YouTube Recommendation System – Machine Learning Project with Source Code
Machine Learning courses with 100+ Real-time projects Start Now!!
Every major e-commerce or entertainment website recommends products to you based on various factors. Like how youtube, netflix recommends movies and shows to you or how amazon shows you products that it thinks you might be interested in. These are all based on some kind of recommendation system.
Based on your past history and how you have interacted with the service or how similar people have interacted with the service they try to make the experience more personalized and targeted towards you. This provides a smoother and better experience and also saves the customer a lot of time and energy while increasing the conversion rate for the company.

A recommendation system is an algorithm that can be used to suggest the user some relevant content. A recommendation system has become such an important part of consuming content online that we cannot imagine a life without it. On youtube alone, 720,000 hours of content are uploaded every day.
Amazon has a catalog of over 12 million products on its websites. With so many options how can one search and decide what to watch or what to buy? This ever-growing list of options if presented raw in front of the user will confuse and frustrate them eventually leading to a bad experience of the service.
How do youtube recommendation systems work?
There are a whole lot of ways we can think of recommending stuff to the user but there are just two prominent methods that are followed industry-wide and have proven to work for most of the tasks. That’s what we are gonna see today.
1. Content-based recommendation system
It is a very simple concept, in which the service suggests you on the basis of what you are iterating with. Like if you are watching videos on a particular topic, youtube would recommend you videos on similar or same topics.
The system internally has a set of different features and a score related to that for all items. Now the system checks from the scores of the content or item you are interacting with and based on that it compares with feature scores of different items and the closest it finds it suggests. These kinds of models also rank feature scores based on the user details like their age, sex or location, and other personal information.
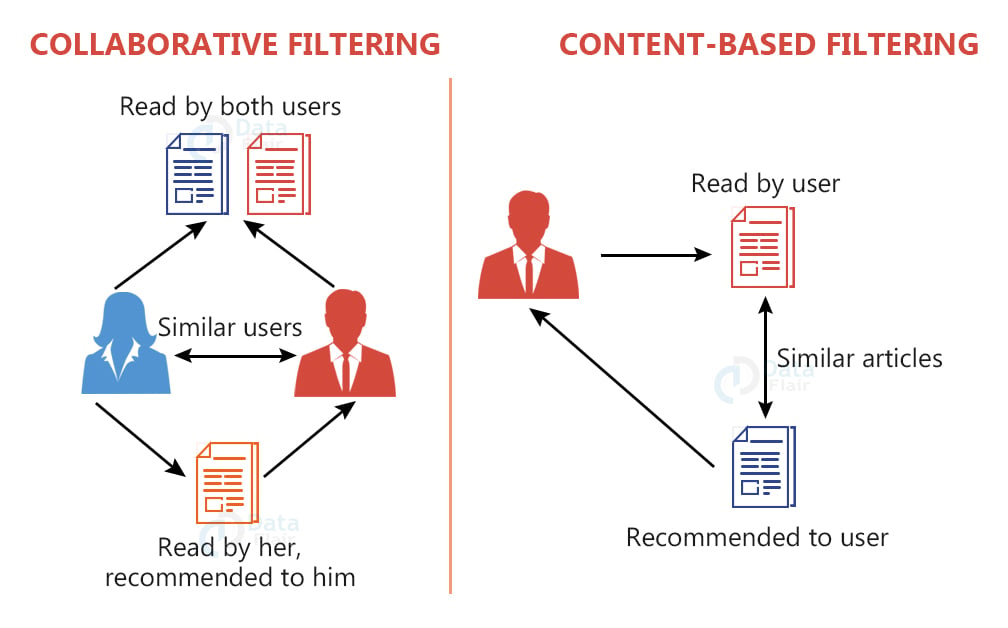
2. Collaborative filtering method
This works by recommending items that similar users have liked, therefore it groups similar users together and shares their interests within their group. This is not limited to a particular item but also what kind of item it was and what properties it holds. It can also be bidirectional in nature, for example, it recommends content that similar users have liked.
Also when a user likes some content, it helps in grouping them with similar users, thereby improving everyone’s suggestions. It is based on a simple assumption that if person A has similar taste for most things as person B, his taste will match user B’s in future interactions as well.
We are going to use collaborative filtering methods for building our own youtube video recommendation system. There are still two methods of implementing collaborative filtering:
1. Memory based
In this, past histories of customers are plotted in a matrix. It uses statistical methods to group together members with similar user-item interaction matrices, and recommend products based on that. Simply said the algorithm tries to match similar profiles and based on this it recommends stuff to the user.
2. Model based
In this method, we try to reduce to the user-item interaction matrix. As the number of users and the number of products grow, having such a large dataset and using statistical methods for calculating relevance turns out to be an intensive task. So we try different methods of dimensionality reduction and matrix factorization with traditional machine learning algorithms or with some new deep learning algorithm, the one we are going to use today.
For this task we are going to use a deep learning method for building the recommendation system.
Understanding Youtube Video Recommendation System
Researchers from Google released this paper demonstrating how deep learning can be used for such a task efficiently. Although the real recommendation system is probably a hybrid one combining properties of content based, collaborative filtering and popularity matrix methods for recommending in production.
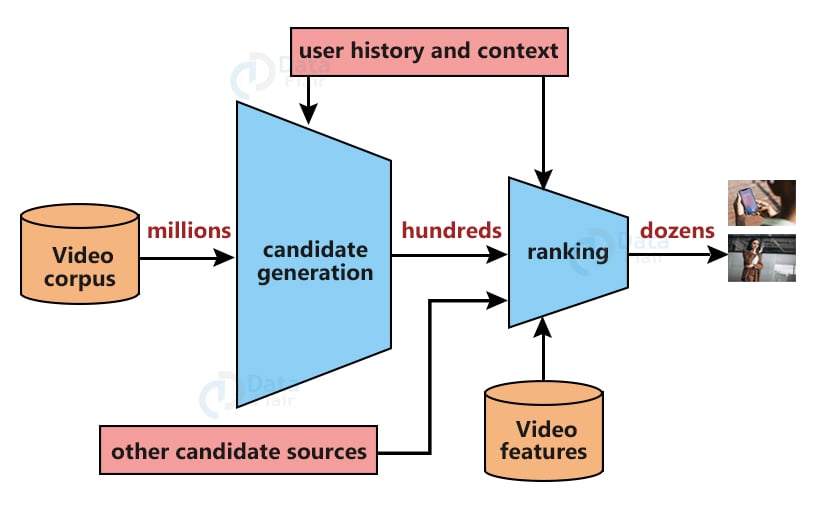
The way this paper treats the problem of recommending stuff is extreme multi class classification, where the model outputs or classifies which video is suitable for watching with context to an input user. The main problem is the extremely huge corpus of videos that youtube has, so the idea of this paper is to pass the data into two networks, reducing the number of videos at every stage. The model consists of two network each with their specific tasks
1. Candidate generator network
This network shrinks down the large corpus of videos, possibly billions of videos to some hundreds of videos. It takes in the huge number of videos as well as user log history as input. Then based on several factors such as search query, user history, demographic details and other user information it narrows down the list of relatable video to that user from billions down to hundreds. The authors of the paper tell us that this model aims for accuracy and relevance and may remove videos with higher views, but may not be relevant.
2. Ranking network
Based on the output of a list of hundreds of videos it gets from the first network and other features like user engagement behaviours like watch time, clicks, likes, dislikes. It also takes in consideration factors like user information, video information, and then scores each video according to the possibility it may be liked by the user. After taking all of this into consideration it ranks the videos and then selects top n videos according to the requirements. All this seems easy but taking into context all the features it has to deal with, it gets complicated pretty quick.
Download YouTube Recommendation System Project Code
Please download the source code of youtube recommendation system with machine learning: Recommendation System Project Code
Building the YouTube Recommendation system
1. The dataset:
We have used the movie lens dataset for this problem, because youtube does not have any public dataset that has user details along with watch history. So we do not have any solid data to work with, but the movie lens dataset is the closest we can get to a large video dataset along with user preference. It has reviews for 100,000 movies from 1000 users on a total of 1700 movies. It also has metadata and user information attached to it so this is probably the closest we can get with representation of actual youtube data using a public dataset.
2. Getting things ready
We are going to build this on colab, but if you are following this on your local system, the steps will be pretty much the same.
Download the dataset for Youtube Video Recommendation System from the grouplens website and place it in the working folder, unzipped.
We will use pytorch for training the model. We will begin by mounting our google drive to colab.
import os
from google.colab import drive
drive.mount('/content/drive')
os.chdir('/content/drive/My Drive/recommendation system')
This will mount the drive and move to the folder where we have our dataset. Then we will import some necessary libraries. We’ll also set the device to cuda if available.
%matplotlib inline
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import random
from tqdm import tqdm_notebook
from copy import deepcopy
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader, Dataset
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_path = 'ml-100k/'
In the movie lens dataset there are 5 dataset pairs available to use. Each pair has sets of training and validation. We use pandas to read the data from the dataset that we downloaded, and create different dataframes out of it. Our train dataframe will have four columns namely user_id, item_id, rating, and ts. Same for the validation dataframe, we’ll read it and format it. You’ll notice we are subtracting 1 from each df that is because we want it to start from 0, while in the dataset the start index is one. Printing the dataset size should ideally give us ((80000, 4), (20000, 4))
id_val = 1
num_users = 943
num_items = 1682
train_dataframe = pd.read_csv(f'{data_path}u{id_val}.base',sep='\t',header=None)
train_dataframe.columns = ['user_id','item_id','rating','ts']
train_dataframe['user_id'] = train_dataframe['user_id'] -1 train_dataframe['item_id'] = train_dataframe['item_id'] -1
valid_df = pd.read_csv(f'{data_path}u{id_val}.test',sep='\t',header=None)
valid_df.columns = ['user_id','item_id','rating','ts']
valid_df['user_id'] = valid_df['user_id'] -1
valid_df['item_id'] = valid_df['item_id'] -1
train_dataframe.shape, valid_df.shape
We find out the total number of users in our training dataset and validation dataset using unique and getting the length afterwards. We do the same with items as well.
train_usrs = train_dataframe.user_id.unique() vald_usrs = valid_df.user_id.unique() len(train_usrs),len(vald_usrs) train_itms = train_dataframe.item_id.unique() vald_itms = valid_df.item_id.unique() len(train_itms),len(vald_itms)
Then we will create a dataloader class in pytorch to create batches of the training and validation sets. It will return tuples of (user, item, rating). We set the batch size to 2000 and use dataloader on train and validation dataset.
class CollabDataset(Dataset):
def __init__(self, df, user_col=0, item_col=1, rating_col=2):
self.df = df
self.user_tensor = torch.tensor(self.df.iloc[:,user_col], dtype=torch.long, device = device)
self.item_tensor = torch.tensor(self.df.iloc[:,item_col], dtype=torch.long, device = device)
self.target_tensor = torch.tensor(self.df.iloc[:,rating_col], dtype=torch.float32, device = device)
def __getitem__(self, index):
return(self.user_tensor[index], self.item_tensor[index], self.target_tensor[index])
def __len__(self):
return(self.user_tensor.shape[0])
batch_size = 2000
train_dataset = CollabDataset(train_dataframe)
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
valid_dataset = CollabDataset(valid_df)
valid_dataloader = DataLoader(valid_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
3. Training the recommendation model
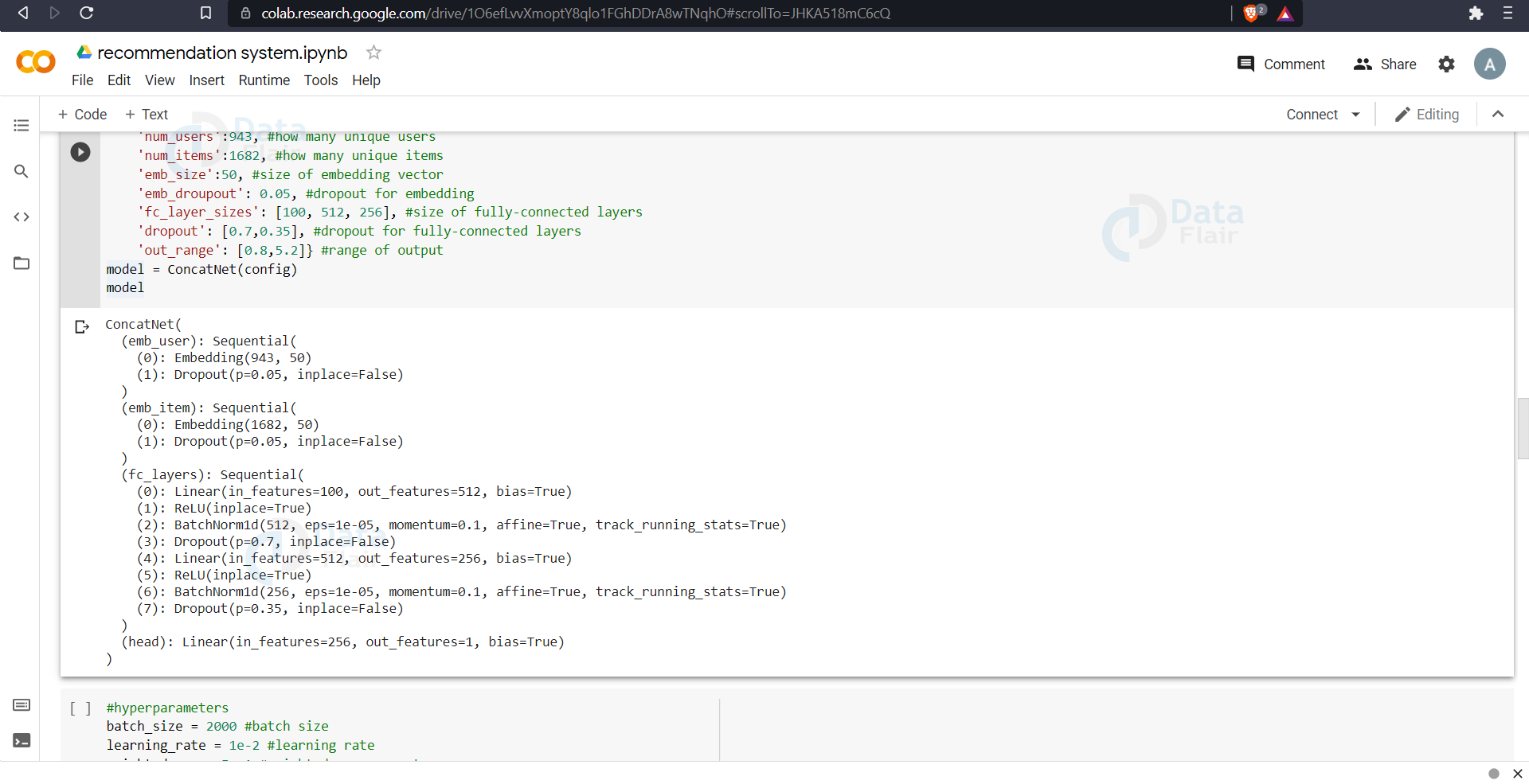
The model contains two kinds of layers, first embedding layer to map user and item indices to embedding vectors. And then fully connected layers to input those embeddings and output ratings. Here we define the model completely with all its layers. We pass the parameters in the form of config to the model class, three fully connected layers with 100, 256, 512 nodes respectively.
class ConcatNet(nn.Module):
def __init__(self, config):
super(ConcatNet, self).__init__()
#hyperparameters
self.config = config
self.num_users = config['num_users']
self.num_items = config['num_items']
self.emb_size = config['emb_size']
self.emb_droupout = config['emb_droupout']
self.fc_layer_sizes = config['fc_layer_sizes']
self.dropout = config['dropout']
self.out_range = config['out_range']
#embeddings
self.emb_user = nn.Sequential(
nn.Embedding(num_embeddings=self.num_users, embedding_dim=self.emb_size),
nn.Dropout(p=self.emb_droupout))
self.emb_item = nn.Sequential(
nn.Embedding(num_embeddings=self.num_items, embedding_dim=self.emb_size),
nn.Dropout(p=self.emb_droupout))
#fully-connected layers
fc_layers_list = []
for ni,nf,p in zip(self.fc_layer_sizes[:-1], self.fc_layer_sizes[1:], self.dropout):
fc_layers_list.append(nn.Linear(ni, nf))
fc_layers_list.append(nn.ReLU(inplace=True))
fc_layers_list.append(nn.BatchNorm1d(nf))
fc_layers_list.append(nn.Dropout(p=p))
self.fc_layers = nn.Sequential(*fc_layers_list)
#output head
self.head = torch.nn.Linear(in_features=self.fc_layer_sizes[-1], out_features=1)
def forward(self, user_idx, item_idx):
user_emb = self.emb_user(user_idx)
item_emb = self.emb_item(item_idx)
x = torch.cat([user_emb, item_emb], dim=1)
x = self.fc_layers(x)
x = torch.sigmoid(self.head(x))
x = x * (self.out_range[1] - self.out_range[0]) + self.out_range[0]
return(x)
config = {
'num_users':943,
'num_items':1682,
'emb_size':50,
'emb_droupout': 0.05,
'fc_layer_sizes': [100, 512, 256],
'dropout': [0.7,0.35],
'out_range': [0.8,5.2]}
model = ConcatNet(config)
model
Here we declare some hyperparameters for the model. The batch size is set to 2000, learning rate, weight decay and others are set. Empty lists are created to store losses. We then prepare data loaders for the train and test set. We use mse or mean squared error as the criterion, and adam optimizer for fast convergence.
batch_size = 2000
learning_rate = 1e-2
weight_decay = 5e-1
num_epoch = 100
reduce_learning_rate = 1
early_stoping = 5
learning_rates = []
train_losses=[]
valid_losses = []
best_loss = np.inf
best_weights = None
train_dataset = CollabDataset(train_dataframe)
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
valid_dataset = CollabDataset(valid_df)
valid_dataloader = DataLoader(valid_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
model = ConcatNet(config)
criterion = nn.MSELoss(reduction='sum')
optim = torch.optim.Adam(model.parameters(), learning_rate=learning_rate, betas=(0.9,0.999), weight_decay=weight_decay)
scheduler = torch.optim.learning_rate_scheduler.Reducelearning_rateOnPlateau(optim, mode='min',factor=0.5, threshold=1e-3,
patience=reduce_learning_rate, min_learning_rate=learning_rate/10)
Now the actual training begins, we use tqdm to create a progress bar. We load the data, pass it through the model, calculate the loss and then backward propagate the loss, change the learning rate and append the losses to the empty lists we created earlier.
Same for the validation, we get the validation data, pass it through the model to calculate the loss but this time we do not backward propagate the losses. And all of the validation is done in model.eval() putting the model in the evaluation phase.
We calculate the validation loss and based on that we save the best model ie: the one with the lowest validation loss. We also implement early stopping and stop the model training without running all the epochs if we see the loss becomes stable or is not decreasing. This saves us from overfitting and also wasting time.
for e in tqdm_notebook(range(num_epoch)):
model.train()
train_loss = 0
for u,i,r in train_dataloader:
r_pred = model(u,i)
r = r[:,None]
loss = criterion(r_pred,r)
optim.zero_grad()
loss.backward()
optim.step()
train_loss+= loss.detach().item()
current_learning_rate = scheduler.optimizer.param_groudropout[0]['learning_rate']
learning_rates.append(current_learning_rate)
train_loss /= len(train_dataset)
train_losses.append(train_loss)
model.eval()
valid_loss = 0
for u,i,r in valid_dataloader:
r_pred = model(u,i)
r = r[:,None]
loss = criterion(r_pred,r)
valid_loss+=loss.detach().item()
valid_loss/=len(valid_dataset)
#record
valid_losses.append(valid_loss)
print(f'Epoch {e} Train loss: {train_loss}; Valid loss: {valid_loss}; Learning rate: {current_learning_rate}')
if valid_loss < best_loss:
best_loss = valid_loss
best_weights = deepcopy(model.state_dict())
no_improvements = 0
else:
no_improvements += 1
if no_improvements >= early_stoping:
print(f'early stopping after epoch {e}')
break
scheduler.step(valid_loss)
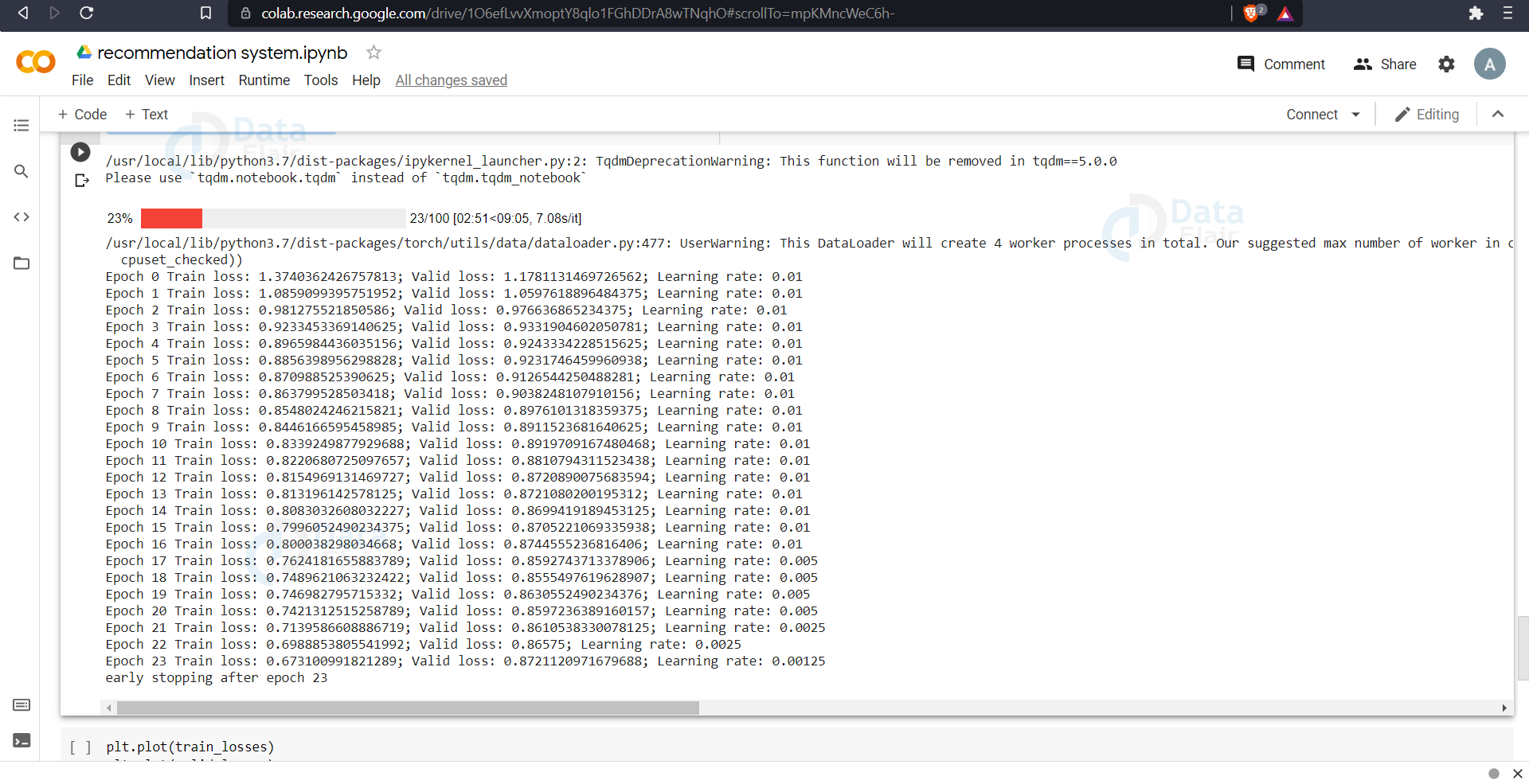
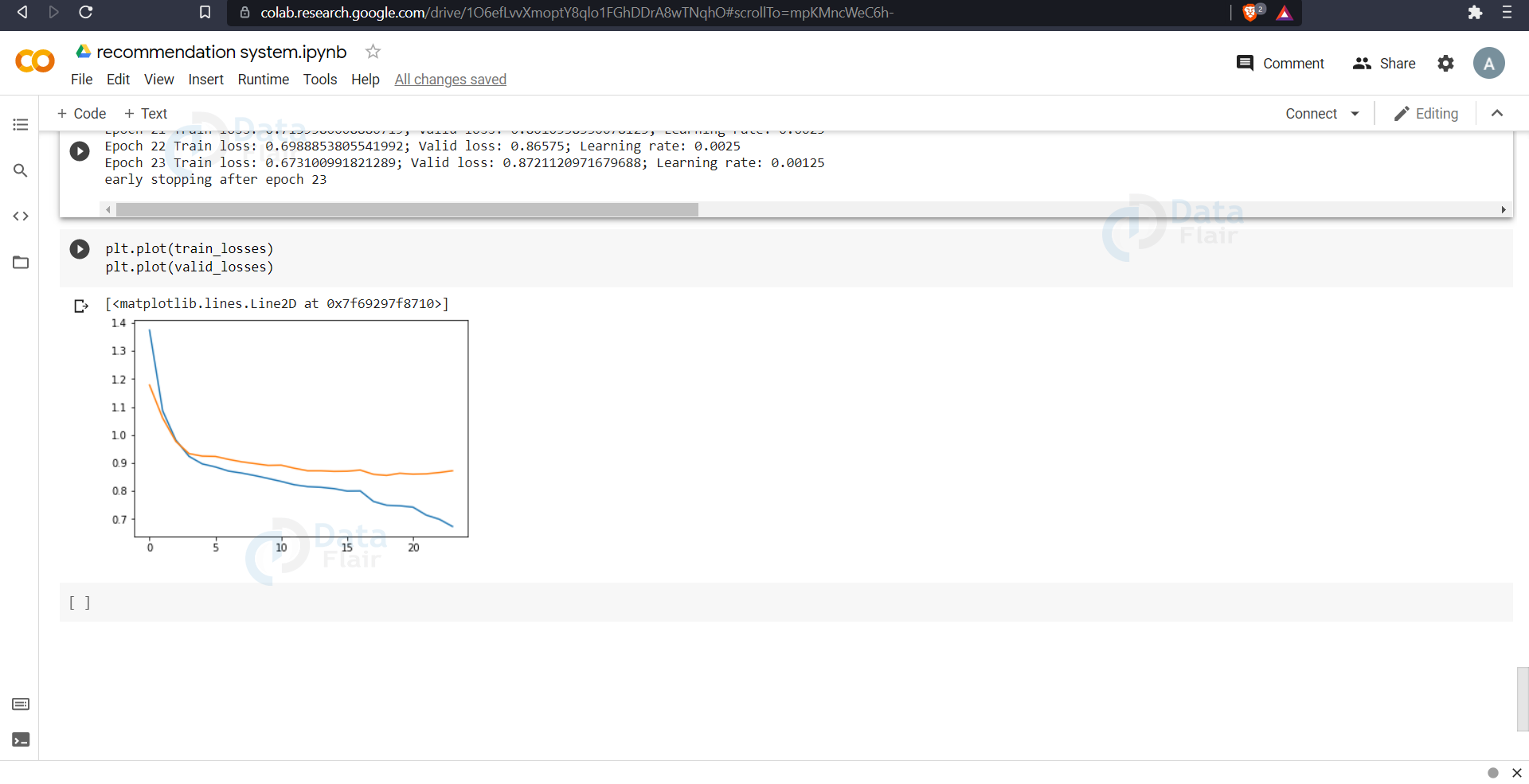
We can see here that we wanted the model to train for 100 epochs but the loss became stable after 23 epochs. So we stopped the training at that point and saved the model.
Now we plot the model training curve to see how the loss decreased and how the validation and training loss differs.
plt.plot(train_losses) plt.plot(valid_losses)
Summary
We have successfully created youtube video recommendation system using a deep learning model. Many companies have now shifted from traditional recommendation systems to deep learning based methods. This is because of its efficiency and ability to handle such a large amount of data, in a time limited scenario.
We have followed the architecture and reasonings of the paper Deep Neural Network for youtube video recommendation system. And now we know how it works and how to build one.
This project teaches how platforms like Netflix, Spotify, or Amazon recommend items. You will learn about data sparsity, cold start problems, and how to evaluate recommender systems using precision at K or Mean Average Precision. A video recommendation system is highly useful in real-world applications, and adding this project to your portfolio shows your strength in handling user data and personalizing experiences with machine learning.
Did you like our efforts? If Yes, please give DataFlair 5 Stars on Google





not bad
ok