20 Deep Learning Terminologies You Must Know
Machine Learning courses with 100+ Real-time projects Start Now!!
In this blog, we will understand commonly used neural network and Deep Learning Terminologies. As these are the most important and the basic to understand before complex learning neural network and Deep Learning Terminologies.
So, let’s start Deep Learning Terms.
Introduction to Deep Learning Terminologies
a. Recurrent Neuron
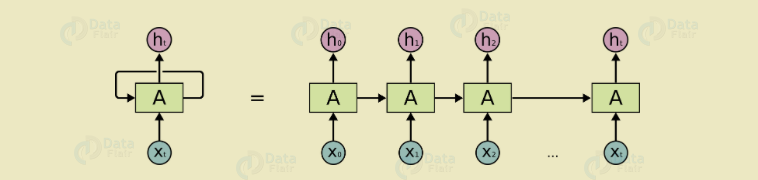
Deep Learning Terms – Recurrent Neuron
b. RNN (Recurrent Neural Network)
We use a recurrent neural network, especially for sequential data. As in this, we use the previous output to predict the next one. Also, in this case, loops have a network within them. In a hidden neuron, loops have the capability to store information. As it stores previous words to predict the output.
Again, we have to send an output of hidden layer for t timestamps. Moreover, you can see that unfolded neuron looks like. Once the neuron completes it all timestamps then it goes to the next layer. As a result, we can say that the output is more generalized. Although, the before fetched information is retained after a long time.
Moreover, to update the weight of the unfolded network, we have to propagate error once again. Hence, called backpropagation through time(BPTT).
c. Vanishing Gradient Problem
It’s one of the best from the Deep Learning Terminologies. Where the activation function is very small, this problem arises. At the time of backpropagation, we have to multiply weights with low gradients. Although, they are small and vanish if they go further deep in the network. As for this reason, the neural network forgets the long-range dependence. Also, it becomes a problem of neural networks. As a result, dependence is very important for the network to remember.
We use activation function to solve problems like ReLu which do not have small gradients.
d. Exploding Gradient Problem
We can say this is the opposite of the vanishing gradient problem. It is different as the activation function is too large. Also, it makes the weight of particular node very high. Although, we can solve it by clipping the gradient. So that it doesn’t exceed a certain value.
e. Pooling
It’s one of the best from the Deep Learning Terminologies. We can introduce pooling layers in between the convolution layers. Basically, use this to reduce the number of parameters. Although, prevent over-fitting. Although, the size of the most common type of pooling layer of filter size(2,2) using the MAX operation. Further, we can say what it would do is, it would take the maximum of each 4*4 matrix of the original image.
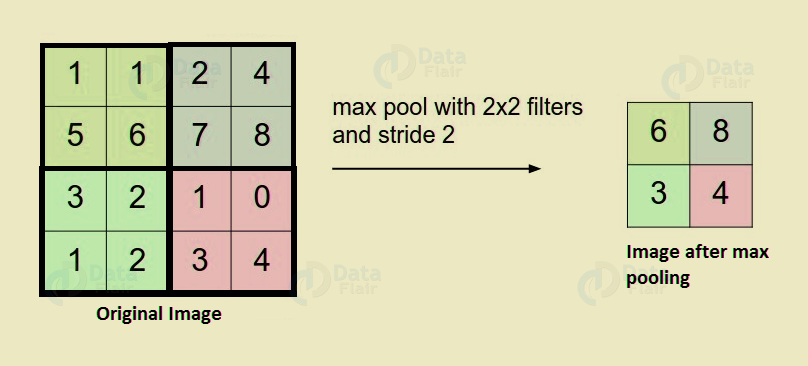
Deep Learning Terms – Pooling in Deep Learning
We can also use other applications of pooling such as average pooling etc.
f. Padding
In this process, we have to add an extra layer of zeros across the images. So, output image has the same size as the input. Hence, called as padding. If pixels of the image are actual or valid, we can say it’s a valid padding.
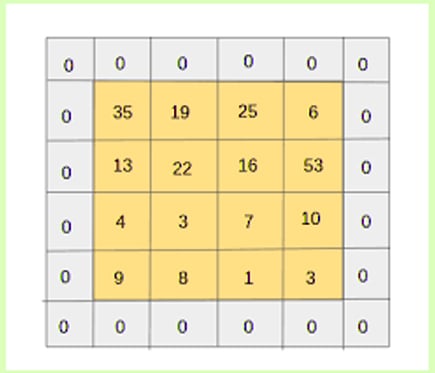
Deep Learning Terms – Padding
g. Data Augmentation
It refers to the addition of new data that come from the given data, which might prove to be beneficial for prediction.
For example:
Let us assume we have a digit “ 9 “. We can also change its recognition. But if it’s rotating or tilting. Thus, rotation help to increase the accuracy of our model. Although, we increase the quality of data by rotating. Hence, called for Data Augmentation.

Deep Learning Terms – Data Augmentation in Deep Learning
h. Softmax
We use softmax activation function in the output layer for classification problems. It’s like sigmoid function. Also, the difference is that outputs are normalized, to sum up to 1.
It is like the sigmoid function, with the only difference being that the outputs are normalized, to sum up to 1. The sigmoid function would work in case we have a binary output. But we also have a multiclass classification problem. In this process softmax makes it easy to assign values to each class. Also, that can be interpreted as probabilities.
It’s very easy to see it this way – Suppose you’re trying to identify a 6 which might also look a bit like 8. The function would assign values to each number as below. We can easily see that the highest probability is assigned to 6, with the next highest assigned to 8 and so on…
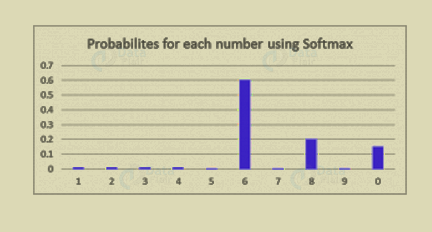
Deep Learning Terms – Softmax in Deep Learning
i. Neural Network
Neural Network form the backbone of deep learning. The goal of it is to find an approximation of an unknown function. It is made up of layers that learn from data. Neuron or node is a small unit in the network that takes input, does some calculation, and passes output to the next layer.
Also, have a bias that needs to be updated during the network training depending upon the error. The activation function puts a nonlinear transformation to the linear combination. Thus, generates the output. The combinations of the activated neurons give the output.
j. Input layer/ Output layer / Hidden layer
It’s one of the best from the Deep Learning Terminologies. The input layer is the one that receives the input. Also, it’s the first layer of the network. The output layer is the final layer of the network. These layers are the hidden layers of the network. We use these hidden layers to perform tasks on incoming data. Hence, pass generated output to the next layer. Although both layers are visible but the intermediate layers are hidden.
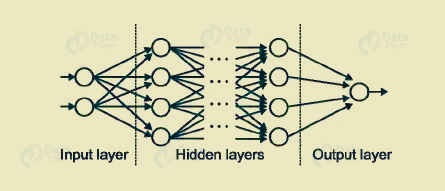
Input layer/ Output layer / Hidden layer in deep Learning
k. MLP (Multi-Layer perceptron)
We can not perform highly complex tasks with a single neuron. Therefore, we use stacks of neurons to generate the desired outputs. In the simplest network, we would have an input layer, a hidden layer, and an output layer. As in this, each layer has multiple neurons. Also, in each layer, all neurons are connected to all the neurons in the next layer. These networks are fully connected networks.
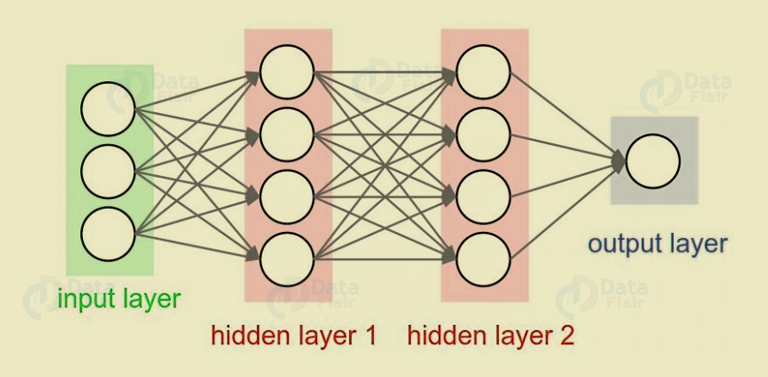
Deep Learning Terms – MLP (Multi-Layer perceptron) in Deep Learning
l. Neuron
As we can say that we use neuron to form the basic elements of a brain. Also, helps to form the basic structure of a neural network. As we get new information. We start to generate an output.
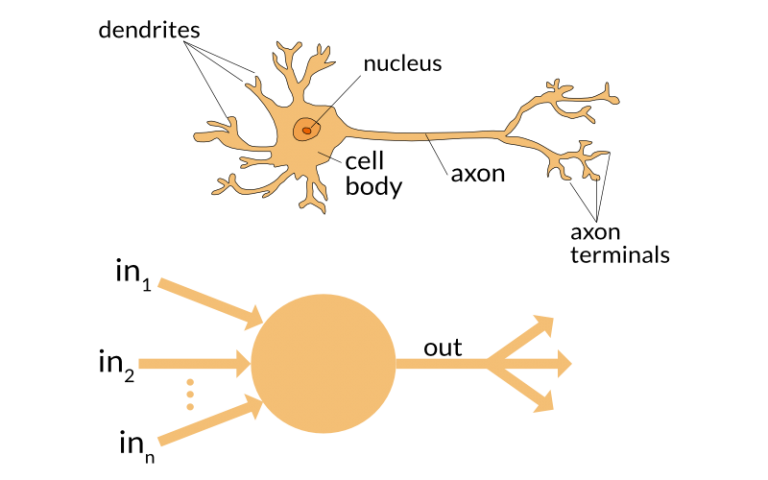
Deep Learning Terms – Neuron in Deep Learning
Similarly, we have to deal in case of a neural network. As soon as neuron will get the input, we have to start this process. Further, after processing generates an output. Also, we have to send neurons which helps in further processing. Either, we can consider it as the final output.
m. Weights
As soon as the input enters the neuron, we have to multiply it by a weight.
For example:
If in case a neuron has two inputs, then we have to assign each input an associated weight. Further, we have to initialize the weights randomly. Moreover, during the model training process, these weights are updating. Although, after training, we have to assign a higher weight to the input.
Let’s assume the input to be a, and then associate weight to be W1. Then after passing through the node the input becomes a*W1
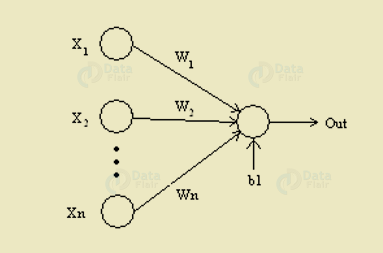
Deep Learning Terminologies – Weights
n. Bias
We have to add another linear component to input in addition to weight, this is a bias. In input, we have to add weight multiplication. Basically, we have to add bias to change the range of the weight multiplied input. As soon as bias is added result will look like a*W1+bias. Hence, it’s a linear component of the input transformation.
o. Activation Function
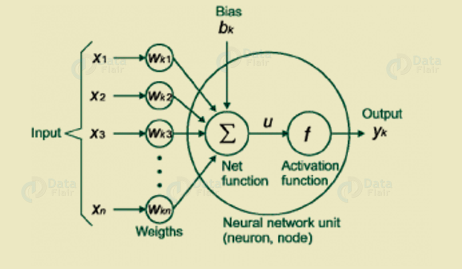
Deep Learning Terminologies – Activation Function
As soon as we apply linear component to the input, a non-linear function is applied to it. As this is done by applying the activation function to the linear combination. Hence, this translates the input signals to output signals.
The output after application of the activation function would look something like f(a*W1+b) where f() is the activation function.
In the below diagram we have “n” inputs given as X1 to Xn and corresponding weights Wk1 to Wkn. We have a bias given as bk. First, we have to multiply weights by its corresponding inputs. Then add these together along with the bias. Let assume as u.
u=∑w*x+b
Thus, activation function needs to apply on u i.e. f(u) and we receive the final output from the neuron as yk = f(u)
p. Gradient Descent
We use this as optimization algorithm for minimizing the cost.
Mathematically, to find the local minimum of a function one takes steps proportional to the negative of the gradient of the function.
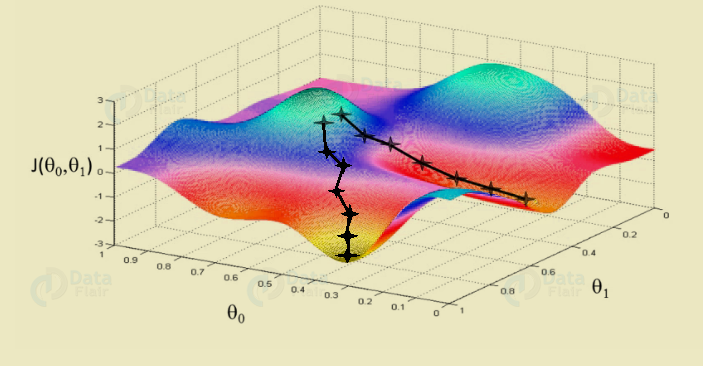
Deep Learning Terminologies – Gradient Descent
q. Learning Rate
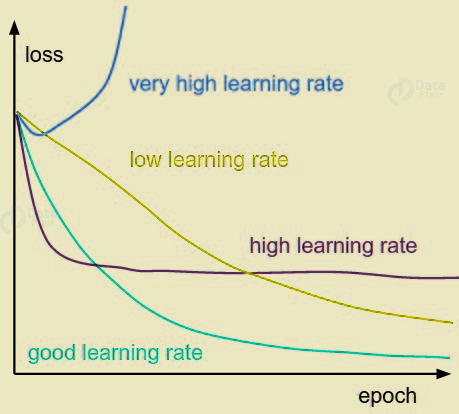
Deep Learning Terminologies – Learning Rate
We can say it is the amount of minimization in the cost function in each iteration. Also, one must be careful while choosing the learning rate. Since it should neither be very large that the optimal solution is missed. Also, not should be very low that it takes forever for the network to converge.
r. Backpropagation
Whenever we want to define a neural network, we assign random weights and bias values to our nodes. Also, as soon as we received the output for a single iteration. Thus, we can calculate the error of the network.
In back-propagation, the movement of the network is backward, the error along with the gradient flows back from the out layer through the hidden layers and updating of weights is done.
s. Batches
In case of training of neural network, we divide in input into several chunks of equal size random. Instead of sending the entire input in one go. Also, trained data batches make the model more generalized.
t. Epochs
We can define it as a single training iteration. Then we define in term with batches in forwarding and backpropagation. This means 1 epoch is a single forward and backward pass of the entire input data.
Deep Learning is still an active field of study and research; therefore, there are new terms continually emerging and new approaches developed. It is necessary for executives and implementers to be familiar with the terms and their implications for future deep learning development programs. However, when understood alongside the applications of these concepts, it will be easier for you to create more effective and optimal models.
So, this was all about Deep Learning Terms. Hope you like our explanation.
Conclusion
Your opinion matters
Please write your valuable feedback about DataFlair on Google




