Gaussian Mixture Model with Case Study – A Survival Guide for Beginners
Machine Learning courses with 100+ Real-time projects Start Now!!
If you are aware of the term clustering in machine learning, then it will be easier for you to understand the concept of the Gaussian Mixture Model. If you don’t know about clustering, then DataFlair is here to your rescue; we bring you a comprehensive guide for Clustering in Machine Learning. Coming back to the article, we will go through the definition of GMM, its requirement, implementation, and lastly, a case study for the Gaussian Mixture Model. We will understand how GMMs are an unconventional extension of clustering algorithm and why they are preferred over the others.
What is GMM?
In order to represent a normally distributed subpopulation within an overall population, we make use of the Gaussian Mixture Model. GMM does not require the data to which the subpopulation belongs. This allows the model to learn the subpopulations automatically. Since we do not know the assignment of the subpopulation, it comes under unsupervised learning.
For instance, suppose that you have to model the human height data. The mean heights of males in the normal distribution is 5’10” and 5’5” for females. Considering that we only know the height data and not the gender to which it belongs. In this case, the distribution of all heights follow the sum of two scaled and two shifted normal distributions. This assumption is made by the Gaussian Mixture Model.
There can, however, be more than two components in a GMM. Through the estimation of parameters contained within the individual normal distribution component is one of the primary problems encountered while modeling the data with GMM.
However, GMMs are not only used for modeling heights but also in other fields like finance for modeling stock return distribution, in speech recognition for modeling vocal tract configuration, and in image processing for image segmentation. One of the major strengths of the GMMs are that they can be flexible enough to capture different distribution in the data. This adaptability is especially important when working with the real-world data, as they frequently have multimodal distribution.
With the help of GMMs, one can extract the features from speech data, track the multiple objects in cases where there are a number of mixture components and the means that predict location of objects in a video sequence.
Wait! Have you checked the different types of Machine Learning Algorithms?
Why do we need Gaussian Mixture Models?
There are two most common areas of Machine Learning – Supervised Learning and Unsupervised Learning. We can easily distinguish between these two types based on the nature of data they use and the approaches that go towards solving the problems. In order to cluster the points based on similar characteristics, we make use of the clustering algorithms. Let’s assume that we have the following dataset –
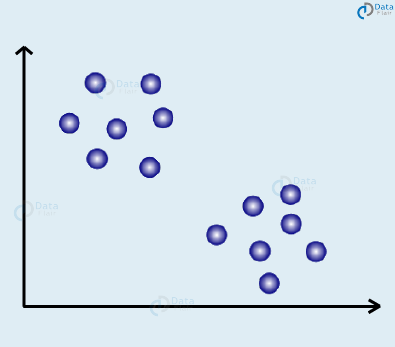
Our goal is to find the group of points that are close to each other. There are two different groups that we will color as blue and red.
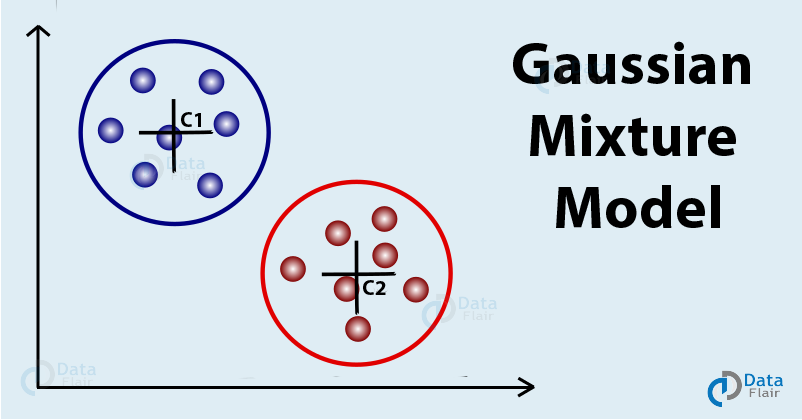
One of the most popular clustering techniques is the K-means clustering algorithm that follows an iterative approach to update parameters of each of the clusters. We compute the means of each cluster with which we then compute the means of each cluster and subsequent calculation of their distance to each data-points. The algorithm then labels these data points by identifying them by their closest centroid. The process is then repeated until achievement of some conversion criterion.
K-means is a hard clustering algorithm. According to this, each point gets associated to only one cluster. Because of this, there is an absence of probability that might tell you as to how many data points are associated with a particular cluster. As a result, we make use of the soft-clustering method. Gaussian Mixture Models are a perfect candidate for this.
Don’t miss these Top Machine Learning Projects to Ace Machine Learning Interviews
Many of the datasets can be easily modeled with the help of Gaussian Distribution. Therefore, one can assume that the clusters from different Gaussian Distributions. The core idea of model is that the data is modeled with several mixtures of Gaussian Distributions.
The single dimension probability density function of a Gaussian Distribution is as follows –
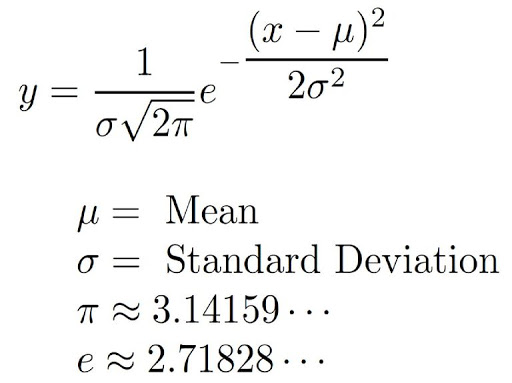
There are two types of values that parameterize the Gaussian Mixture Model – component weights and variances/covariances. A Gaussian Mixture Model with K components, μk is the mean of the kth component.
Furthermore, a univariate case will have a variance of σk whereas a multivariate case will have a covariance matrix of Σk. Φk is the definition of the mixture component weights which is for every component Ck. This has a constraint that ∑Ki=1ϕi=1 such that the total probability gets normalized to 1.
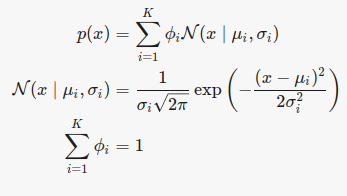
Implementing Gaussian Mixture Model
Let us begin this implementation by looking at the weak side of k-means clustering. We know that k-means finds the appropriate clustering results.
For example, if have some points of data as represented by the blobs in the visualization below, then the k-means algorithm can provide labels to those clusters which can be done something similarly as to what we understand through our eyes. For example, if we have simple blobs of data, the k-means algorithm can quickly label those clusters in a way that closely matches what we might do by eye:
Code:
%matplotlib inline import matplotlib.pyplot as plt import seaborn as sns; sns.set() import numpy as np from sklearn.cluster import KMeans from sklearn.datasets.samples_generator import make_blobs X, y = make_blobs(n_samples=400, centers=4, cluster_std=0.60, random_state=0) X = X[:, ::-1] # flipping the axes for obtaining a better plot
Screenshot:
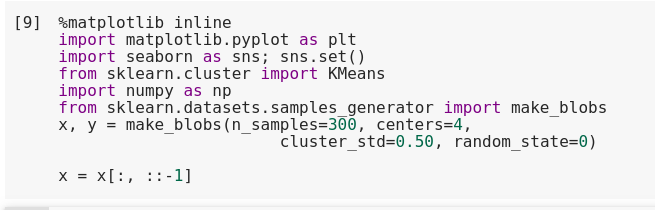
Code:
kmeans_model = KMeans(4, random_state=0) labels = kmeans_model.fit(X).predict(X) plt.scatter(X[:, 0], X[:, 1], c=labels, s=20, cmap='viridis');
Screenshot:

Output:
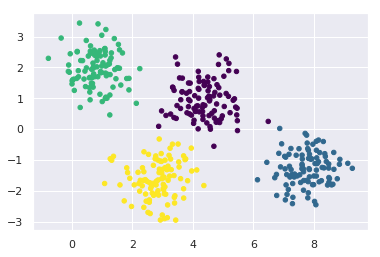
If you want to Get Hired soon then you need to master these Top Machine Learning Tools ASAP!!
Code:
from sklearn.mixture import GaussianMixture as gmm gmm_model = GMM(n_components=4).fit(X) labels = gmm_model.predict(X) plt.scatter(X[:, 0], X[:, 1], c=labels, s=20, cmap='viridis');
Screenshot:

Output:
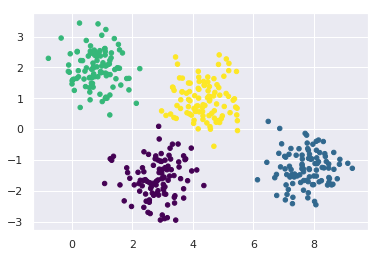
Code:
probs = gmm.predict_proba(X) print(probs[:5].round(3))
Output Screenshot:

Case Study of GMM – Segmentation of Homogeneous Bacterial Colonies
Recognition of images in digital images where homogeneous data was recurring, as was in the case of research conducted to cluster homogeneous bacterial colonies for their size estimation. For isolating the bacterial culture regions from the dish was achieved with image segmentation. This histogram was parameterized with the help of Gaussian Mixture Model using the Expectation Minimization.
With this algorithm, the researchers could obtain a good level of grey color distribution and were able to merge separate distributions of two different objects.
Don’t you feel you should know the real use of machine learning in daily life? Check this amazing Machine Learning Applications
Summary
A Gaussian Mixture Model (GMM) is used to model data as a mix of several Gaussian distributions. Each cluster is represented as a bell-shaped curve. GMMs are soft clustering methods, which means a point can belong to more than one cluster.
GMM is better than K-Means when clusters have different shapes and sizes. It uses probability to assign data points to clusters. The Expectation-Maximization algorithm helps find the best fit for the model.
GMMs are used in speech recognition, finance, and computer vision. They help in modeling real-world data where clusters are not clearly separated.
Hope you all enjoyed this tutorial. Share your thoughts and queries with us. DataFlair will surely help you.
We work very hard to provide you quality material
Could you take 15 seconds and share your happy experience on Google




