Audio Analysis Using Deep Learning – Application & Data Handling
Machine Learning courses with 100+ Real-time projects Start Now!!
In this Deep Learning Tutorial, we will study Audio Analysis using Deep Learning. Also, will learn data handling in the audio domain with applications of audio processing. As we will use graphs for a better understanding of audio data Analysis.
Introduction to Audio Analysis
As we are always in contact with audio. Sometimes directly or maybe indirectly. As our brain works continuously. Thus, brain process and understands the information. And at last, it provides us information about the environment.
Sometimes we catch this audio floating around us and feel something constructive. As there are some devices which help to catch these sounds. Also represents in computer readable format.
Examples of these formats are:
- wav (Waveform Audio File) format
- mp3 (MPEG-1 Audio Layer 3) format
- WMA (Windows Media Audio) format
Audio Analysis – Audio Format
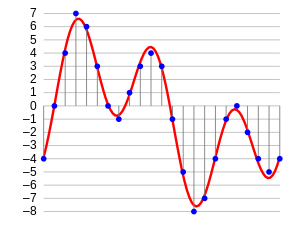
If we think more and more about audio, at last, there is one conclusion that it is a wave-like format of data. This can be pictorially represented as follows.
Let’s revise Transfer Learning for Deep Learning with CNN
Data Handling in Audio Domain
For unstructured data formats, there are a couple of preprocessing steps. We need to follow before we present it for audio analysis.
Firstly we have to load data into a machine-understandable format. For this, we simply take values after every specific time steps.
For example – In a 2-second audio file, we extract values at half a second. This is called a sampling of audio data, and the rate at which it is sampled is called the sampling rate.
Audio Analysis – Example
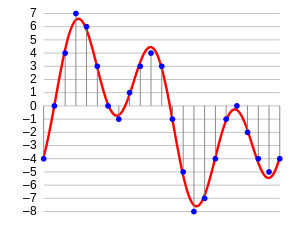
We can represent it in another way. As we can convert data into a different domain, namely frequency domain. When we sample an audio data, we require much more data points to represent the whole data. Also, the sampling rate should be as high as possible.
So, if we represent audio data in frequency domain. Then much less computational space is required. To get an intuition, take a look at the image below
Audio Analysis – Audio Features
Here, we have to separate one audio signal into 3 different pure signals, that can easily represent as three unique values in a frequency domain.
Also, there are present few more ways in which we can represent audio data and its audio analysis.
For example. using MFCs. These are nothing but different ways to represent the data.
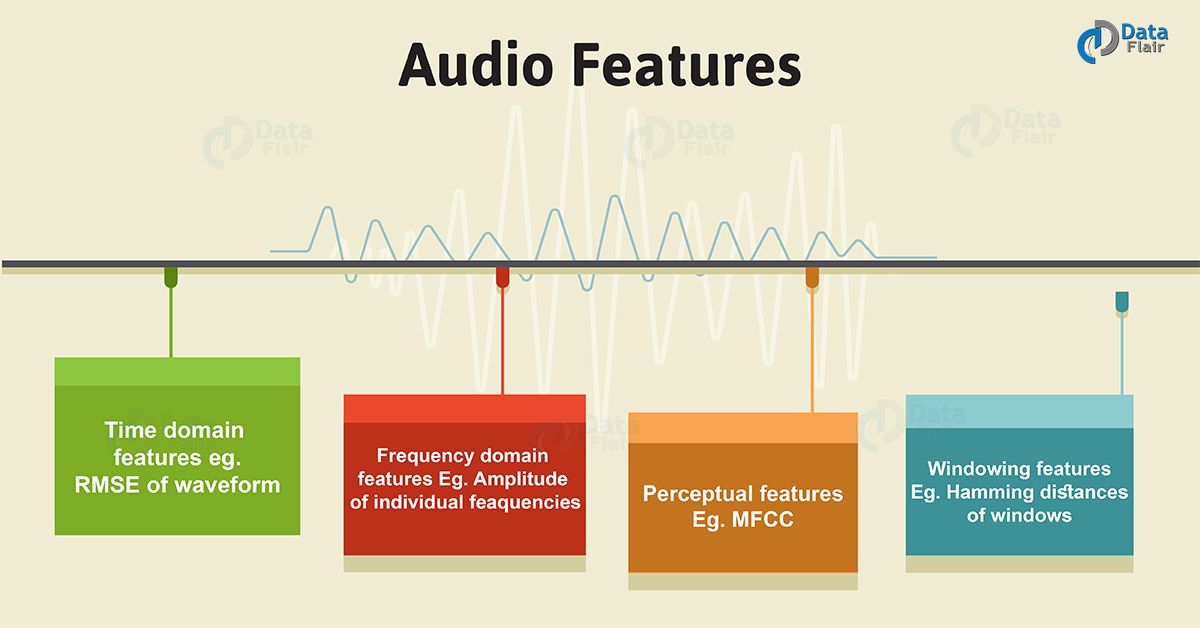
Further, we have to extract features from this audio representations. This algorithm works on these features and performs the task. Here’s a visual representation of the categories of audio features that can be extracted.
Another aspect of audio data shoulder is normalization where the possibility of the variety of audio samples volume is equalized. This is important for preserving the features of a given audio since amplitude variations can distort the features extracted from the audio. On the other hand, normalization helps enhance the optimum performance of machine learning models as it provides equal training and testing datasets.
One of the other key actions here is noise reduction. In real-life conditions, there is always extraneous noise thatspurs from the audio recording and affects the analysis. They include methods like spectral gating and band-pass filtering to help reduce this kind of noise. These preprocessing steps filter out unnecessary information from the audio and enable more accurate detection of the required features and characteristics, thus improving the quality of audio processing applications.
After extracting, we have to send this to the machine learning model for further analysis.
Applications of Audio Processing
- Indexing music collections according to their audio features.
- Recommending music for radio channels
- Similarity search for audio files (aka Shazam)
- Speech processing and synthesis – generating artificial voice for conversational agents
Let’s discuss Machine Learning Vs Deep Learning
Conclusion
Audio analysis is the process of teaching machines to understand sounds. With deep learning, this becomes possible by converting sound into numbers and feeding them into neural networks. Audio is first recorded in the form of waveforms, which are signals that show how sound changes over time. These waveforms are usually converted into spectrograms—visual pictures of sound that show frequency and time.
Deep learning models, especially Convolutional Neural Networks (CNNs), can read these spectrograms like images and learn to recognize different sounds such as speech, music, noise, or even animal voices.
Hope you liked the tutorial.
Your opinion matters
Please write your valuable feedback about DataFlair on Google




