Introduction to Artificial Neural Network Model
Machine Learning courses with 100+ Real-time projects Start Now!!
In this Machine Learning tutorial, we will take you through the introduction of Artificial Neural network Model. First of all, we will discuss the multilayer Perceptron network next with the Radial Basis Function Network, they both are supervised learning model. At last, we will cover the Kohonen Model which follows Unsupervised learning and the difference between the Multilayer Perceptron network and Radial Basis Function Network.
Models of Artificial Neural Networks
There are various Artificial Neural Network Model. Main ones are
- Multilayer Perceptron – It is a feedforward artificial neural network model. It maps sets of input data onto a set of appropriate outputs.
- Radial Basis Function Network – A radial basis function network is an artificial neural network. It uses radial basis functions as activation functions.
Both of the above are being supervised learning networks used with 1 or more dependent variables at the output.
Let’s revise Machine Learning Tutorial
- The Kohonen Network – It is an unsupervised learning network used for clustering.
1. Multilayer Perceptron
As we saw above, A multilayer perceptron is a feedforward artificial neural network model. It maps sets of input data onto a set of appropriate outputs. In feed-forward neural networks, the movement is only possible in the forward direction.
An MLP consists of many layers of nodes in a directed graph, with each layer connected to the next one. Each neuron is a linear equation like linear regression as shown in the following equation
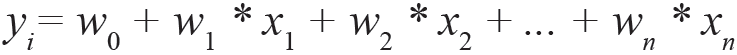
The equation is the transfer function in a neural network. This linear weight sum would be a threshold at some value so that output of neuron would be either 1 or 0.
The multilayer perceptron networks are suitable for the discovery of complex nonlinear models. On the possibility of approximating any regular function with a sum of sigmoid its power based.
MLP utilizes a supervised learning technique called backpropagation for training the network. This requires a known, desired output for each input value to calculate the loss function gradient.
MLP is a modification of the standard linear perceptron and can distinguish data that are not linearly separable.
Do you know about ANN Applications
2. Radial Basis Function Network
A Radial Basis Function (RBF) network is a supervised learning network like MLP which it resembles in some ways. But, RBF network works with only one hidden layer. It accomplishes this by calculating the value of each unit in the hidden layer for an observation. It uses the distance in space between this observation and the center of the unit. Instead of the sum of the weighted values of the units of the preceding level.
Unlike the weights of a multilayer perceptron. The centers of the hidden layer of an RBF network are not adjusted at each iteration during learning.
In RBF network, hidden neurons share the space and are virtually independent of each other. This makes for faster convergence of RBF networks in the learning phase, which is one of their strong points.
Let’s revise learning rules in Neural Network
Response surface of a unit of the hidden layer of an RBF network is a hypersphere. The response of the unit to an individual (xi) is a decreasing function G of the distance between the individual and its hypersphere.
As this function Γ generally a Gaussian function. The response surface of the unit, after the application of the transfer function, is a Gaussian surface. In other words, it is a ‘bell-shaped’ surface.
Learning of RBF involves determining the number of units in the hidden layer. Like a number of radial functions, their centers, radii, and coefficients.
3. The Kohonen Network
A self-organizing map (SOM) is a type of ANN that trained using unsupervised learning. It is also called as self-organizing feature map (SOFM). It produces a low-dimensional discretized representation of the input space of the training samples called a map.
Have a look at SVM in ML
The Finnish professor Teuvo Kohonen describes the model first as an ANN and it is sometimes called a Kohonen map or network.
The Kohonen network is the most common unsupervised learning network. It is also called self-adaptive or self-organizing network because of it ‘self-organizes’ input data.
Like any neural network, it is being made up of layers of units and connections between these units. The major difference from the rest of neural networks is that there is no variable that can predict.
The purpose of the network is to ‘learn’ the structure of the data so that it can distinguish clusters in them. By the following two levels the Kohonen network composed.
- Input layer with a unit for each of the n variables used in clustering
- Output layer – Its units are generally in a square or rectangular grid of l*m units. Each of these l*m units is connected to each of n units of the input layer.
The key related to Kohonen networks:
- For each individual, only one output unit (the ‘winner’) is activated – The Kohonen Net has a competitive layer of neurons. There is also an input layer. The input layer is fully connected to the competitive layer. The units in the competitive layer sum their weighted inputs to find a single winner.
- It adjusts the weight of the winner and its neighbors.
- The adjustment is such that two close placed output units correspond to two close placed individuals.
- At the output Groups (clusters) of units forms.
Do you know about Kernel Functions
In the application phase, Kohonen network operates by representing each input individual by the unit of the network. The network which is closest to it in terms of a distance defined above. This unit will be the cluster of the individual.
Comparison of MLP and RBF Networks
In neural networks, the approximating models relating inputs and outputs are “black box” models. They also provide very little insight into what these model do. Also, neural network users must make many modeling assumptions. For example, the number of hidden layers and the number of units in each hidden layer, and usually, there is little guidance on how to do this. Thus it takes the considerable experience to determine the most appropriate representation. Furthermore, back-propagation can be quite slow if the learning constant is not in the correct form.
MLPs and RBF networks are the two most common types of feedforward network. They have much more in common than most of the NN literature would suggest. The only difference is the way in which hidden units combine values coming from preceding layers in the network. MLPs use inner products, while RBFs use Euclidean distance. There are differences in the customary methods for training MLPs and RBF networks. We can also apply most methods for training MLPs to RBF networks.
An MLP has one or more hidden layers for which the combination function is the inner product of the inputs and weights, plus a bias. The activation function is usually a logistic or tanh function. MLP provides better generalization as it has the number of hidden units while RBF has less risk of non-optimal convergence. MLP is faster in model application mode while RBF is faster in model learning mode.
RBF networks usually have only one hidden layer. By which the combination function depends on the Euclidean distance between the input vector and the weight vector. RBF networks do not have anything that’s exactly the same as the bias term in an MLP. But some types of RBFs have a “width” associated with each hidden unit or with the entire hidden layer. Instead of adding it in the combination function like a bias, you divide the Euclidean distance by the width.
| Network | MLP | RBF | |
| Hidden layer(s) | Combination Function | Scalar product | Euclidean distance |
| Transfer Function | Logistic s(X)=1/(1+ exp(-X)) | Gaussian Γ(X)=exp(-X2/2σ2) | |
| Number of hidden layers | >=1 | =1 | |
| Output layer | Combination Function | Scalar product | Linear combination of Gaussians |
| Transfer Function | Logistic s(X)=1/(1 + exp(-X)) | Linear function f(X)=X | |
| Speed | Faster in ‘model application’ mode | Faster in ‘model learning’ mode | |
| Advantage | Better generalization | Less risk of non-optimal convergence |
Conclusion
An artificial neural network model is built by connecting multiple neurons in layers. The model takes input data, processes it through hidden layers, and gives an output. Each connection between neurons has a weight. The network changes these weights during training to improve accuracy.
To build a model, we need data, an algorithm (like backpropagation), and a loss function that shows how wrong the model is. The goal is to reduce this loss over time. Models can be simple (few layers) or deep (many layers). Deep models can learn complex patterns but need more data and time.
If in case you have any query in any Artificial Neural Network Model, so please share with us. We will be glad to solve them.
Did you know we work 24x7 to provide you best tutorials
Please encourage us - write a review on Google





Thanks very much for the useful information. May I have the link to get the model??