Machine Learning Classification – 8 Algorithms for Data Science Aspirants
Machine Learning courses with 100+ Real-time projects Start Now!!
In this article, we will look at some of the important machine learning classification algorithms.
We will discuss the various algorithms based on how they can take the data, that is, classification algorithms that can take large input data and those algorithms that cannot take large input information.
Machine Learning Classification Algorithms
Classification is one of the most important aspects of supervised learning.
In this article, we will discuss the various classification algorithms like logistic regression, naive bayes, decision trees, random forests and many more. We will go through each of the algorithm’s classification properties and how they work.
1. Logistic Regression Algorithm
Logistic regression may be a supervised learning classification algorithm wont to predict the probability of a target variable. It’s one among the only ML algorithms which will be used for various classification problems like spam detection, Diabetes prediction, cancer detection etc.
Logistic regression is simpler to implement, interpret, and really efficient to coach.
If the amount of observations is lesser than the amount of features, Logistic Regression shouldn’t be used, otherwise, it’s going to cause overfitting.
We use logistic regression for the binary classification of data-points. We perform categorical classification such that an output belongs to either of the two classes (1 or 0).
For example – we can predict whether it will rain today or not, based on the current weather conditions.
Two of the important parts of logistic regression are Hypothesis and Sigmoid Curve. With the help of this hypothesis, we can derive the likelihood of the event.
The data generated from this hypothesis can fit into the log function that creates an S-shaped curve known as “sigmoid”. Using this log function, we can further predict the category of class.
We can represent the sigmoid as follows:
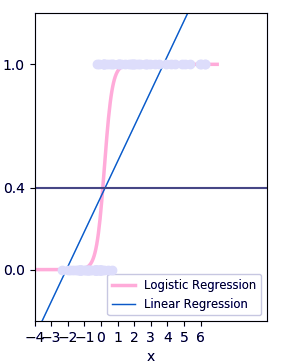
The produced graph is through this logistic function:
1 / (1 + e^-x)
The ‘e’ in the above equation represents the S-shaped curve that has values between 0 and 1.
We write the equation for logistic regression as follows:
y = e^(b0 + b1*x) / (1 + e^(b0 + b1*x))
In the above equation, b0 and b1 are the two coefficients of the input x.
We estimate these two coefficients using “maximum likelihood estimation”.
2. Naïve Bayes Algorithm
Naïve Bayes algorithm may be a supervised learning algorithm, which is predicated on Bayes theorem and used for solving classification problems. It’s not one algorithm but a family of algorithms where all of them share a standard principle, i.e. every pair of features being classified is independent of every other.
Naïve Bayes Classifier is one among the straightforward and best Classification algorithms which helps in building the fast machine learning models which will make quick predictions.
Naive Bayes is one of the powerful machine learning algorithms that is used for classification. It is an extension of the Bayes theorem wherein each feature assumes independence. It is used for a variety of tasks such as spam filtering and other areas of text classification.
Naive Bayes algorithm is useful for:
- It is an easy and quick way to predict the class of the dataset. Using this, one can perform a multi-class prediction.
- When the assumption of independence is valid, Naive Bayes is much more capable than the other algorithms like logistic regression.
- Furthermore, you will require less training data.
Naive Bayes however, suffers from the following drawbacks:
- If the categorical variable belongs to a category that wasn’t followed up in the training set, then the model will give it a probability of 0 which will inhibit it from making any prediction.
- Naive Bayes assumes independence between its features. In real life, it is difficult to gather data that involves completely independent features.
It still has some shortcomings though. If the categorical variable falls in any of the categories that the model was not trained on then it will assign this feature a probability of zero which will limit the ability of the model to make predictions . Furthermore, Naive Bayes work under the premise of features independence, which is rarely true in the real world datasets.
3. Decision Tree Algorithm
Decision Tree algorithms are used for both predictions as well as classification in machine learning.
Using the decision tree with a given set of inputs, one can map the various outcomes that are a result of the consequences or decisions.
We can understand decision trees with the following example:
Let us assume that you have to go to the market to buy some products. At first, you will assess if you really need the product.
Suppose, you will only buy shampoo if you run out of it. If you do not have the shampoo, you will evaluate the weather outside and see if it is raining or not. If it is not raining, you will go and otherwise, you will not.
We can visualize this in the form of a decision tree as follows:

This decision tree is a result of various hierarchical steps that will help you to reach certain decisions. In order to build this tree, there are two steps – Induction and Pruning. In induction, we build a tree whereas, in pruning, we remove the several complexities of the tree.
Decision Trees are very flexible because they work with continuous and nominal variables. They are also easy to depict graphically, which makes them valuable for analyzing the decision-making processes. However, they can be computationally very intensive and could easily over fit when used with large data sets. These concerns are trimmed by techniques such as pruning and other ensemble methods inclusive of Random Forest.
4. K-Nearest Neighbors Algorithm
K-nearest neighbors is one of the most basic yet important classification algorithms in machine learning.
KNNs belong to the supervised learning domain and have several applications in pattern recognition, data mining, and intrusion detection. These KNNs are used in real-life scenarios where non-parametric algorithms are required. These algorithms do not make any assumptions about how the data is distributed.
When we are given prior data, the KNN classifies the coordinates into groups that are identified by a specific attribute.
5. Support Vector Machine Algorithm
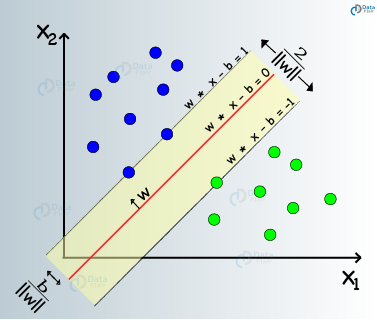
Support Vector Machines are a type of supervised machine learning algorithm that provides analysis of data for classification and regression analysis.
While they can be used for regression, SVM is mostly used for classification. We carry out plotting in the n-dimensional space. The value of each feature is also the value of the specified coordinate. Then, we find the ideal hyperplane that differentiates between the two classes.
These support vectors are the coordinate representations of individual observation. It is a frontier method for segregating the two classes.
6. Random Forest Algorithm
Random Forest classifiers are a type of ensemble learning method that is used for classification, regression and other tasks that can be performed with the help of the decision trees. These decision trees can be constructed at the training time and the output of the class can be either classification or regression.
With the help of these random forests, one can correct the habit of overfitting to the training set.
Some of the advantages and disadvantages of random forest classifiers are as follows:
Advantages – Random Forest Classifiers facilitate the reduction in the over-fitting of the model and these classifiers are more accurate than the decision trees in several cases.
Disadvantages – Random forests exhibit real-time prediction but that is slow in nature. They are also difficult to implement and have a complex algorithm.
7. Stochastic Gradient Descent Algorithm
Stochastic Gradient Descent (SGD) is a class of machine learning algorithms that is apt for large-scale learning. It is an efficient approach towards discriminative learning of linear classifiers under the convex loss function which is linear (SVM) and logistic regression.
We apply SGD to the large scale machine learning problems that are present in text classification and other areas of Natural Language Processing. It can efficiently scale to the problems that have more than 10^5 training examples provided with more than 10^5 features.
Following are the advantages of Stochastic Gradient Descent:
- These algorithms are efficient.
- We can implement these algorithms quite easily.
However, Stochastic Gradient Descent (SGD) suffers from the following disadvantages:
- The SGD algorithm requires a number of hyperparameters such has regularization and a number of iterations.
- It is also quite sensitive to feature scaling, which is one of the most important steps under data-preprocessing.
8. Kernel Approximation Algorithm
In this submodule, there are various functions that perform an approximation of the feature maps that correspond to certain kernels which are used as examples in the support vector machines. These feature functions perform a wide array of non-linear transformations of the input which serves as the basis of linear classifications or the other algorithms.
An advantage of using the approximate features that are also explicit in nature compared with the kernel trick is that the explicit mappings are better at online learning that can significantly reduce the cost of learning on very large datasets.
The standard kernelized SVMs cannot scale properly to the large datasets but with an approximate kernel map, one can utilize many efficient linear SVMs.
Summary
Classification in Machine Learning is used to sort data into categories. For example, a spam filter uses classification to decide if an email is spam or not. A model is trained on examples of emails marked as spam or not spam. Then, it learns to predict the label for new emails. This is called binary classification – two classes.
There is also multi-class classification, like recognizing if a picture has a cat, dog, or bird. The model is trained with different images and labels. When a new image is shown, it predicts the correct label. Common algorithms for classification include Logistic Regression, Decision Trees, Random Forest, and Naive Bayes.
Classification models are everywhere – in banking (fraud or no fraud), in healthcare (disease or no disease), and in social media (safe or harmful content). With clear training and good data, classification models can become highly accurate and save time for businesses.
The aim of this blog was to provide a clear picture of each of the classification algorithms in machine learning.
Did you know we work 24x7 to provide you best tutorials
Please encourage us - write a review on Google





Very brief and informative. Good job