Iris Flower Classification Project using Machine Learning
Machine Learning courses with 100+ Real-time projects Start Now!!
Machine learning is almost everywhere nowadays. It’s become more and more necessary day by day. From the recommendation of what to buy to recognizing a person, robotics, everywhere is machine learning. So in this project, we’ll create the “Hello World” of machine learning which means Iris flower classification.
Iris flower classification is a very popular machine learning project. The iris dataset contains three classes of flowers, Versicolor, Setosa, Virginica, and each class contains 4 features, ‘Sepal length’, ‘Sepal width’, ‘Petal length’, ‘Petal width’. The aim of the iris flower classification is to predict flowers based on their specific features.
What is machine learning?
Machine learning is about learning to predict something or extracting knowledge from data. ML is a part of artificial intelligence. ML algorithms build a model based on sample data or known as training data and based upon the training data the algorithm can predict something on new data.
Categories of Machine Learning
- Supervised machine learning: Supervised machine learning are types of machine learning that are trained on well-labeled training data. Labeled data means the training data is already tagged with the correct output.
- Unsupervised machine learning: Unlike supervised learning, unsupervised learning doesn’t have any tagged data. It learned patterns from untagged data. Basically, it creates a group of objects based on the input data/features.
- Semi-supervised machine learning: Semi-supervised learning falls between supervised and unsupervised learning. It has a small amount of tagged data and a large amount of untagged data.
Applications of Machine Learning
1. Speech Recognition: Speech recognition uses NLP (Natural Language Processing) to process human speech into written format and vice versa. Some examples are – Google Assistant, Alexa, Siri.
2. Recommendation Engine: Using the past behavior of a human’s search data the recommendation engine can produce new data to cross-sell products to customers. For example – Amazon product recommendations, Spotify music recommendations.
3. Chatbot: Chatbots are used to give customer services without any human agent. It takes questions from users and based on the question it gives an answer as a response.
In this project, we’ll solve the problem using a supervised learning approach. We’ll use an algorithm called “Support vector machine”.
Support vector machine: A support vector machine (also known as a support vector network) is a supervised machine learning algorithm that analyzes data for classification and regression. SVMs are one of the most robust classifications methods.
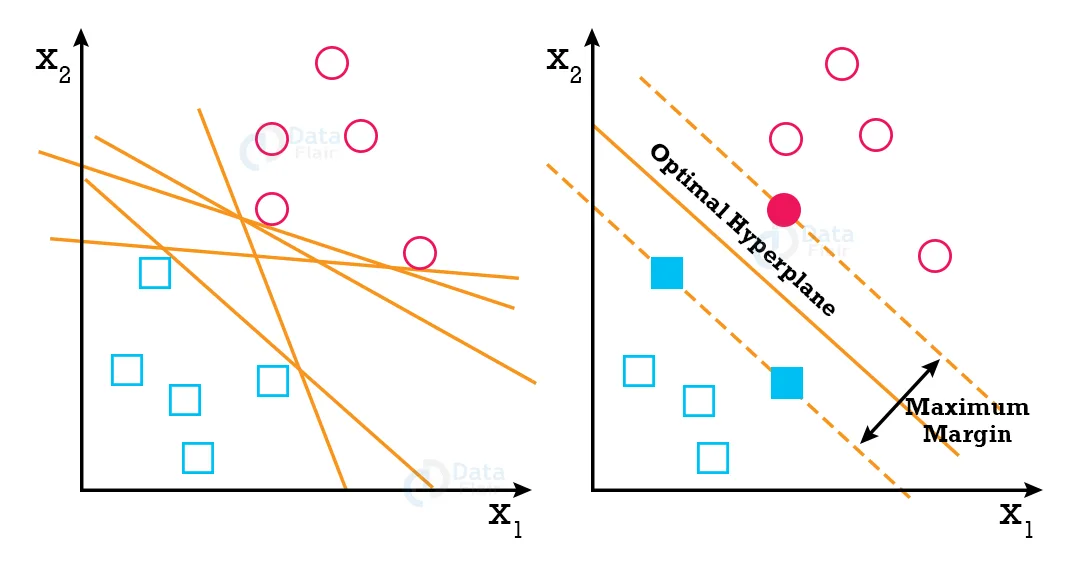
SVM approximates a separate line (Hyperplane) between two classes.

SVM algorithm finds the points closest to the line from both classes. These points are known as support vectors. Then it computes the distance between the line and support vectors. This distance is called the margin. The main goal is to maximize the margin. The hyperplane which has the maximum margin is known as the optimal hyperplane.
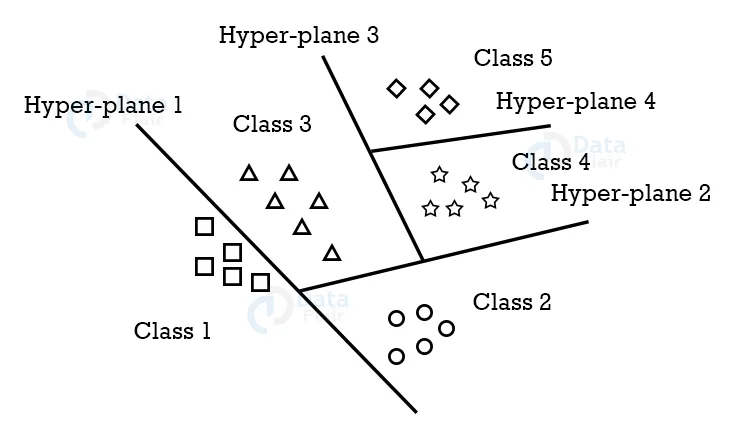
SVM mainly supports binary classification natively. For multiclass classification, It separates the data for binary classification and utilizes the same principle by breaking down multi-classification problems into multiple binary classification problems.
Prerequisites:
1. Numpy- 1.19.3
2. Matplotlib- 3.3.2
3. Seaborn – 0.11.1
4. Pandas – 1.2.4
5. Scikit-learn – 0.24.2
Download Iris Flower Classification Project Code
Please download the source code of iris flower classification with opencv: Iris Flower Classification Project Code
Steps to Classify Iris Flower:

1. Load the data
2. Analyze and visualize the dataset
3. Model training.
4. Model Evaluation.
5. Testing the model.
Step 1 – Load the data:
# DataFlair Iris Flower Classification # Import Packages import numpy as np import matplotlib.pyplot as plt import seaborn as sns import pandas as pd %matplotlib inline
First, we’ve imported some necessary packages for the project.
- Numpy will be used for any computational operations.
- We’ll use Matplotlib and seaborn for data visualization.
- Pandas help to load data from various sources like local storage, database, excel file, CSV file, etc.
columns = ['Sepal length', 'Sepal width', 'Petal length', 'Petal width', 'Class_labels']
# Load the data
df = pd.read_csv('iris.data', names=columns)
df.head()
- Next, we load the data using pd.read_csv() and set the column name as per the iris data information.
- Pd.read_csv reads CSV files. CSV stands for comma separated value.
- df.head() only shows the first 5 rows from the data set table.
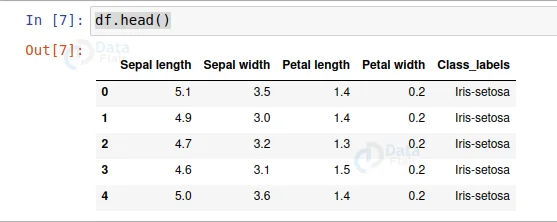
- All the numerical values are in centimeters.
Step 2 – Analyze and visualize the dataset:
Let’s see some information about the dataset.
# Some basic statistical analysis about the data df.describe()
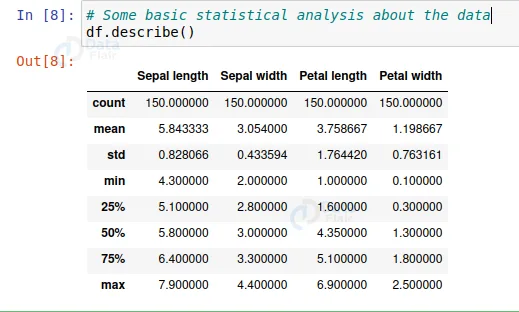
From this description, we can see all the descriptions about the data, like average length and width, minimum value, maximum value, the 25%, 50%, and 75% distribution value, etc.
Let’s visualize the dataset.
# Visualize the whole dataset sns.pairplot(df, hue='Class_labels')
- To visualize the whole dataset we used the seaborn pair plot method. It plots the whole dataset’s information.
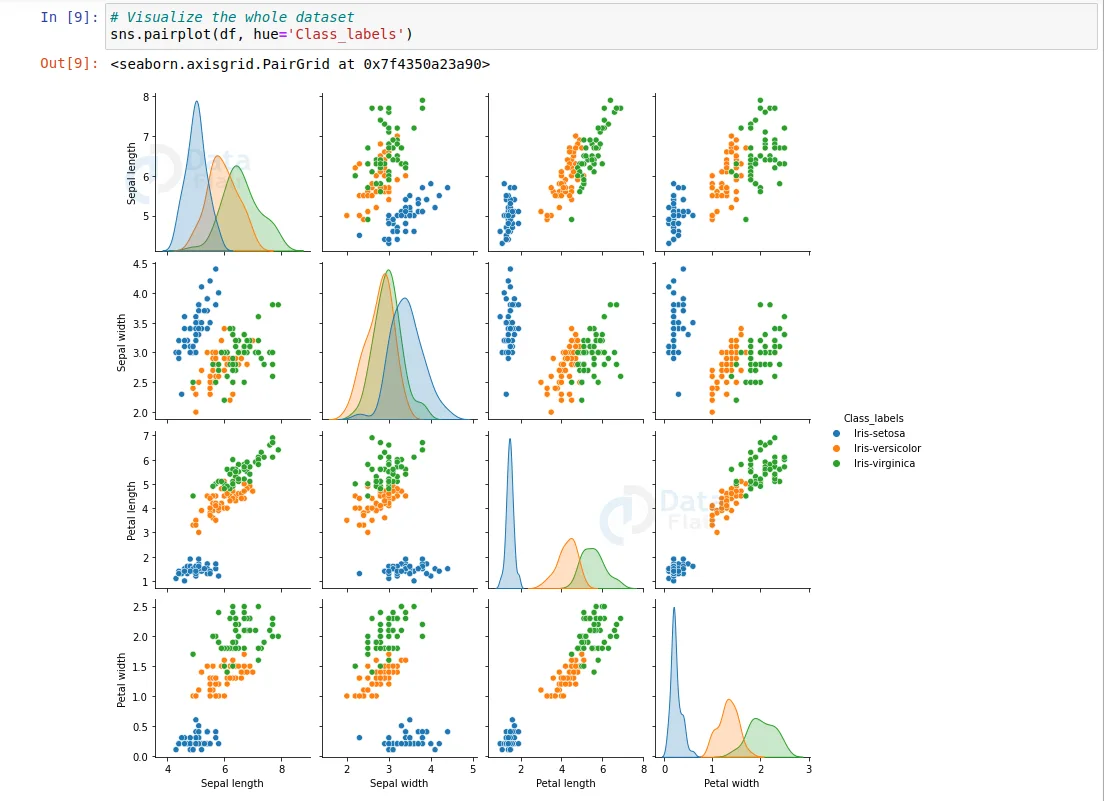
- From this visualization, we can tell that iris-setosa is well separated from the other two flowers.
- And iris virginica is the longest flower and iris setosa is the shortest.
Now let’s plot the average of each feature of each class.
# Separate features and target data = df.values X = data[:,0:4] Y = data[:,4]
- Here we separated the features from the target value.
# Calculate average of each features for all classes
Y_Data = np.array([np.average(X[:, i][Y==j].astype('float32')) for i in range (X.shape[1])
for j in (np.unique(Y))])
Y_Data_reshaped = Y_Data.reshape(4, 3)
Y_Data_reshaped = np.swapaxes(Y_Data_reshaped, 0, 1)
X_axis = np.arange(len(columns)-1)
width = 0.25
- Np.average calculates the average from an array.
- Here we used two for loops inside a list. This is known as list comprehension.
- List comprehension helps to reduce the number of lines of code.
- The Y_Data is a 1D array, but we have 4 features for every 3 classes. So we reshaped Y_Data to a (4, 3) shaped array.
- Then we change the axis of the reshaped matrix.
# Plot the average
plt.bar(X_axis, Y_Data_reshaped[0], width, label = 'Setosa')
plt.bar(X_axis+width, Y_Data_reshaped[1], width, label = 'Versicolour')
plt.bar(X_axis+width*2, Y_Data_reshaped[2], width, label = 'Virginica')
plt.xticks(X_axis, columns[:4])
plt.xlabel("Features")
plt.ylabel("Value in cm.")
plt.legend(bbox_to_anchor=(1.3,1))
plt.show()
- We used matplotlib to show the averages in a bar plot.
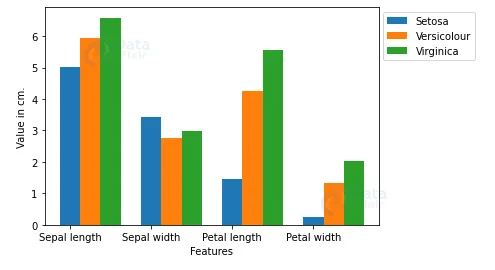
- Here we can clearly see the verginica is the longest and setosa is the shortest flower.
Step 3 – Model training:
# Split the data to train and test dataset. from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.2)
- Using train_test_split we split the whole data into training and testing datasets. Later we’ll use the testing dataset to check the accuracy of the model.
# Support vector machine algorithm from sklearn.svm import SVC svn = SVC() svn.fit(X_train, y_train)
- Here we imported a support vector classifier from the scikit-learn support vector machine.
- Then, we created an object and named it svn.
- After that, we feed the training dataset into the algorithm by using the svn.fit() method.
Step 4 – Model Evaluation:
# Predict from the test dataset predictions = svn.predict(X_test) # Calculate the accuracy from sklearn.metrics import accuracy_score accuracy_score(y_test, predictions)
- Now we predict the classes from the test dataset using our trained model.
- Then we check the accuracy score of the predicted classes.
- accuracy_score() takes true values and predicted values and returns the percentage of accuracy.
Output:
0.9666666666666667
The accuracy is above 96%.
Now let’s see the detailed classification report based on the test dataset.
# A detailed classification report
from sklearn.metrics import classification_report
print(classification_report(y_test, predictions))
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 9
Iris-versicolor 1.00 0.83 0.91 12
Iris-virginica 0.82 1.00 0.90 9
accuracy 0.93 30
macro avg 0.94 0.94 0.94 30
weighted avg 0.95 0.93 0.93 30
- The classification report gives a detailed report of the prediction.
- Precision defines the ratio of true positives to the sum of true positive and false positives.
- Recall defines the ratio of true positive to the sum of true positive and false negative.
- F1-score is the mean of precision and recall value.
- Support is the number of actual occurrences of the class in the specified dataset.
Step 5 – Testing the model:
X_new = np.array([[3, 2, 1, 0.2], [ 4.9, 2.2, 3.8, 1.1 ], [ 5.3, 2.5, 4.6, 1.9 ]])
#Prediction of the species from the input vector
prediction = svn.predict(X_new)
print("Prediction of Species: {}".format(prediction))
- Here we take some random values based on the average plot to see if the model can predict accurately.
Output:
Prediction of Species: [‘Iris-setosa’ ‘Iris-versicolor’ ‘Iris-virginica’]
It looks like the model is predicting correctly because the setosa is shortest and virginica is the longest and versicolor is in between these two.
# Save the model
import pickle
with open('SVM.pickle', 'wb') as f:
pickle.dump(svn, f)
# Load the model
with open('SVM.pickle', 'rb') as f:
model = pickle.load(f)
model.predict(X_new)
- We can save the model using pickle format.
- And again we can load the model in any other program using pickle and use it using model.predict to predict the iris data.
Summary
Iris Flower Classification is one of the simplest and most famous beginner-level ML projects. It uses the Iris dataset, which includes measurements of flower parts like petal and sepal length/width. The goal is to classify the flower into one of three species: Setosa, Versicolor, or Virginica. This project helps you understand data visualization, classification, and model evaluation using a clean, easy dataset.
In this project, we learned to train our own supervised machine learning model using Iris Flower Classification Project with Machine Learning. Through this project, we learned about machine learning, data analysis, data visualization, model creation, etc.
Did you know we work 24x7 to provide you best tutorials
Please encourage us - write a review on Google





Wow. This is very helpful for clearing concepts before I move on to the implementations with bigger models like RCNN etc. thanks for explaining each step so nicely in parts.
This is the best tutorial I’ve come across so far about ML implementation using the iris flower dataset.
As a beginner trying to understand how to implement a simple ML algorithm from start to finish, I’ve
seen a lot of guides but this is the best on the web with nicely explained and easy-to-understand steps.
Well done Data Flair.
Hi, thanks for the interesting article.
What if the new data is outside the range of these three classes?
for example, X = [15.3, 2.5, 8.0, 2.9]
What is its class according to the model you described above? Thank You
it can’t be out of range to that extent just because there’s do flower with those property values
hi, could someone pls help me with building the front end for the same?
i used streamlit but i couldn’t figure out on how to make prediction function for output display
Streamlit is very simple first you need to learn basic flow of streamlit then you find your solution very easily otherwise you have options Like Flask or Django but streamlit is simple as compaire to Flask and django.
thanks for sharing this kind of project flow. i am supper excited to make my own ML project
Thank you, it’s an excellent article