Detecting Fake News with Python and Machine Learning
Machine Learning courses with 100+ Real-time projects Start Now!!
Do you trust all the news you hear from social media?
All news are not real, right?
How will you detect fake news?
The answer is Python. By practicing this advanced python project of detecting fake news, you will easily make a difference between real and fake news.
Before moving ahead in this machine learning project, get aware of the terms related to it like fake news, tfidfvectorizer, PassiveAggressive Classifier.
Also, I like to add that DataFlair has published a series of machine learning Projects where you will get interesting and open-source advanced ml projects. Do check, and then share your experience through comments. Here is the list of top Python projects:
- Fake News Detection Python Project
- Parkinson’s Disease Detection Python Project
- Color Detection Python Project
- Speech Emotion Recognition Python Project
- Breast Cancer Classification Python Project
- Age and Gender Detection Python Project
- Handwritten Digit Recognition Python Project
- Chatbot Python Project
- Driver Drowsiness Detection Python Project
- Traffic Signs Recognition Python Project
- Image Caption Generator Python Project
What is Fake News?
A type of yellow journalism, fake news encapsulates pieces of news that may be hoaxes and is generally spread through social media and other online media. This is often done to further or impose certain ideas and is often achieved with political agendas. Such news items may contain false and/or exaggerated claims, and may end up being viralized by algorithms, and users may end up in a filter bubble.
What is a TfidfVectorizer?
TF (Term Frequency): The number of times a word appears in a document is its Term Frequency. A higher value means a term appears more often than others, and so, the document is a good match when the term is part of the search terms.
IDF (Inverse Document Frequency): Words that occur many times a document, but also occur many times in many others, may be irrelevant. IDF is a measure of how significant a term is in the entire corpus.
The TfidfVectorizer converts a collection of raw documents into a matrix of TF-IDF features.
What is a PassiveAggressiveClassifier?
Passive Aggressive algorithms are online learning algorithms. Such an algorithm remains passive for a correct classification outcome, and turns aggressive in the event of a miscalculation, updating and adjusting. Unlike most other algorithms, it does not converge. Its purpose is to make updates that correct the loss, causing very little change in the norm of the weight vector.
Detecting Fake News with Python
To build a model to accurately classify a piece of news as REAL or FAKE.
About Detecting Fake News with Python
This advanced python project of detecting fake news deals with fake and real news. Using sklearn, we build a TfidfVectorizer on our dataset. Then, we initialize a PassiveAggressive Classifier and fit the model. In the end, the accuracy score and the confusion matrix tell us how well our model fares.
The fake news Dataset
The dataset we’ll use for this python project- we’ll call it news.csv. This dataset has a shape of 7796×4. The first column identifies the news, the second and third are the title and text, and the fourth column has labels denoting whether the news is REAL or FAKE. The dataset takes up 29.2MB of space and you can download it here.
Project Prerequisites
You’ll need to install the following libraries with pip:
pip install numpy pandas sklearn
You’ll need to install Jupyter Lab to run your code. Get to your command prompt and run the following command:
C:\Users\DataFlair>jupyter lab
You’ll see a new browser window open up; create a new console and use it to run your code. To run multiple lines of code at once, press Shift+Enter.
Steps for detecting fake news with Python
Follow the below steps for detecting fake news and complete your first advanced Python Project –
1. Make necessary imports:
import numpy as np import pandas as pd import itertools from sklearn.model_selection import train_test_split from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.linear_model import PassiveAggressiveClassifier from sklearn.metrics import accuracy_score, confusion_matrix
Screenshot:
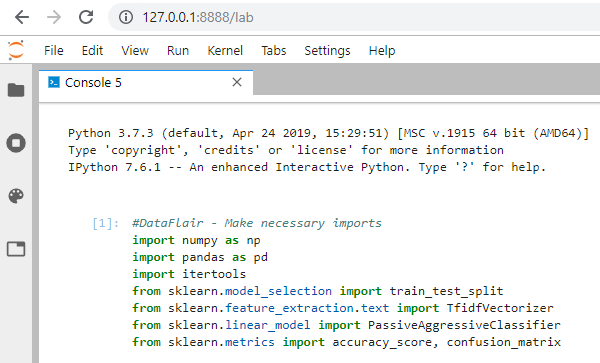
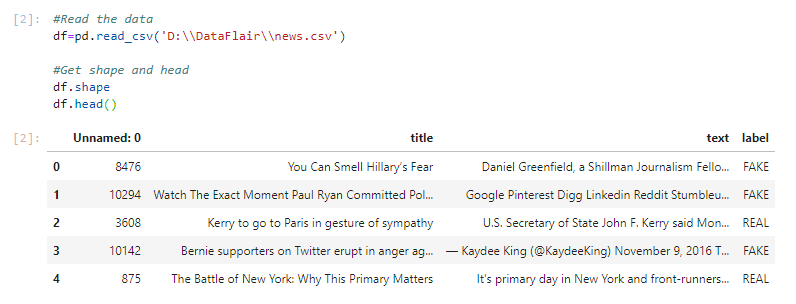
2. Now, let’s read the data into a DataFrame, and get the shape of the data and the first 5 records.
#Read the data
df=pd.read_csv('D:\\DataFlair\\news.csv')
#Get shape and head
df.shape
df.head()Output Screenshot:
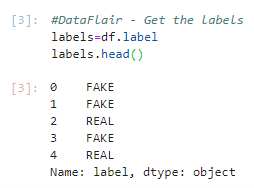
3. And get the labels from the DataFrame.
#DataFlair - Get the labels labels=df.label labels.head()
Output Screenshot:
4. Split the dataset into training and testing sets.
#DataFlair - Split the dataset x_train,x_test,y_train,y_test=train_test_split(df['text'], labels, test_size=0.2, random_state=7)
Screenshot:

5. Let’s initialize a TfidfVectorizer with stop words from the English language and a maximum document frequency of 0.7 (terms with a higher document frequency will be discarded). Stop words are the most common words in a language that are to be filtered out before processing the natural language data. And a TfidfVectorizer turns a collection of raw documents into a matrix of TF-IDF features.
Now, fit and transform the vectorizer on the train set, and transform the vectorizer on the test set.
#DataFlair - Initialize a TfidfVectorizer tfidf_vectorizer=TfidfVectorizer(stop_words='english', max_df=0.7) #DataFlair - Fit and transform train set, transform test set tfidf_train=tfidf_vectorizer.fit_transform(x_train) tfidf_test=tfidf_vectorizer.transform(x_test)
Screenshot:

6. Next, we’ll initialize a PassiveAggressiveClassifier. This is. We’ll fit this on tfidf_train and y_train.
Then, we’ll predict on the test set from the TfidfVectorizer and calculate the accuracy with accuracy_score() from sklearn.metrics.
#DataFlair - Initialize a PassiveAggressiveClassifier
pac=PassiveAggressiveClassifier(max_iter=50)
pac.fit(tfidf_train,y_train)
#DataFlair - Predict on the test set and calculate accuracy
y_pred=pac.predict(tfidf_test)
score=accuracy_score(y_test,y_pred)
print(f'Accuracy: {round(score*100,2)}%')Output Screenshot:
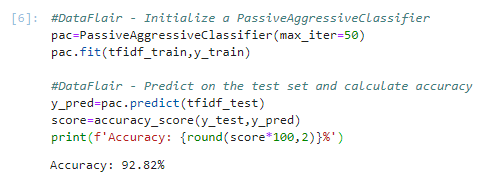
7. We got an accuracy of 92.82% with this model. Finally, let’s print out a confusion matrix to gain insight into the number of false and true negatives and positives.
#DataFlair - Build confusion matrix confusion_matrix(y_test,y_pred, labels=['FAKE','REAL'])
Output Screenshot:
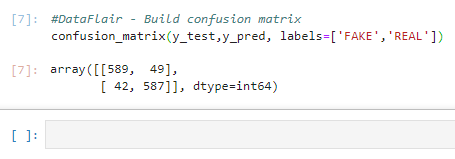
So with this model, we have 589 true positives, 587 true negatives, 42 false positives, and 49 false negatives.
Summary
Fake news spreads quickly on the internet and can cause serious problems. It can confuse people, create panic, or spread lies. A Machine Learning project in Python can help solve this issue. Using Natural Language Processing (NLP), we can build a model that reads the news headline or article and predicts if it’s real or fake. This project helps people and media companies check information before trusting it.
Today, we learned to detect fake news with Python. We took a political dataset, implemented a TfidfVectorizer, initialized a PassiveAggressiveClassifier, and fit our model. We ended up obtaining an accuracy of 92.82% in magnitude.
This project is very useful in today’s digital world. You can also make a simple website using Flask where users paste a news headline and see if it’s fake or not. It’s a practical and timely project to learn NLP, text classification, and real-world machine learning. Plus, it helps make the internet a safer place for information sharing.
Hope you enjoyed the fake news detection python project. Keep visiting DataFlair for more interesting python, data science, and machine learning projects.
If you are Happy with DataFlair, do not forget to make us happy with your positive feedback on Google





I am getting error in the following part of the code
#DataFlair – Fit and transform train set, transform test set
tfidf_train=tfidf_vectorizer.fit_transform(x_train)
part of error message – 2 tfidf_train=tfidf_vectorizer.fit_transform(x_train)
~\AppData\Local\Continuum\anaconda3\lib\site-packages\sklearn\feature_extraction\text.py in fit_transform(self, raw_documents, y)
1379 Tf-idf-weighted document-term matrix.
1380 “””
-> 1381 X = super(TfidfVectorizer, self).fit_transform(raw_documents)
1382 self._tfidf.fit(X)
1383 # X is already a transformed view of raw_documents so
Assuming your tokenizer works as expected, I see two sections to look into. First, TfIdfVectorizer expects a list of strings. Second, max_df is the threshold to remove terms that appear too frequently. set it to 0.7 means it ignores terms that appear in more than 70% of the documents. Have a look at these 2 sectors, it will surely resolve your error.
hello Gents,
please where to ger the corresponding .csv file
The csv file is given in dataset section in the article.
where is the sourcecode?
The source code is given in the article step wise with the explanation. Please copy the code and paste in Jupyter Notebook or Google Colab and execute accordingly.
can you share the screenshot of your error
Hello, When I run the line ‘y_pred=pac.predict(tfidf_test)’, I get this error ‘X has 33518 features per sample; expecting 61651’ . Could not understand what’s wrong here. Can someone help me with this?
Thank you in advance.
This error could be from the line ‘score=accuracy_score(y_test,y_pred) ‘, where we are trying to compare y_test and y_pred. If the lengths of these two structures are not the same then we get an error. Please check if you have assigned the variables in the correct order while splitting or if you have missed any lines. Hope this helps in solving your problem.
hi, how can i test this model in real world for example in New York Time’s articles ?
it worked well though i made some changes in parsing some codes but i followed the same approach thanks alot
Seriously I am working with this project ,Can you send me and update the code
I get this error in step 6. How to fix?
ValueError: Input contains NaN
Hello! Can you please share in which line in step 6, you are getting this value error?
Send me documentation of this project
I don’t understand how to rectify the same error issue said as above ,
Issue:
x_train not defined , apparently passing the fit and train model using tfidclassifier
If anybody can do it ,
The error x_train not defined will occur when there is no variable x_train in the program. Please check if you have run the code that created x_train or else check if the variable name is correctly defined. Hope one of these solves your problem
What date range is the data frome?
Can you please tell us more about what do you mean by data range? Hoping to hear from you soon.
Is the test set still available? The link seems to be broken.
Sorry for the inconvinience. We will try to sort this issue as soon as possible.
Can someone plz help me i cannot find the source code for this model
Hi following up on my prior comment – can anyone provide a date range of the underlying data source?
Thanks.
I can not understand the initialization and training of the set using TfidfVectorizer, can someone help me to understand the 5th block of code given in the article? also when I am implementing it, I am having a value error i.e
ValueError: np.nan is an invalid document, expected byte or unicode string.
In simple words, in the 5th step, we are first creating an instance of the TfidfVectorizer() class which helps us in tokenizing, splitting up a large text into smaller lines, words, or words from the non-English language. Then using this instance, we are transforming the data in x-train and x_test. Hope I could your query.
advanced features
How can i use in real word?
Tks
In real world, you can get the data from any source or you can also do web scraping. Using the obtained dataset, you can do the desired operations. Hope I could clear your doubt.
I m working this project …..Plz send me the source code of this project plz its urgent.
I get a Syntax error when I run the code below
#Read the data
df=pd.read_csv(‘C:\Users\goonb\Projects\Tests\Fake News Detection\news.csv’)
#Get shape and head
df.shape
df.head()
File “”, line 2
df=pd.read_csv(‘C:\Users\goonb\Projects\Tests\Fake News Detection\news.csv’)
^
SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated \UXXXXXXXX escape
You are getting this error because you are giving a normal string as a path to the read_csv() function. Any of the following three solutions can help you fix the problem: 1.pd.read_csv(r””C:\Users\goonb\Projects\Tests\Fake News Detection\news.csv””)
2.pd.read_csv(“”C:/Users/goonb/Projects/Tests/Fake News Detection/news.csv””)
3.pd.read_csv(“”C:\\Users\\goonb\\Projects\\Tests\\Fake News Detection\\news.csv””)
Step:6
y_pred=pac.predict(tfidf_test)
score=accuracy_score(y_test,y_pred)
print(f’Accuracy:{round(score*100,2)}%’)
Error
ValueError Traceback (most recent call last)
in
—-> 1 y_pred=pac.predict(tfidf_test)
2 score=accuracy_score(y_test,y_pred)
3 print(“f’Accuracy:{round(score*100,2)}%'”)
C:\ProgramData\Anaconda3\lib\site-packages\sklearn\linear_model\_base.py in predict(self, X)
307 Predicted class label per sample.
308 “””
–> 309 scores = self.decision_function(X)
310 if len(scores.shape) == 1:
311 indices = (scores > 0).astype(int)
C:\ProgramData\Anaconda3\lib\site-packages\sklearn\linear_model\_base.py in decision_function(self, X)
286 n_features = self.coef_.shape[1]
287 if X.shape[1] != n_features:
–> 288 raise ValueError(“X has %d features per sample; expecting %d”
289 % (X.shape[1], n_features))
290
ValueError: X has 33518 features per sample; expecting 61651
df=pd.read_csv(r‘C:\Users\goonb\Projects\Tests\Fake News Detection\news.csv’)
Put r infront of path
Anybody pls explain the working of this project.i didnt get no idea while checking the news.csv
In this project, we are trying to build a model that detects if the news is real or fake. For this, we are getting an appropriate dataset. Then we are splitting it into train and test parts. We are using the train part to give it to the classifier so that it can adjust the parameters per the given input data. And then using this trained model to predict the output given the test input data. Finally, we are finding the accuracy of the model by comparing the obtained input with the output we have from the dataset. I hope, I could make it clear.
Thanks
How can i use in real word?
def findlabel(newtext):
vec_newtest=tfidf_vectorizer.transform([newtext])
t_pred=pac.predict(vec_newtest)
t_pred.shape
return t_pred
If i give completely new fake news, from somewhere else, will it be accurate to predict? Isnt this program limited to the types of news given in the dataset. I think it will be better if we compare news with news on reputed sources and determine the fakeness through that.
Because we are training the classifier with the data set, if you adjust some of the parameters, you can fit the classifier and this would give good accuracy. Hope I could answer your query.
Checked the accuracy of classifier on ISOT dataset having 44898 sampless and it is poor approx. 51%
Could you explain the reason for this?
The accuracy depends also on the parameters that we set for the classifier. I think if you adjust them according to your dataset, by trial and error, or by other means, you can get better results.
Also, what should be done to improve it but considering the same classifier
Improvement can be either done by adjusting the parameters that we give to the classifier during training. Another method would be to get a larger data set and use it for training and testing.
Anybody pls explain the working of this project.i didnt get any idea
Hi can someone send me updated syntax
What do the values in the first non-index column map to? The article says it “identifies the news.” At first I thought maybe it corresponded to a news source, but they are unique. Does corresponds to a website address then? What was the original source of the data in the CSV file?