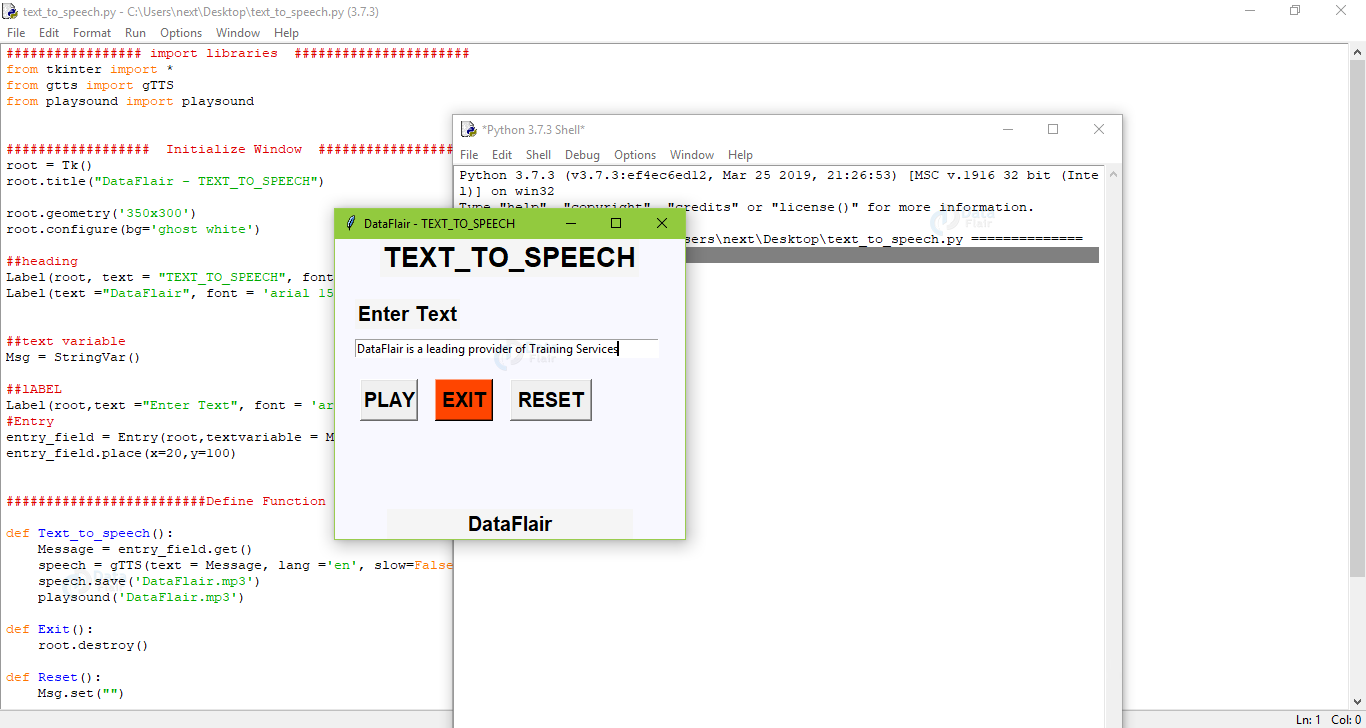
Summary
We have successfully developed the text to speech python project. We used the popular tkinter library for rendering graphics on a display window, gTTs (google text to speech) library to convert text to voice, and playsound library to play that converter voice from the text.
Did you know we work 24x7 to provide you best tutorials
Please encourage us - write a review on Google





The project doesn’t allow the play button to be used more than once on clicking. Once the play is clicked, second attempt doesn’t work. I receive the following error on running the actual source code.
Exception in Tkinter callback
Traceback (most recent call last):
File “C:\Users\aashi\anaconda3\lib\tkinter\__init__.py”, line 1705, in __call__
return self.func(*args)
File “Text-to-Speech.py”, line 43, in Text_to_speech
speech.save(‘DataFlair.mp3’)
File “C:\Users\aashi\anaconda3\lib\site-packages\gtts\tts.py”, line 294, in save
with open(str(savefile), ‘wb’) as f:
PermissionError: [Errno 13] Permission denied: ‘DataFlair.mp3’
Yeah… You have to rerun the project to use the app again. It is because we are saving the mp3 file as dataflair.mp3 and if we use the play button twice from the same window then it will again try to create a new mp3 file with the same name which is not possible, so it will try to replace the existing dataflair.mp3 file which is not allowed and that’s why it is showing permission denied.
It would be easier to use pyttsx3 for text to speech. You don’t have to save audio files in that.
#Code
# pip install pyttsx3
import pyttsx3
def speak(txt):
engine = pyttsx3.init()
engine.say(txt)
engine.runAndWait()
speak(‘hello’)
is there any tutorial on speech to text using python ?
You can read the documentation of gTTS (Google Text-to-Speech) library which is available on the internet. It is a python library that acts as an interface with google Translate’s text-to-speech API.
yeah. i faced it too. in the reset button, add a simple command to delete the existing dataflare.mp3 file.
so when u press the reset button the mp3 file will be deleted and you don’t get the above error.
That’s a good option, based on the requirements we can update the project.
What is the command to delete the existing dataflare.mp3 file.
If like me, you don’t want a reset button, you can simply add a line after “Playsound(‘DataFlair.mp3’)” that deletes the file, therefore allowing you to repeatedly change what you’re writing in the TTS without having to reset at all.
yeah, That’s another option, and yes, based on the requirements we can update this python project as we have hand-coded the logic.
Sir i am getting the same error. Plesae provide the solution to overcome this problem.
You would need to import os library and add the following line in def Text_to_speech(): after playsound(‘T2S.mp3’)
os.remove(‘T2S.mp3’)
Worked for me
sir , when i clicking on reset button, they are giving Permission denied.
then ,how can remove Permission denied to play more than one string in single of running program?
You will have to rerun the program to play the sound again because if you rerun, it will try to create dataflair.mp3 file again i.e. with the same name, which will give permission denied error
sir i am getting this error, please help me with this
Exception in Tkinter callback
Traceback (most recent call last):
File “C:\Users\jgaur\anaconda3\lib\tkinter\__init__.py”, line 1705, in __call__
return self.func(*args)
File “C:/Users/jgaur/PycharmProjects/pythonProject1/TextToSpeech.py”, line 43, in Text_to_speech
speech.save(‘DataFlair.mp3’)
File “C:\Users\jgaur\anaconda3\lib\site-packages\gtts\tts.py”, line 295, in save
self.write_to_fp(f)
File “C:\Users\jgaur\anaconda3\lib\site-packages\gtts\tts.py”, line 251, in write_to_fp
prepared_requests = self._prepare_requests()
File “C:\Users\jgaur\anaconda3\lib\site-packages\gtts\tts.py”, line 194, in _prepare_requests
part_tk = self.token.calculate_token(part)
File “C:\Users\jgaur\anaconda3\lib\site-packages\gtts_token\gtts_token.py”, line 36, in calculate_token
seed = self._get_token_key()
File “C:\Users\jgaur\anaconda3\lib\site-packages\gtts_token\gtts_token.py”, line 71, in _get_token_key
return self._get_token_key(retry=retry + 1)
File “C:\Users\jgaur\anaconda3\lib\site-packages\gtts_token\gtts_token.py”, line 71, in _get_token_key
return self._get_token_key(retry=retry + 1)
File “C:\Users\jgaur\anaconda3\lib\site-packages\gtts_token\gtts_token.py”, line 71, in _get_token_key
return self._get_token_key(retry=retry + 1)
[Previous line repeated 2 more times]
File “C:\Users\jgaur\anaconda3\lib\site-packages\gtts_token\gtts_token.py”, line 68, in _get_token_key
“Unable to find token seed! Did https://translate.google.com change?”
ValueError: Unable to find token seed! Did https://translate.google.com change?
It was because there were some changes in gtts but now it is working fine. Please download the project and try again.
Instead try this function,
def Text_to_speech():
Message = entry_field.get()
speech = gTTS(text = Message)
speech.save(f'{Message}.mp3′)
playsound(f'{Message}.mp3′)
os.remove(f'{Message}.mp3′)
Can i get Data flow diagram of text to speech ..?
import os
def Text_to_speech():
Message = entry_field.get()
speech = gTTS(text = Message)
speech.save(‘bhanu.mp3’)
playsound(‘bhanu.mp3’)
os.remove(‘bhanu.mp3’)
while installing tkinter I am getting an error as below,what do I do?
ERROR: Could not find a version that satisfies the requirement tkinter (from versions: none)
ERROR: No matching distribution found for tkinter
Plz respond as sson as possible.
Same problem regarding tkinter installation, even after updating the version it is still giving the error and have even tried using tk interface but still the same error.
Please respond what can be done…
Same problem regarding tkinter installation, even after updating the version it is still giving the error and have even tried using tk interface but still the same error.
Please respond what can be done…
It would be easier to use pyttsx3 for text to speech. You don’t have to save audio files in that.
#Code
# pip install pyttsx3
import pyttsx3
def speak(txt):
engine = pyttsx3.init()
engine.say(txt)
engine.runAndWait()
speak(‘hello’)
Great. This is working perfectly.
please update this:
root = Tk()
root.geometry (“350×300”)
root.configure(bg=’ghost white’)
root.title(“DataFlair – TEXT TO SPEECH”)
text to smooth speech conversion is possible with this?
i am unable to run pip install tkinter
which version of python to use??
Someone can help me please
“C:\Users\Harel Cohen\AppData\Local\Programs\Python\Python39\python.exe” “C:/Users/Harel Cohen/PycharmProjects/pythonProject/Text_to_Speech.py”
Error 259 for command:
play DataFlair.mp3 wait
The driver cannot recognize the specified command parameter.
Exception in Tkinter callback
Traceback (most recent call last):
File “C:\Users\Harel Cohen\AppData\Local\Programs\Python\Python39\lib\tkinter\__init__.py”, line 1892, in __call__
return self.func(*args)
File “C:\Users\Harel Cohen\PycharmProjects\pythonProject\Text_to_Speech.py”, line 27, in Text_to_speech
playsound(‘DataFlair.mp3′)
File “C:\Users\Harel Cohen\AppData\Local\Programs\Python\Python39\lib\site-packages\playsound.py”, line 73, in _playsoundWin
winCommand(u’play {}{}’.format(sound, ‘ wait’ if block else ”))
File “C:\Users\Harel Cohen\AppData\Local\Programs\Python\Python39\lib\site-packages\playsound.py”, line 64, in winCommand
raise PlaysoundException(exceptionMessage)
playsound.PlaysoundException:
Error 259 for command:
play DataFlair.mp3 wait
The driver cannot recognize the specified command parameter.
Process finished with exit code 0
is good python langaug
Hi,
You are using gTTS (Google Text-to-Speech): is it free to use for my company for a chatbot solution?
Thanks.
how can i create a frontend for which my chatbot will take the input via speech and gives output in speech and text like tkinter
import tkinter as tk
from gtts import gTTS
import os
def Text_to_speech():
message = entry_field.get()
if message:
# Create a gTTS object
speech = gTTS(text=message)
# Save the audio in your user directory
save_path = f’C:/Users/{os.getlogin()}/DataFlair.mp3′
# Save the audio to the specified path
speech.save(save_path)
# Play the audio using a system command
os.system(f’start {save_path}’)
else:
print(“No text entered”)
root = tk.Tk()
root.geometry(“350×300”)
root.configure(bg=’ghost white’)
root.title(“Text to Speech”)
label = tk.Label(root, text=”TEXT TO SPEECH”, font=”arial 20 bold”, bg=’white smoke’)
label.pack()
Msg = tk.StringVar()
label = tk.Label(root, text=”Enter Text”, font=’arial 15 bold’, bg=’white smoke’)
label.place(x=20, y=60)
entry_field = tk.Entry(root, textvariable=Msg, width=’50’)
entry_field.place(x=20, y=100)
play_button = tk.Button(root, text=”PLAY”, font=’arial 15 bold’, command=Text_to_speech, width=’4′)
play_button.place(x=25, y=140)
root.mainloop()
Can you help me debug?
import tkinter as tk
from gtts import gTTS
import os
def Text_to_speech():
message = entry_field.get()
if message:
# Create a gTTS object
speech = gTTS(text=’FUCK YOU’)
# Save the audio in your user directory
save_path = f’C:/Users/{os.getlogin()}/DataFlair.mp3′
# Save the audio to the specified path
speech.save(save_path)
# Play the audio using a system command
os.system(f’start {save_path}’)
else:
print(“No text entered”)
root = tk.Tk()
root.geometry(“350×300”)
root.configure(bg=’ghost white’)
root.title(“Text to Speech”)
label = tk.Label(root, text=”FUCK YOU”, font=”arial 20 bold”, bg=’white smoke’)
label.pack()
Msg = tk.StringVar()
label = tk.Label(root, text=”Enter Text”, font=’arial 15 bold’, bg=’white smoke’)
label.place(x=20, y=60)
entry_field = tk.Entry(root, textvariable=Msg, width=’50’)
entry_field.place(x=20, y=100)
play_button = tk.Button(root, text=”PLAY”, font=’arial 15 bold’, command=Text_to_speech, width=’4′)
play_button.place(x=25, y=140)
root.mainloop()