Detecting Fake News with Python and Machine Learning
Machine Learning courses with 100+ Real-time projects Start Now!!
Do you trust all the news you hear from social media?
All news are not real, right?
How will you detect fake news?
The answer is Python. By practicing this advanced python project of detecting fake news, you will easily make a difference between real and fake news.
Before moving ahead in this machine learning project, get aware of the terms related to it like fake news, tfidfvectorizer, PassiveAggressive Classifier.
Also, I like to add that DataFlair has published a series of machine learning Projects where you will get interesting and open-source advanced ml projects. Do check, and then share your experience through comments. Here is the list of top Python projects:
- Fake News Detection Python Project
- Parkinson’s Disease Detection Python Project
- Color Detection Python Project
- Speech Emotion Recognition Python Project
- Breast Cancer Classification Python Project
- Age and Gender Detection Python Project
- Handwritten Digit Recognition Python Project
- Chatbot Python Project
- Driver Drowsiness Detection Python Project
- Traffic Signs Recognition Python Project
- Image Caption Generator Python Project
What is Fake News?
A type of yellow journalism, fake news encapsulates pieces of news that may be hoaxes and is generally spread through social media and other online media. This is often done to further or impose certain ideas and is often achieved with political agendas. Such news items may contain false and/or exaggerated claims, and may end up being viralized by algorithms, and users may end up in a filter bubble.
What is a TfidfVectorizer?
TF (Term Frequency): The number of times a word appears in a document is its Term Frequency. A higher value means a term appears more often than others, and so, the document is a good match when the term is part of the search terms.
IDF (Inverse Document Frequency): Words that occur many times a document, but also occur many times in many others, may be irrelevant. IDF is a measure of how significant a term is in the entire corpus.
The TfidfVectorizer converts a collection of raw documents into a matrix of TF-IDF features.
What is a PassiveAggressiveClassifier?
Passive Aggressive algorithms are online learning algorithms. Such an algorithm remains passive for a correct classification outcome, and turns aggressive in the event of a miscalculation, updating and adjusting. Unlike most other algorithms, it does not converge. Its purpose is to make updates that correct the loss, causing very little change in the norm of the weight vector.
Detecting Fake News with Python
To build a model to accurately classify a piece of news as REAL or FAKE.
About Detecting Fake News with Python
This advanced python project of detecting fake news deals with fake and real news. Using sklearn, we build a TfidfVectorizer on our dataset. Then, we initialize a PassiveAggressive Classifier and fit the model. In the end, the accuracy score and the confusion matrix tell us how well our model fares.
The fake news Dataset
The dataset we’ll use for this python project- we’ll call it news.csv. This dataset has a shape of 7796×4. The first column identifies the news, the second and third are the title and text, and the fourth column has labels denoting whether the news is REAL or FAKE. The dataset takes up 29.2MB of space and you can download it here.
Project Prerequisites
You’ll need to install the following libraries with pip:
pip install numpy pandas sklearn
You’ll need to install Jupyter Lab to run your code. Get to your command prompt and run the following command:
C:\Users\DataFlair>jupyter lab
You’ll see a new browser window open up; create a new console and use it to run your code. To run multiple lines of code at once, press Shift+Enter.
Steps for detecting fake news with Python
Follow the below steps for detecting fake news and complete your first advanced Python Project –
1. Make necessary imports:
import numpy as np import pandas as pd import itertools from sklearn.model_selection import train_test_split from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.linear_model import PassiveAggressiveClassifier from sklearn.metrics import accuracy_score, confusion_matrix
Screenshot:
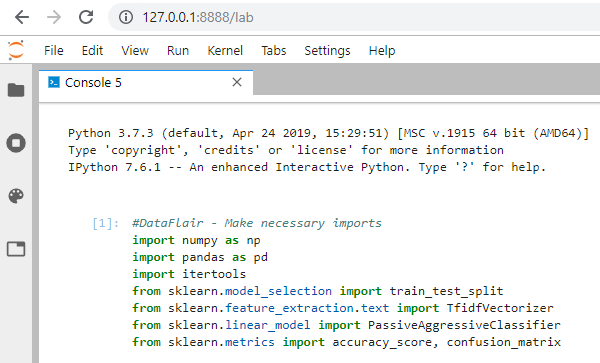
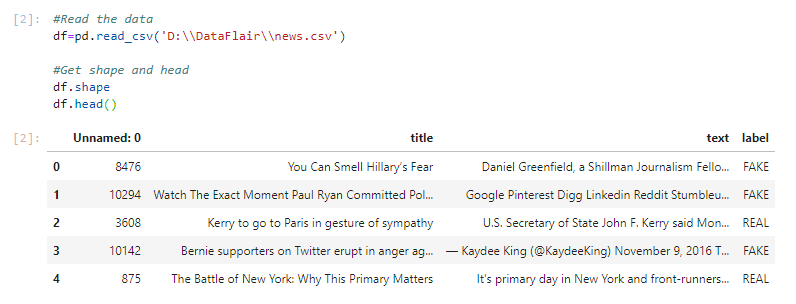
2. Now, let’s read the data into a DataFrame, and get the shape of the data and the first 5 records.
#Read the data
df=pd.read_csv('D:\\DataFlair\\news.csv')
#Get shape and head
df.shape
df.head()Output Screenshot:
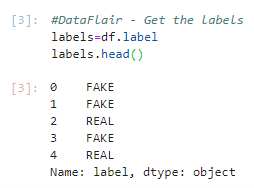
3. And get the labels from the DataFrame.
#DataFlair - Get the labels labels=df.label labels.head()
Output Screenshot:
4. Split the dataset into training and testing sets.
#DataFlair - Split the dataset x_train,x_test,y_train,y_test=train_test_split(df['text'], labels, test_size=0.2, random_state=7)
Screenshot:

5. Let’s initialize a TfidfVectorizer with stop words from the English language and a maximum document frequency of 0.7 (terms with a higher document frequency will be discarded). Stop words are the most common words in a language that are to be filtered out before processing the natural language data. And a TfidfVectorizer turns a collection of raw documents into a matrix of TF-IDF features.
Now, fit and transform the vectorizer on the train set, and transform the vectorizer on the test set.
#DataFlair - Initialize a TfidfVectorizer tfidf_vectorizer=TfidfVectorizer(stop_words='english', max_df=0.7) #DataFlair - Fit and transform train set, transform test set tfidf_train=tfidf_vectorizer.fit_transform(x_train) tfidf_test=tfidf_vectorizer.transform(x_test)
Screenshot:

6. Next, we’ll initialize a PassiveAggressiveClassifier. This is. We’ll fit this on tfidf_train and y_train.
Then, we’ll predict on the test set from the TfidfVectorizer and calculate the accuracy with accuracy_score() from sklearn.metrics.
#DataFlair - Initialize a PassiveAggressiveClassifier
pac=PassiveAggressiveClassifier(max_iter=50)
pac.fit(tfidf_train,y_train)
#DataFlair - Predict on the test set and calculate accuracy
y_pred=pac.predict(tfidf_test)
score=accuracy_score(y_test,y_pred)
print(f'Accuracy: {round(score*100,2)}%')Output Screenshot:
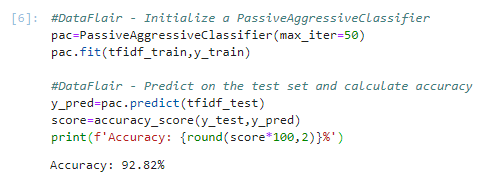
7. We got an accuracy of 92.82% with this model. Finally, let’s print out a confusion matrix to gain insight into the number of false and true negatives and positives.
#DataFlair - Build confusion matrix confusion_matrix(y_test,y_pred, labels=['FAKE','REAL'])
Output Screenshot:
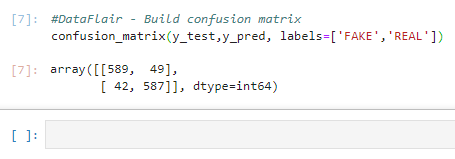
So with this model, we have 589 true positives, 587 true negatives, 42 false positives, and 49 false negatives.
Summary
Fake news spreads quickly on the internet and can cause serious problems. It can confuse people, create panic, or spread lies. A Machine Learning project in Python can help solve this issue. Using Natural Language Processing (NLP), we can build a model that reads the news headline or article and predicts if it’s real or fake. This project helps people and media companies check information before trusting it.
Today, we learned to detect fake news with Python. We took a political dataset, implemented a TfidfVectorizer, initialized a PassiveAggressiveClassifier, and fit our model. We ended up obtaining an accuracy of 92.82% in magnitude.
This project is very useful in today’s digital world. You can also make a simple website using Flask where users paste a news headline and see if it’s fake or not. It’s a practical and timely project to learn NLP, text classification, and real-world machine learning. Plus, it helps make the internet a safer place for information sharing.
Hope you enjoyed the fake news detection python project. Keep visiting DataFlair for more interesting python, data science, and machine learning projects.
Did you know we work 24x7 to provide you best tutorials
Please encourage us - write a review on Google





Hello,
From where I get the project of “Age and Gender detection in python”?
Thanks
We have added the post on Python Project on the blog home. You can check it here as well – https://data-flair.training/blogs/python-project-gender-age-detection/
not abke to download datasets of fake news detecting projects.
The dataset download link is available in the downloads section in the article
using which model is it made?
We used the Passive aggressive classifier algorithm to train the model.
How can i access news.zip-Google Drive file? While opening it showing error in loading file. While i was trying to practice detecting fake news with python project.
The issue has been resolved, it’s working fine, please download the dataset and start working on the project
When I try to run your code, I get a memory error:
—> 35 pac.fit(tfidf_train, y_train)
Please can you explain what’s going on?
During training via model.fit(), for big data in a system with low RAM the system tries to free memory. It keeps reducing and eventually it runs out of memory with a “Killed” error. You should look at training in batches.
The Label Column is already segregating the news as REAL or FAKE then why are we making this model of detecting the news as real or fake
Suppose you want to automate the task of identifying news as Real or Fake. For this purpose, how will you create the model?
What we are doing here is that feeding the model with a dataset.
It contains the news and their labels. The model will look for patterns using the algorithm and adjust the weights on the model. Now our model can predict news as Real or Fake.
Yes, we already knew that, but what about new data? We can use the model to predict new news that can classify them. This is what machine learning is about.
Note: The model’s accuracy in real-world depends on the dataset. We need a large amount of labeled data to make good models.
I can’t run the code. will the output look like? Would you add it here. Is there also a github link?
If you are facing any issues please post the complete stacktrace, we will look into the issue.
we have not added fake news detection project on github, the complete code is available in the article you can copy and run the same.
Thats why it is called as supervising learning it means the labels are already known .The aim of this algorithm is to train the data and to predict the model.
I liked this Website so much.
thanks it helped me alot
have you run the code ?
how can we give new data ..which is a current news and show its output like is fake or it real..how can we give new news article and say that it is fake or not!!
thanks a lot .
Hi , how can we adapt this code to detect online fake job ? I need help for it please.
from where i should get source code for fake news detection
Hello Sanjana,
The full source code is available in this blog. Just follow along and go through each of the steps individually.
I used your model to predict latest news and it shows fake.
Hey Hassan,
The model will usually work good on data that is similar to the dataset. As the dataset used for this model is small. For real world application we need to train our model on very huge datasets.
I understand the need to create a model to test new bits of data, but I’m having trouble actually using the model to test a new piece of news. How would I test a headline using the model to actually make a real-world prediction?
iam looking for a project such as a fake news detection that does and detect automatically and views a popup like output .ie it take news from online using a web crawler and then it takes news from some trusted sources and then compare them all to produce whether the news is fake or true .can u help me out?
Thanks! This is insightful but how can I finish it and use it on current news? Simply put How can I deploy it
Hey!
The algorithm stopped working when I got to the train/split step.
It returns this error
—————————————————————————
NameError Traceback (most recent call last)
in
—-> 1 x_train,x_test,y_train,y_test=train_test_split(df[‘text’], labels, test_size=0.2, random_state=7)
NameError: name ‘labels’ is not defined
What does it mean for ‘L’ not to be defined?
I’d appreciate prompt assists.
Please check the folowing
labels=df.label
labels.head()
‘labels’ is not defined I mean
how to classify that news is fake or real writing like this:
PAC.predict([‘ Obama is running for president in 2016’])
How can I check if this working correct or not ? ps : It was very helpful.
i think fake news detection is not good idea
Is there any paper regarding this topic??
How can I check for a new sentence whether it is fake or real news
Hi
I want to ask that why you have taken only text column as feature in train_test_split ?????we also could take title along with this.
Please explain i am not getting this point.
It depends on requirements, yes we can take it along with the content
Could you please provide any relevant information regarding concept of passive aggressive classifier algorithm??
The Passive-Aggressive algorithms are generally used for large-scale learning. This is one of the popular ‘online-learning algorithms‘.
In online machine learning algorithms, the input data comes in sequential order and the machine learning model is updated or trained step-by-step, as opposed to the batch learning algorithm where the entire training dataset is used at once. This is very useful in case where there is a huge amount of data and where new data is being added frequently.
hlo
i am getting keyerror : text
how to get rid of this though i have done everything as explained.
reply needed urgently!!!!!!
A Python KeyError exception is what is raised when you try to access a key that isn’t in a dictionary (dict). Please check if the correct csv file is loaded. Here this error is telling that there isn’t any column named text in df.
on splitting data sets into training and testing
i am getting a keyerror : test when using df[‘text’]
reply needed asap
A Python KeyError exception is what is raised when you try to access a key that isn’t in a dictionary (dict). Please check if the correct csv file is loaded. Here this error is telling that there isn’t any column named text in df.
while using dataframe like df[‘text’]
i am getting keyerror : text
althoug doing everything as explained