Learn Types of Machine Learning Algorithms with Ultimate Use Cases
Free Machine Learning courses with 130+ real-time projects Start Now!!
In this article, we will study the various types of machine learning algorithms and their use-cases.
We will study how Baidu is using supervised learning-based facial recognition for intelligent airport check-in and how Google is making use of Reinforcement Learning to develop an intelligent platform that would answer your queries.
Machine Learning is a broad field, but it is classified into three classes of supervised, unsupervised and reinforcement learning. All these three paradigms are used everywhere to power intelligent applications.
We will look at the important use cases of these paradigms and how they are revolutionizing our world today.
What is Machine Learning?
Machine Learning allows the systems to make decisions autonomously without any external support.
These decisions are made when the machine is able to learn from the data and understand the underlying patterns that are contained within it.
Then, through pattern matching and further analysis, they return the outcome which can be a classification or a prediction.
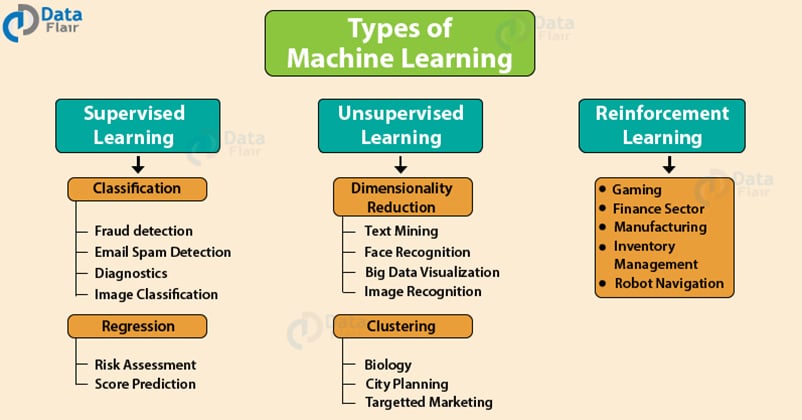
Types of Machine Learning
There are three important types of Machine Learning Algorithms that we will discuss in this tutorial –
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
Supervised Learning
Supervised Learning is the most popular paradigm for performing machine learning operations. It is widely used for data where there is a precise mapping between input-output data.
The dataset, in this case, is labeled, meaning that the algorithm identifies the features explicitly and carries out predictions or classification accordingly.
As the training period progresses, the algorithm is able to identify the relationships between the two variables such that we can predict a new outcome.
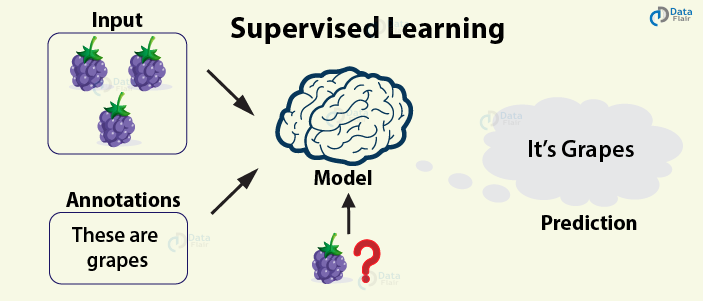
Resulting Supervised learning algorithms are task-oriented.
As we provide it with more and more examples, it is able to learn more properly so that it can undertake the task and yield us the output more accurately.
Some of the algorithms that come under supervised learning are as follows –
Linear Regression
Linear Regression may be a supervised machine learning algorithm where the anticipated output is continuous and features a constant slope. It’s to predict values within endless range, (e.g. sales, price) instead of trying to classify them into categories (e.g. cat, dog). It’s used whenever we want to predict the worth of a variable supported the worth of another variable.
The variable we would like to predict is named the variable (or sometimes, the result variable).
In linear regression, we measure the linear relationship between two or more than two variables. Based on this relationship, we perform predictions that follow this linear pattern.
Random Forest
Random forest may be a flexible, easy to use machine learning algorithm that produces, even without hyper-parameter tuning, an excellent result most of the time.
It’s also one among the foremost used algorithms, due to its simplicity and variety (it are often used for both classification and regression tasks).
Random Forests are an ensemble learning method that is for performing classification, regression as well as other tasks through the construction of decision trees and providing the output as a class which is the mode or mean of the underlying individual trees.
Gradient Boosting
Gradient boosting may be a machine learning technique for regression and classification problems, which produces a prediction model within the sort of an ensemble of weak prediction models, typically decision trees. It is an ensemble learning method that is a collection of several weak decision trees which results in a powerful classifier.
Support Vector Machine
SVMs are powerful classifiers that are used for classifying the binary dataset into two classes with the help of hyperplanes.
The benefits of support vector machines are Effective in high dimensional spaces. Still effective in cases where a number of dimensions is bigger than the number of samples.
Logistic Regression
Logistic regression may be a statistical model that in its basic form uses a logistic function to model a binary variable, although more complex extensions exist.
In multivariate analysis , logistic regression (or logit regression) is estimating the parameters of a logistic model (a sort of binary regression).
It makes use of a bell-shaped S curve that is generated with the help of logit function to categorize the data into their respective classes.
Artificial Neural Networks
Artificial Neural Networks are modeled after the human brain and they learn from the data over time. They form a much larger portion of machine learning called Deep Learning.
Supervised Learning Use Case
Facial Recognition is one of the most popular applications of Supervised Learning and more specifically – Artificial Neural Networks.
Convolutional Neural Networks (CNN) is a type of ANN used for identifying the faces of people. These models are able to draw features from the image through various filters. Finally, if there is a high similarity score between the input image and the image in the database, a positive match is provided.
Baidu, China’s premier search engine company has been investing in facial recognition. While it has already installed facial recognition systems in its security systems, it is now extending this technology to the major airports of China. Baidu will provide the airports with facial recognition technology that will provide access to the ground crew and the staff.
Therefore, the passengers do not have to wait in long queues for flight check-in when they can simply board their flight by scanning their faces.
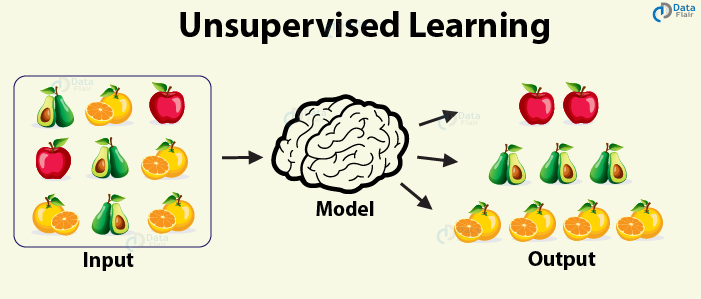
Unsupervised Learning
In the case of an unsupervised learning algorithm, the data is not explicitly labeled into different classes, that is, there are no labels. The model is able to learn from the data by finding implicit patterns.
Unsupervised Learning algorithms identify the data based on their densities, structures, similar segments, and other similar features. Unsupervised Learning Algorithms are based on Hebbian Learning.
Cluster analysis is one of the most widely used techniques in supervised learning.
Let us look at some of the important algorithms that come under Unsupervised Learning.
Clustering
Clustering, also known as cluster analysis, is a technique of grouping similar sets of objects in the same group that is different from the objects in other group.
Some of the essential clustering techniques are as follows –
a. K-means
The aim of the k-means clustering algorithm is to partition the n observations in the data into k clusters such that each observation belongs to the cluster with the nearest mean.
This serves as the prototype of the cluster.
b. DBSCAN
This is a clustering method that groups the data based on the density. It groups together the points that are given in the space and marks the outliers in the low-density region.
c. Hierarchical clustering
In this form of clustering, a hierarchy of clusters is built.
Anomaly Detection
Anomaly Detection techniques detect outliers in the unlabeled data under an assumption that most of the data examples are normal by observing the instances that fit the remainder of the data set.
Autoencoders
Autoencoders are a type of Neural Networks that are used in Unsupervised Learning for representation learning. They are used in denoising and dimensionality reduction.
Deep Belief Network
It is a generative graphical model which is also a class of neural network designed for unsupervised learning. It is different from the supervised type of neural networks in the sense that it probabilistically reconstructs its inputs to act as feature detectors.
Principal Component Analysis
It is a class of unsupervised learning paradigm which is used for reducing the dimensions of the data.
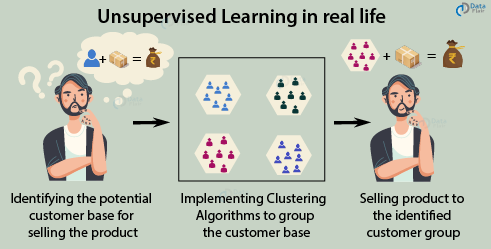
Unsupervised Learning Use Case
One of the most popular unsupervised learning techniques is clustering. Using clustering, businesses are able to capture potential customer segments for selling their products.
Sales companies are able to identify customer segments that are most likely to use their services. Companies can evaluate the customer segments and then decide to sell their product to maximize the profits.
One such company that is performing brand marketing analytics using Machine Learning is an Israeli based startup – Optimove. The goal of this company is to ingest and process the customer data in order to make it accessible to the marketers.
They take it one step further by providing smart insights to the marketing team, allowing them to reap the maximum profit out of their product marketing.
Reinforcement Learning

Reinforcement Learning covers more area of Artificial Intelligence which allows machines to interact with their dynamic environment in order to reach their goals. With this, machines and software agents are able to evaluate the ideal behavior in a specific context.
With the help of this reward feedback, agents are able to learn the behavior and improve it in the longer run. This simple feedback reward is known as a reinforcement signal.

The agent in the environment is required to take actions that are based on the current state. This type of learning is different from Supervised Learning in the sense that the training data in the former has output mapping provided such that the model is capable of learning the correct answer.
Whereas, in the case of reinforcement learning, there is no answer key provided to the agent when they have to perform a particular task. When there is no training dataset, it learns from its own experience.
Reinforcement Learning Use Case
Google’s Active Query Answering (AQA) system makes use of reinforcement learning.It reformulates the questions asked by the user.
For example, if you ask the AQA bot the question – “What is the birth date of Nikola Tesla” then the bot would reformulate it into different questions like “What is the birth year of Nikola Tesla”, “When was Tesla born?” and “When is Tesla’s birthday”.
This process of reformulation utilized the traditional sequence2sequence model, but Google has integrated reinforcement Learning into its system to better interact with the query based environment system.
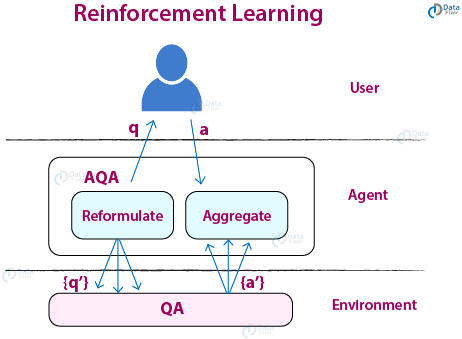
This is a deviation from the traditional seq2seq model such that all the tasks are carried out using reinforcement learning and policy gradient methods. That is, for a given question q0, we want to obtain the best possible answer a*.
The goal is to maximize the award a* = argmaxa R(ajq0).
Summary
Concluding the article, we took a look at the different types of machine learning paradigms. We went through supervised, unsupervised and reinforcement learning. We also discussed the several algorithms that are part of these three categories. Then, we went through the various real-life applications of these algorithms.
Did you know we work 24x7 to provide you best tutorials
Please encourage us - write a review on Google


Under which category does Apriori algorithm fall?
abc