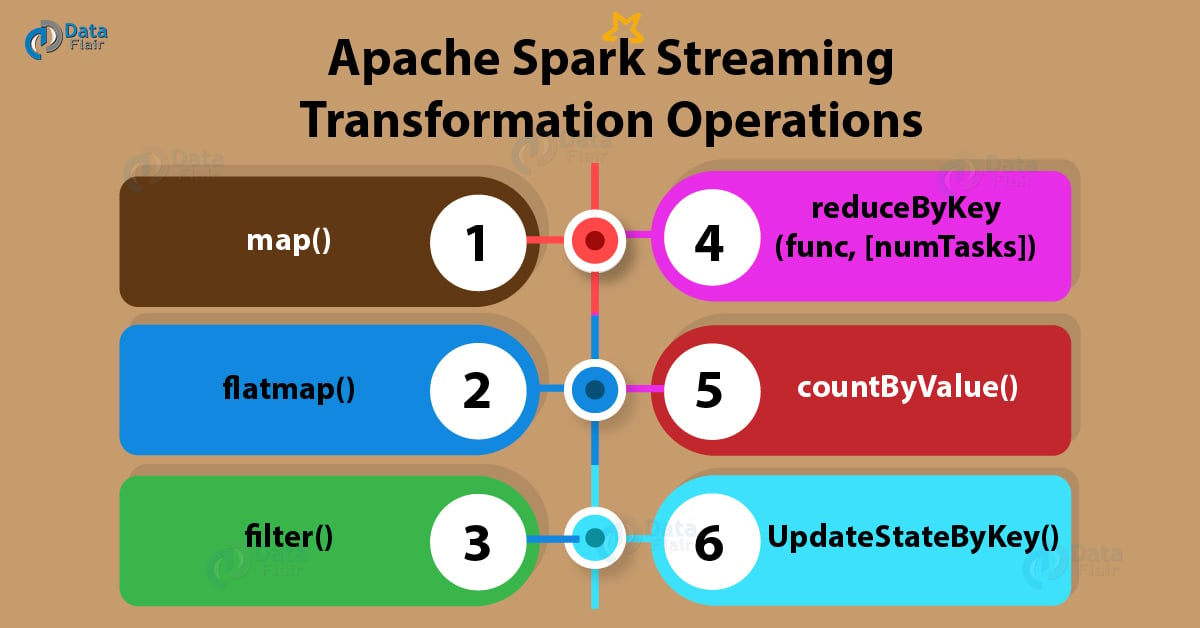
Apache Spark Streaming Transformation Operations
1. Objective
Through this Apache Spark Transformation Operations tutorial, you will learn about various Apache Spark streaming transformation operations with example being used by Spark professionals for playing with Apache Spark Streaming concepts. You will learn the Streaming operations like Spark Map operation, flatmap operation, Spark filter operation, count operation, Spark ReduceByKey operation, Spark CountByValue operation with example and Spark UpdateStateByKey operation with example that will help you in your Spark jobs.
Apache Spark Streaming Transformation Operations
2. Introduction to Apache Spark Streaming Transformation Operations
Before we start learning the various Streaming operations in Spark, let us revise Spark Streaming concepts.
Below are the various most common Streaming transformation functions being used in Spark industry:
a. map()
Map function in Spark passes each element of the source DStream through a function and returns a new DStream.
Spark map() example
[php]val conf = new SparkConf().setMaster(“local[2]”) .setAppName(“MapOpTest”)
val ssc = new StreamingContext(conf , Seconds(1))
val words = ssc.socketTextStream(“localhost”, 9999)
val ans = words.map { word => (“hello” ,word ) } // map hello with each line
ans.print()
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for termination
}[/php]
b. flatMap()
FlatMap function in Spark is similar to Spark map function, but in flatmap, input item can be mapped to 0 or more output items. This creates difference between map and flatmap operations in spark.
Spark FlatMap Example
[php]val lines = ssc.socketTextStream(“localhost”, 9999)
val words = lines.flatMap(_.split(” “)) // for each line it split the words by space
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()[/php]
c. filter()
Filter function in Apache Spark returns selects only those records of the source DStream on which func returns true and returns a new DStream of those records.
Spark Filter function example
[php]val lines = ssc.socketTextStream(“localhost”, 9999)
val words = lines.flatMap(_.split(” “))
val output = words.filter { word => word.startsWith(“s”) } // filter the words starts with letter“s”
output.print()[/php]
Apache Spark Streaming Transformation Operations
d. reduceByKey(func, [numTasks])
When called on a DStream of (K, V) pairs, ReduceByKey function in Spark returns a new DStream of (K, V) pairs where the values for each key are aggregated using the given reduce function.
Spark reduceByKey example
[php]val lines = ssc.socketTextStream(“localhost”, 9999)
val words = lines.flatMap(_.split(” “))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()[/php]
e. countByValue()
CountByValue function in Spark is called on a DStream of elements of type K and it returns a new DStream of (K, Long) pairs where the value of each key is its frequency in each Spark RDD of the source DStream.
Spark CountByValue function example
[php]val line = ssc.socketTextStream(“localhost”, 9999)
val words = line.flatMap(_.split(” “))
words.countByValue().print()[/php]
f. UpdateStateByKey()
The updateStateByKey operation allows you to maintain arbitrary state while continuously updating it with new information. To use this, you will have to do two steps.
Define the state – The state can be an arbitrary data type.
Define the state update function – Specify with a function how to update the state using the previous state and the new values from an input stream.
In every batch, Spark will apply the state update function for all existing keys, regardless of whether they have new data in a batch or not. If the update function returns None then the key-value pair will be eliminated.
Spark UpdateByKey Example
[php]def updateFunc(values: Seq[Int], state: Option[Int]): Option[Int] = {
val currentCount = values.sum
val previousCount = state.getOrElse(0)
Some(currentCount + previousCount)
}
val ssc = new StreamingContext(conf , Seconds(10))
val line = ssc.socketTextStream(“localhost”, 9999)
ssc.checkpoint(“/home/asus/checkpoints/”) // Here ./checkpoints/ are the directory where all checkpoints are stored.
val words = line.flatMap(_.split(” “))
val pairs = words.map(word => (word, 1))
val globalCountStream = pairs.updateStateByKey(updateFunc)
globalCountStream.print()
ssc.start() // Start the computation
ssc.awaitTermination()[/php]
For more Spark operations and examples, you can refer Best books to master Apache Spark.
Source:
http://spark.apache.org/docs/latest/programming-guide.html
Did you like this article? If Yes, please give DataFlair 5 Stars on Google




