Clustering in Machine Learning – Algorithms that Every Data Scientist Uses
Machine Learning courses with 100+ Real-time projects Start Now!!
Do you wish to market products of your client in a better way to a specific audience? If yes, then clustering is for you. I mean you need to understand the concept of unsupervised learning and clustering in machine learning in the best way. What is that best way? Learn clustering and its algorithms with the help of proper examples and real-life applications. Today in this clustering machine learning tutorial, we will discuss the same. The outline of this tutorial is –
- What is Clustering?
- Why Clustering in Machine Learning?
- Types of Clustering Algorithms in Machine Learning
- Clustering Examples
- Applications of Clustering
So, before we start our clustering tutorial, I recommend you to check the types of machine learning algorithms.
What is Clustering?
Clustering is the most popular technique in unsupervised learning where grouping of data is on the basis of similarity of the data-points. Clustering has many real-life applications where it can be used in a variety of situations.
The basic principle behind cluster is the assignment of a given set of observations into subgroups or clusters such that observations present in the same cluster possess a degree of similarity. It is the implementation of the human cognitive ability to discern objects based on their nature.
For example, when you go out for grocery shopping, you easily distinguish between apples and oranges in a given set containing both of them. You distinguish these two objects based on their color, texture and other sensory information that is processed by your brain. Clustering is an emulation of this process so that machines are able to distinguish between different objects.
It is a method of unsupervised learning since there is no external label attached to the object. The machine has to learn the features and patterns all by itself without any given input-output mapping. The algorithm is able to extract inferences from the nature of data objects and then create distinct classes to group them appropriately.
In clustering machine learning, the algorithm divides the population into different groups such that each data point is similar to the data-points in the same group and dissimilar to the data points in the other groups. On the basis of similarity and dissimilarity, it then assigns appropriate sub-group to the object.
Clustering in machine learning is a method whereby the population is split into several groups in a way that each data point is most similar to the points in the same cluster and less similar to the points in the different clusters. In many clustering algorithms, the distance metrics used often affect the results considerably, depending on the type of data under analysis or the intended objectives.
If you need to take a quick revision of any machine learning topic, you can check this free Machine Learning Tutorial Library.
Clustering Example– The data-points that are clustered together are in groups that hold similar data. Then we can further distinguish these clusters through the identification of three clusters as visualized below –
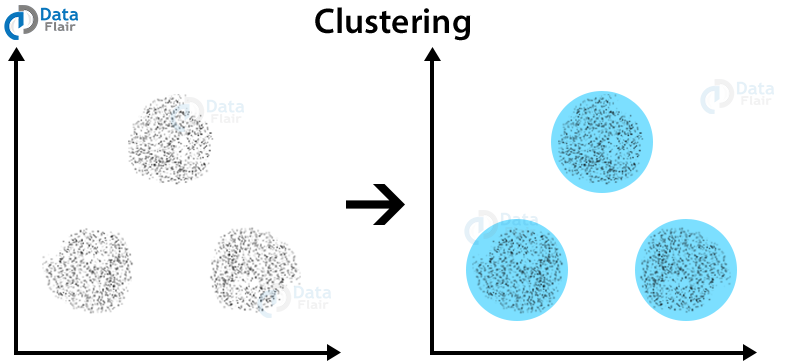
We perform clustering with a basic notion that the data points lie within the range of a cluster center. We make use of several distance methods and techniques for calculating the outliers.
Why Clustering?
Clustering is an important technique as it performs the determination of the intrinsic grouping among the unlabeled dataset. In clustering, there are no standard criteria. All of it depends on the user and the suitable criteria that satisfy their needs and requirements. For example, to find the homogeneous groups, one can find the representatives through data reduction and describe their suitable properties. One can also find unusual data objects for outlier detection. The algorithm then makes the assumption that constitutes what similarity of points makes valid assumptions.
When selecting the method of clustering, one might witness a significant effect on the results obtained. These parameters include the clusters’ number, distance function, and the algorithm’s robustness to noise and outliers that contribute significantly to the usefulness of resulting clusters. These subtleties are important for practitioners to know if they want to choose the right clustering algorithm for a particular application or want to adjust the settings for the best results.
Wait! Did you check the real-time applications of Machine Learning?
Types of Clustering Algorithms
In total, there are five distinct types of clustering algorithms. They are as follows –
- Partitioning Based Clustering
- Hierarchical Clustering
- Model-Based Clustering
- Density-Based Clustering
- Fuzzy Clustering
1. Partitioning Clustering
In this type of clustering, the algorithm subdivides the data into a subset of k groups. These k groups or clusters are pre-defined. It divides the data into clusters by satisfying these two requirements – Firstly, Each group should consist of at least one point. Secondly, each point must belong to exactly one group. K-Means Clustering is the most popular type of partitioning clustering method.
2. Hierarchical Clustering
The basic notion behind this type of clustering is to create a hierarchy of clusters. As opposed to Partitioning Clustering, it does not require pre-definition of clusters upon which the model is to be built. There are two ways to perform Hierarchical Clustering. The first approach is a bottom-up approach, also known as Agglomerative Approach and the second approach is the Divisive Approach which moves hierarchy of clusters in a top-down approach. As a result of this type of clustering, we obtain a tree-like representation known as a dendogram.
3. Density-Based Models
In these type of clusters, there are dense areas present in the data space that are separated from each other by sparser areas. These type of clustering algorithms play a crucial role in evaluating and finding non-linear shape structures based on density. The most popular density-based algorithm is DBSCAn which allows spatial clustering of data with noise. It makes use of two concepts – Data Reachability and Data Connectivity.
4. Model-Based Clustering
In this type of clustering technique, the data observed arises from a distribution consisting of a mixture of two or more cluster components. Furthermore, each component cluster has a density function having an associated probability or weight in this mixture.
5. Fuzzy Clustering
In this type of clustering, the data points can belong to more than one cluster. Each component present in the cluster has a membership coefficient that corresponds to a degree of being present in that cluster. Fuzzy Clustering method is a soft method of clustering.
Trending Machine Learning Project – Customer Segmentation using ML
Applications of Clustering
Some of the popular applications of clustering in machine learning are –
1. Clustering Algorithm for identification of cancer cells
Cancerous Datasets can be identified using clustering algorithms. In a mix of data consisting of both cancerous and non-cancerous data, the clustering algorithms are able to learn the various features present in the data upon which they produce the resulting clusters. Through experimentation, we observe that the cancerous data set gives us accurate results when given a model of unsupervised non-linear clustering algorithm.
2. Clustering Algorithm in Search Engines
While searching for something particular on Google, you receive a mix of similar results that match to your original query. This is a result of clustering that groups similar objects in a single cluster and provides that to you. Based on the nearest similar object, the data is assigned to the single cluster providing a comprehensive set of results to the user.
3. Clustering Algorithm in Wireless Networks
Using the clustering algorithm on the wireless nodes, we are able to save energy utilized by the wireless sensors. There are various clustering-based algorithms in wireless networks to improve their energy consumption and optimize data transmission.
4. Clustering for Customer Segmentation
One of the most popular applications of clustering is in the field of customer segmentation. Based on the analysis of the user-base, companies are able to identify customers who would prove to be potential users for their product or services.
Clustering allows them to segment customers into several clusters based on which they can adopt new strategies to appeal to their customer base. Now, you can practice the clustering concepts through the best ever machine learning project of the Customer Segmentation using Machine Learning.
Summary
Clustering is an unsupervised learning method. It helps group similar items without using labels. Algorithms like K-Means, DBSCAN, and Agglomerative Clustering help divide data into meaningful clusters.
Clustering is useful in marketing, biology, and image analysis. For example, it groups customers by shopping habits or pictures by objects. It helps find hidden patterns in large datasets.
It’s a key tool in machine learning that improves understanding and decision-making. Clustering gives insights from unstructured data and helps build more advanced ML models.
Did you enjoy the article? Share your feedback with us through comments.
Did you like our efforts? If Yes, please give DataFlair 5 Stars on Google





Nice tutorial for machine learning, anybody can easily learn from here.
please make a tutorial on types of clustering. it’s pretty good for me if you make a tutorial upon a hierarchical clustering.
Thank you ,Nice information.
can u able send corresponding python code for aggeleromative clustering for better understanding