Install Hadoop on Ubuntu | Hadoop Installation Steps
1. Install Hadoop on Ubuntu Tutorial: Objective
This article explains how to install Hadoop on Ubuntu in simple steps. Moreover, we will deploy Hadoop on the single node cluster on Ubuntu Linux. We will also enable YARN on the cluster while installation.

Install Hadoop on Ubuntu | Hadoop Installation Steps
2. Hadoop Overview
Hadoop is a framework for running distributed computing programs. It comprises of HDFS and Map Reduce (Programming framework).
The user can run only the MapReduce program in the earlier versions of Hadoop. Therefore, it was fit for batch processing computations.
The YARN provides API for requesting and allocating resource in the cluster. So the YARN is available in later versions of Hadoop 2. Hence, the API facilitates application program to process large-scale data of HDFS.
3. Prerequisites to Install Hadoop on Ubuntu
- Hardware requirement- The machine must have 4GB RAM and minimum 60 GB hard disk for better performance.
- Check java version- It is recommended to install Oracle Java 8. If you are not aware of Java installation, follow this Java 8 installation tutorial. The user can check the version of java with below command.
[php]$ java -version[/php]
4. Easy Steps to install Hadoop on Ubuntu
Lets now discuss the steps to install Hadoop single node cluster on Ubuntu-
4.1. Setup passwordless ssh
a) Install Open SSH Server and Open SSH Client
We will now setup the passwordless ssh client with the following command.
[php]sudo apt-get install openssh-server openssh-client[/php]
Install Hadoop on Ubuntu – Open SSH Server and Open SSH Client
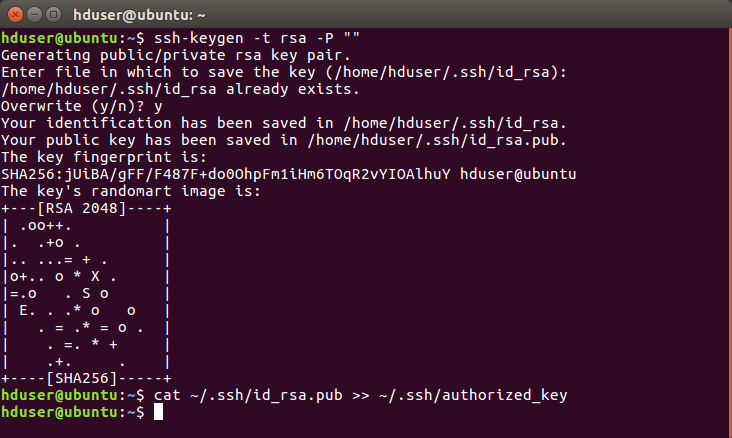
b) Generate Public & Private Key Pairs
[php]ssh-keygen -t rsa -P “”[/php]
The terminal will prompt the user for entering the file name. Press enter and proceed. The location of a file will be in the home directory. Moreover, the extension will be the .ssh file.
c) Configure password-less SSH
The below command will add the public ssh-key to authorized_keys. Moreover, it will configure the passwordless ssh.
[php]cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys[/php]
Install Hadoop on Ubuntu – Configure password-less SSH
Also see What is Hadoop Cluster | Hadoop Cluster Architecture
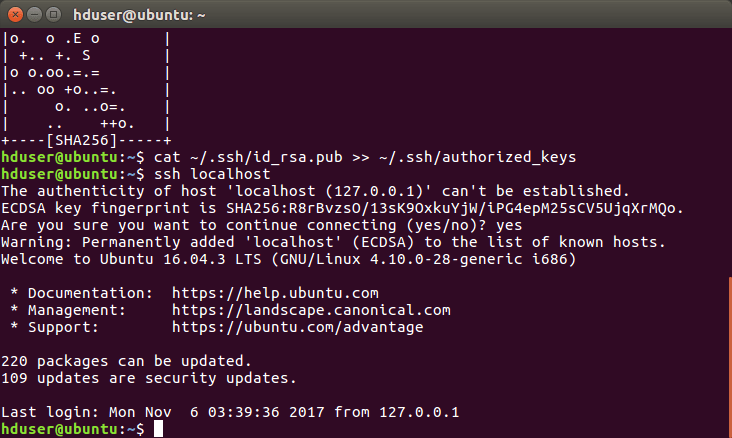
d) Now verify the working of password-less ssh
As we type the “ssh localhost” it will prompt us to connect with it. Type ‘yes’ and press enter to proceed.
e) Now install rsync with command
[php]$ sudo apt-get install rsync[/php]

Install Hadoop on Ubuntu | Install rsync
4.2. Configure and Setup Hadoop
a) Download the Hadoop package 2.8.x
Use the link given below to download the Hadoop 2.8.x from Apache mirrors.
http://www-eu.apache.org/dist/hadoop/common/hadoop-2.8.2/
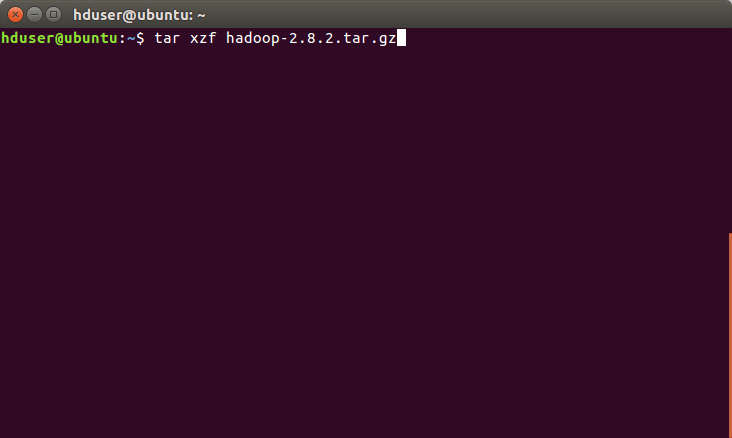
b) Untar the Tarball
Then we will extract the Hadoop into the home directory
[php]tar xzf hadoop-2.8.2.tar.gz[/php]
how to install hadoop on Ubuntu – Untar the Tarball
4.3. Setup Configuration
We can add only the minimum property in the Hadoop configuration. The user can add more properties to it.
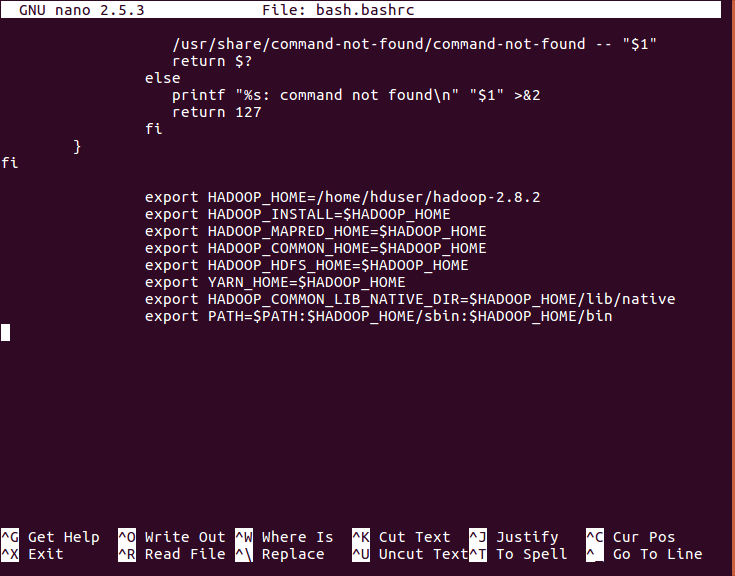
a) Setting Up the environment variables
- Edit .bashrc- Edit the bashrc and therefore add hadoop in a path:
[php]nano bash.bashrc[/php]
And add the following path variables in it
[php]export HADOOP_HOME=/home/hduser/hadoop-2.8.2
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin[/php]
Hadoop Installation – Edit .bashrc
- Source .bashrc in current login session in terminal
[php]source ~/.bashrc[/php]
Also see HBase Compaction and Data Locality in Hadoop
b) Hadoop configuration file changes
- Edit hadoop-env.sh
Edit hadoop-env.sh file which is in etc/hadoop inside the Hadoop installation directory. The user can set JAVA_HOME:
[php]export JAVA_HOME=<root directory of Java-installation> (eg: /usr/lib/jvm/jdk1.8.0_151/)[/php]
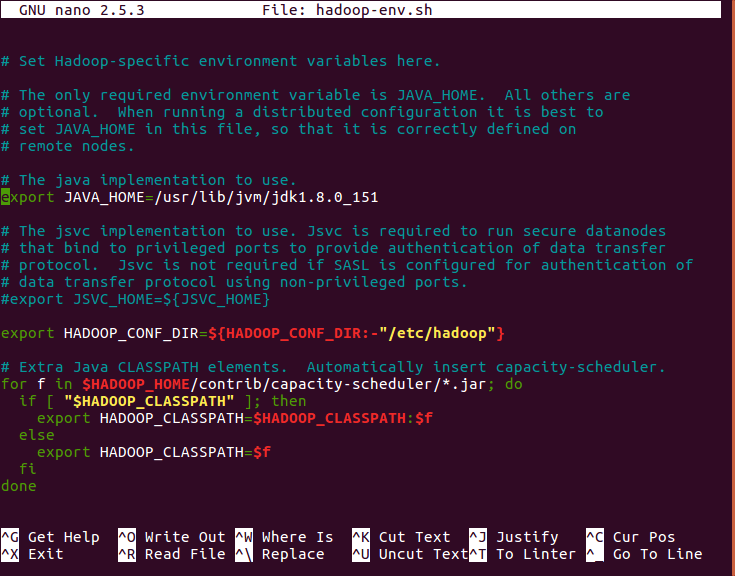
Edit hadoop-env.sh
- Edit core-site.xml
Edit the core-site.xml with “nano core-site.xml”. The file is in the etc/hadoop inside Hadoop directory. Then we will add following entries.
[php]<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hdadmin/hdata</value>
</property>
</configuration>[/php]
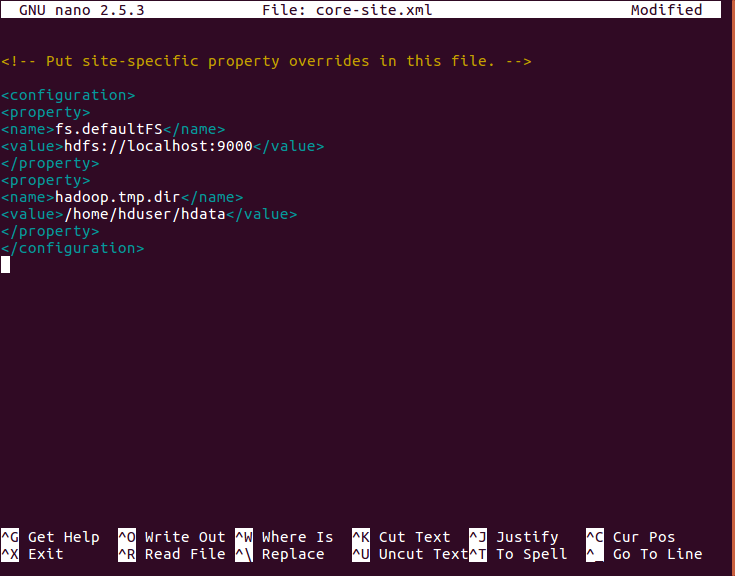
Hadoop 2 Installation – Edit core-site.xml
Then we will edit the hdfs-site.xml with “nano hdfs-site.xml”. This file is actually located in etc/hadoop inside Hadoop installation directory. We will add the following entries:
- Edit hdfs-site.xml
[php]<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>[/php]
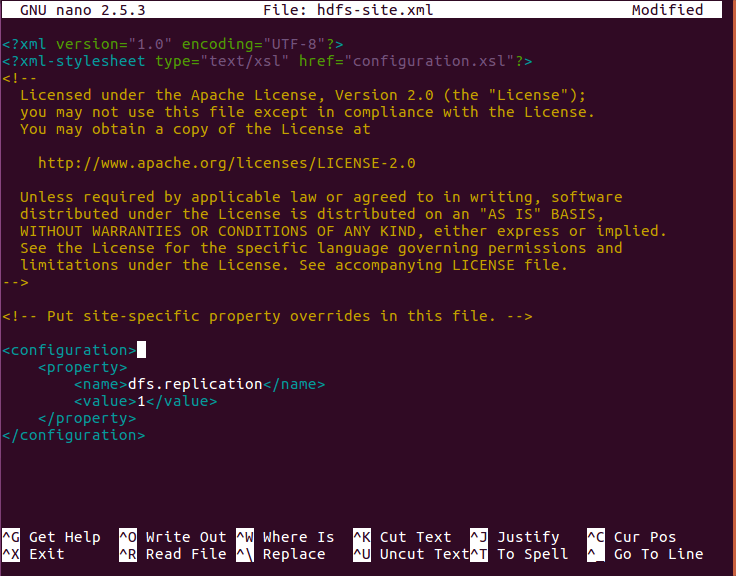
Install hadoop on Ubuntu – Edit hdfs-site.xml
- Edit mapred-site.xml
We will create a copy of mapred-site.xml from mapred-site.xml.template using cp command (cp mapred-site.xml.template mapred-site.xml). Now edit the mapred-site.xml with “nano command”. This file is also located in etc/hadoop inside Hadoop directory. We will copy the file with same name mapred-site.xml. This will add following entries:
[php]<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>[/php]
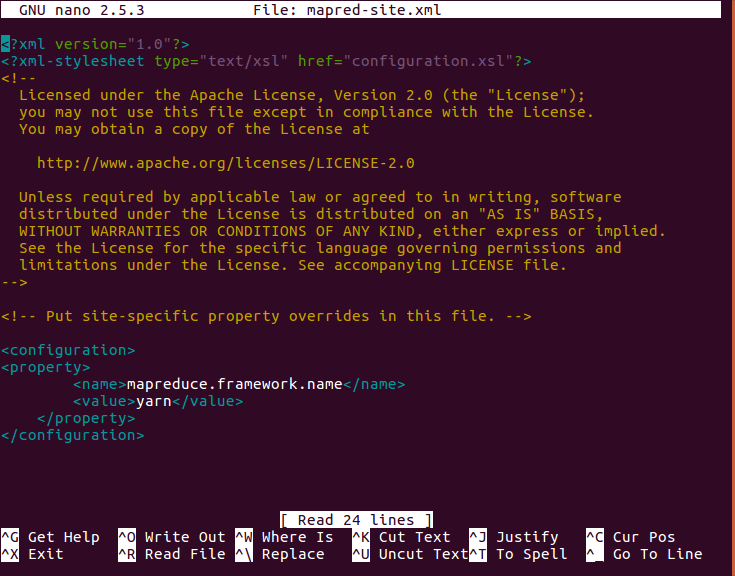
Install hadoop on Ubuntu – Edit mapred-site.xml
- Edit yarn-site.xml
We will now edit yarn-site.xml with “nano yarn-site.xml”. It is in etc/hadoop inside Hadoop installation directory. Finally we add following entries:
[php]<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>[/php]
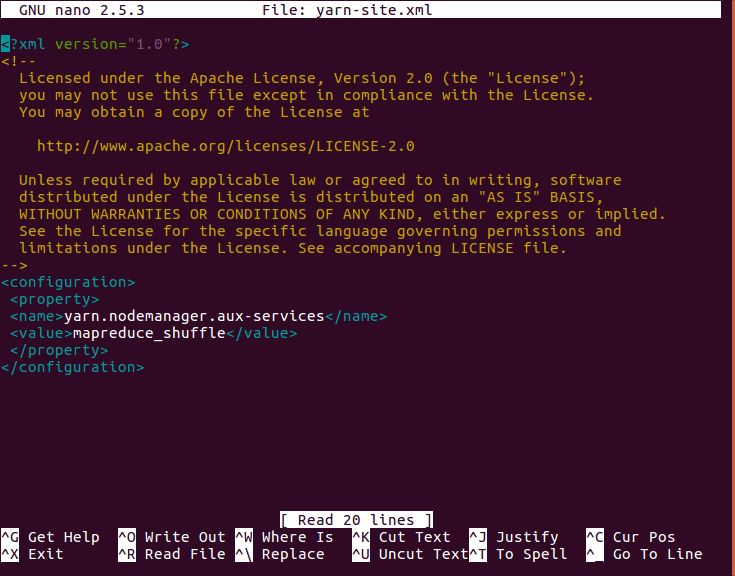
Hadoop Installation – Edit yarn-site.xml file.
Also see Unbeatable Apache Hadoop Online Quiz – Part 10
4.4. Start the cluster
We will now start the single node cluster with the following commands.
a) Format the namenode
Moreover, we will format the namenode before using it the first time.
[php]hdfs namenode -format[/php]
Install Hadoop 2 – Format the Namenode
b) Start the HDFS
We will start the hadoop cluster using the hadoop start-up script.
[php]start-dfs.sh[/php]
Hadoop start-up script
c) Starting the YARN services
For starting the YARN we use
[php]start-yarn.sh[/php]
Apache Hadoop Installation on Ubuntu – Starting the YARN services
d) Verify if all process started
[php]jps
6775 DataNode
7209 ResourceManager
7017 SecondaryNameNode
6651 NameNode
7339 NodeManager
7663 Jps[/php]

Install Hadoop on Ubuntu
e) Web interface-For viewing Web UI of NameNode
visit : (http://localhost:50070)
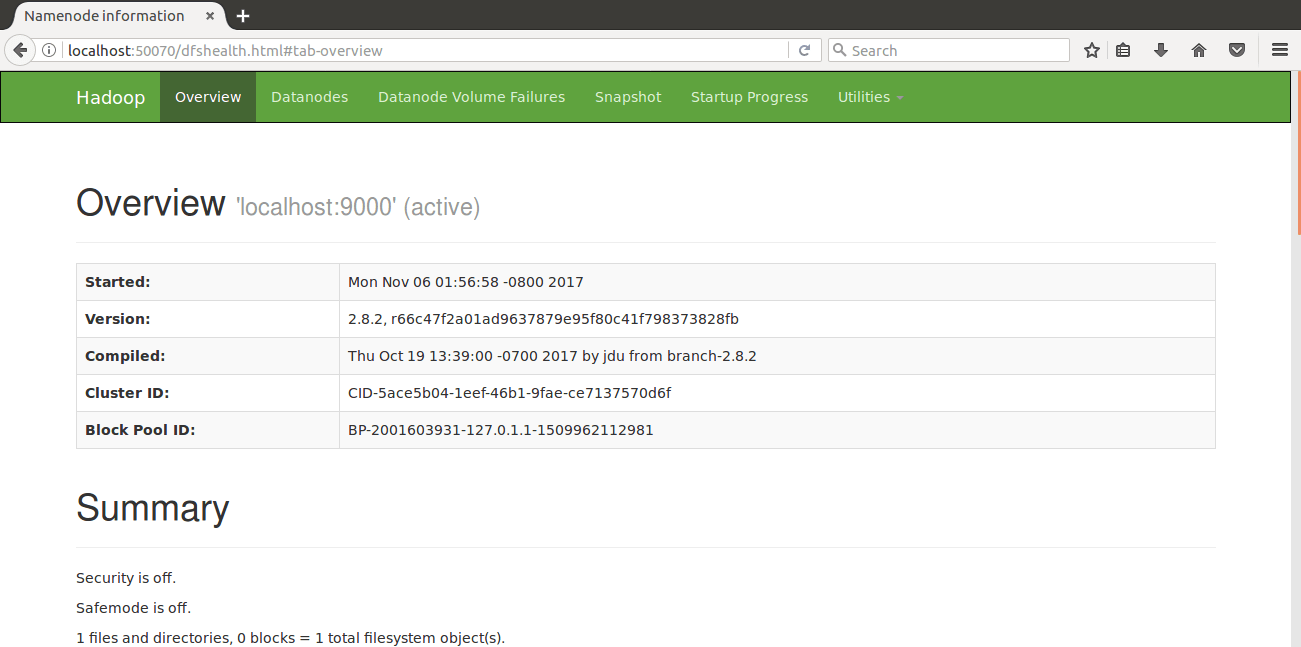
Web interface-For viewing Web UI of NameNode
Also see Hadoop Schedulers Tutorial – Job Scheduling in Hadoop
f) Resource Manager UI (http://localhost:8088)
The web interface will display all running jobs on cluster information. Hence, this will help monitor the progress report.
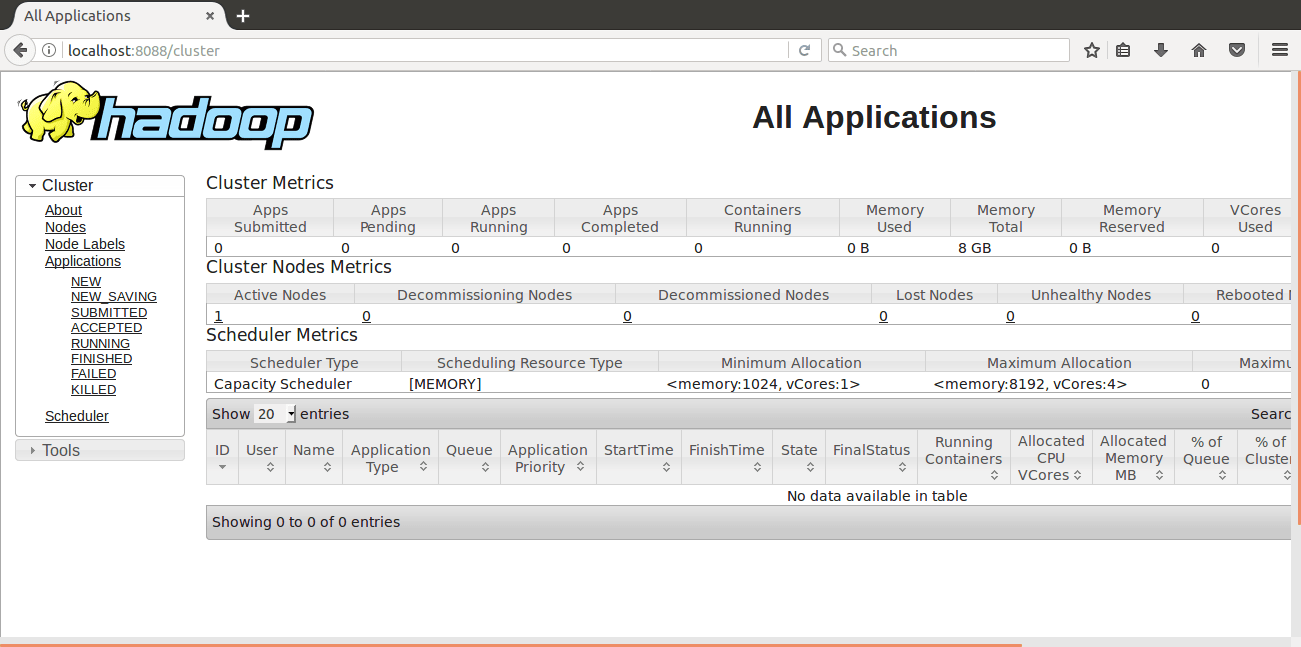
Hadoop Installation – Resource Manager UI
4.5. Stopping the clusters
To Stop the HDFS Services we use stop-dfs.sh. To Stop YARN Services we use
[php]stop-yarn.sh[/php]
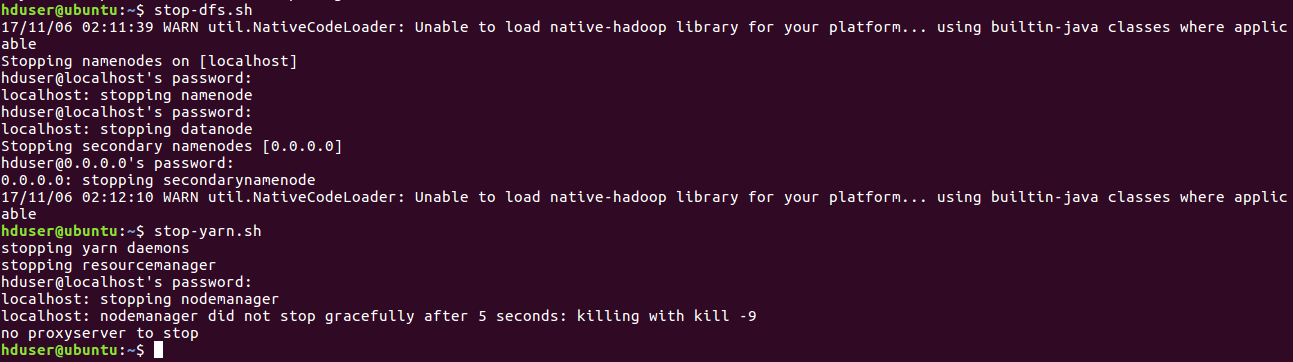
Install Hadoop on Ubuntu – Stopping the clusters
You have successfully installed Hadoop 2.8.x on Ubuntu. Now you can play with big data using Hadoop HDFS commands. For any queries on How to install Hadoop on Ubuntu just drop a comment and we will be back to you.
See Also-
Did you like our efforts? If Yes, please give DataFlair 5 Stars on Google





still am not installing hadoop in my system
ubuntu 18.04LTS
very good documentation
Author has not set 2 properties in hdfs-site.xml: “dfs.name.dir” and “dfs.data.dir”
hey Its not working on my machine which xml file we are supposed to edit nano xyz.xml or just the ones xyz.xml