Emoji Prediction using Deep Learning
Machine Learning courses with 100+ Real-time projects Start Now!!
Emojis are a wonderful method to express oneself.
This deep learning project automatically predicts emojis based on a given phrase.
About Emoji Prediction Project
In this machine learning project, we predict the emoji from the given text. This means we build a text classifier that returns an emoji that suits the given text.
Our systems should be aware of the relevant emoji to use at the proper moment.
Emoji Prediciton Dataset
The dataset consists of 2 parts, each is used for training and testing the deep learning model.
The training dataset contains 4 columns, one column being the text and the other contains IDs representing the emojis. Keep in mind that, here in our dataset the same sentence can have more than 1 emoji as a result.
You can download the emoji prediction dataset along with the project code in the next section.
Tools and Libraries:
- Python – 3.x
- Numpy – 1.19.2
- Pandas – 1.2.4
- TensorFlow – 2.4.x
- Emoji – 1.2.0
To install the above modules, run the following command:
pip install numpy pandas tensorflow emoji
Emoji Prediction Project Code & Dataset
Please download the dataset & source code of the emoji prediction project (which is explained below): Emoji Prediction Python Code & Dataset
Steps to build Emoji Prediction model
To build this text classifier, we follow the below steps:
1. Perform Exploratory Data Analysis (EDA).
2. Build the classifier model.
3. Train and evaluate the model.
Step 1: Perform Exploratory Data Analysis (EDA)
Load the dataset using pandas.
import pandas as pd
train = pd.read_csv('./Desktop/DataFlair/train_emoji.csv',header=None)
test = pd.read_csv('./Desktop/DataFlair/test_emoji.csv',header=None)
Now, let’s have a look at the datasets.
train.head()

test.head()

If you observe, there are 5 types of emojis in our dataset: heart, baseball, smile, disappointed, fork and knife.
Let’s store the above information in a dictionary for ease of use.
emoji_dict = { 0 : ":heart:", 1 : ":baseball:", 2 : ":smile:", 3 : ":disappointed:", 4 : ":fork_and_knife:"}Now using the emoji module, see how these emojis turn out!
import emoji
for ix in emoji_dict.keys():
print (ix,end=" ")
print (emoji.emojize(emoji_dict[ix], use_aliases=True))

Create the training and testing data from the datasets unlike the formal method of using the train_test_split() function from the sklearn.
X_train = train[0]
Y_train = train[1]
X_test = test[0]
Y_test = test[1]
for ix in range(X_train.shape[0]):
X_train[ix] = X_train[ix].split()
for ix in range(X_test.shape[0]):
X_test[ix] = X_test[ix].split()
Y_train = to_categorical(Y_train)Now, let’s check if our above conversion to categorical labels is done.
print (X_train[0],Y_train[0]) np.unique(np.array([len(ix) for ix in X_train]) , return_counts=True)

We use word embeddings in this emoji prediction project to represent the text.
The relationship between the words is represented using word embeddings. This process aims to create a vector with lesser dimensions. An embedding is a low-dimensional space into which high-dimensional vectors can be translated. Machine learning on huge inputs, such as sparse vectors representing words, is made simpler via embeddings.
We use the 6B 50D GloVe vector to build the embedding matrix for the text in our dataset. The file can be downloaded from here.
Now compute the embedding matrix.
embeddings_index = {}
f = open('./glove.6B.50d.txt', encoding="utf-8")
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
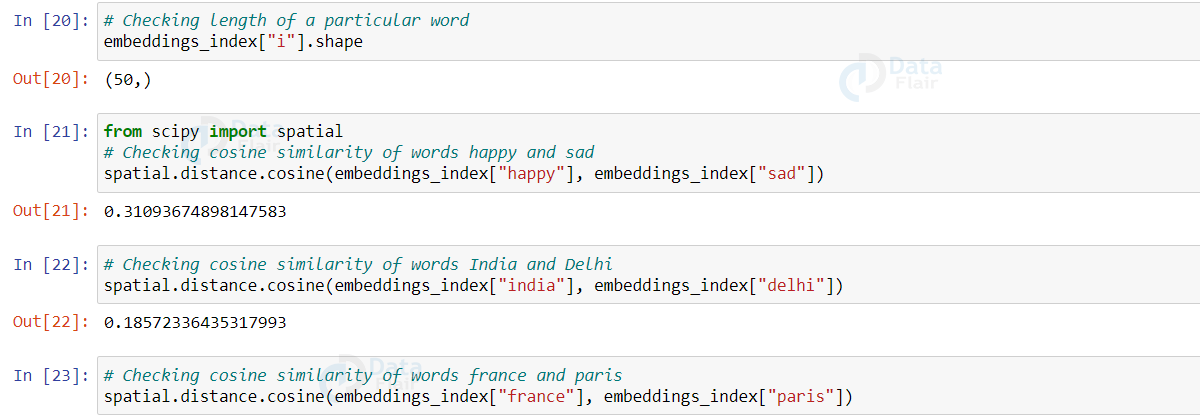
Now, as a part of EDA let’s check the cosine similarity scores of various words like happy and sad, India and Delhi, France, and Paris.
Observe how these words are similar.
from scipy import spatial spatial.distance.cosine(embeddings_index["happy"],embeddings_index["sad"]) spatial.distance.cosine(embeddings_index["india"],embeddings_index["delhi"]) spatial.distance.cosine(embeddings_index["france"],embeddings_index["paris"])
Output:
Fill the embedding matrix.
import numpy as np
embedding_matrix_train = np.zeros((X_train.shape[0], 10, 50))
embedding_matrix_test = np.zeros((X_test.shape[0], 10, 50))
for ix in range(X_train.shape[0]):
for ij in range(len(X_train[ix])):
embedding_matrix_train[ix][ij] = embeddings_index[X_train[ix][ij].lower()]
for ix in range(X_test.shape[0]):
for ij in range(len(X_test[ix])):
embedding_matrix_test[ix][ij] = embeddings_index[X_test[ix][ij].lower()]
Let’s see the shape of the embedding matrix.

Step 2: Build the Text Classifier for Emoji Prediction
For this emoji prediction project, we will be using a simple LSTM network.
LSTM stands for Long Short Term Network. Recurrent neural networks are a type of deep neural network used to deal with sequential types of data like audio files, text data, etc.
LSTMs are a variant of Recurrent neural networks that are capable of learning long-term dependencies. LSTM networks work well with time-series data.
Let’s build a simple LSTM network using TensorFlow.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Input, Dropout, SimpleRNN, LSTM, Activation
model = Sequential()
model.add(LSTM(128, input_shape=(10,50), return_sequences=True))
model.add(Dropout(0.5))
model.add(LSTM(128, return_sequences=False))
model.add(Dropout(0.5))
model.add(Dense(5))
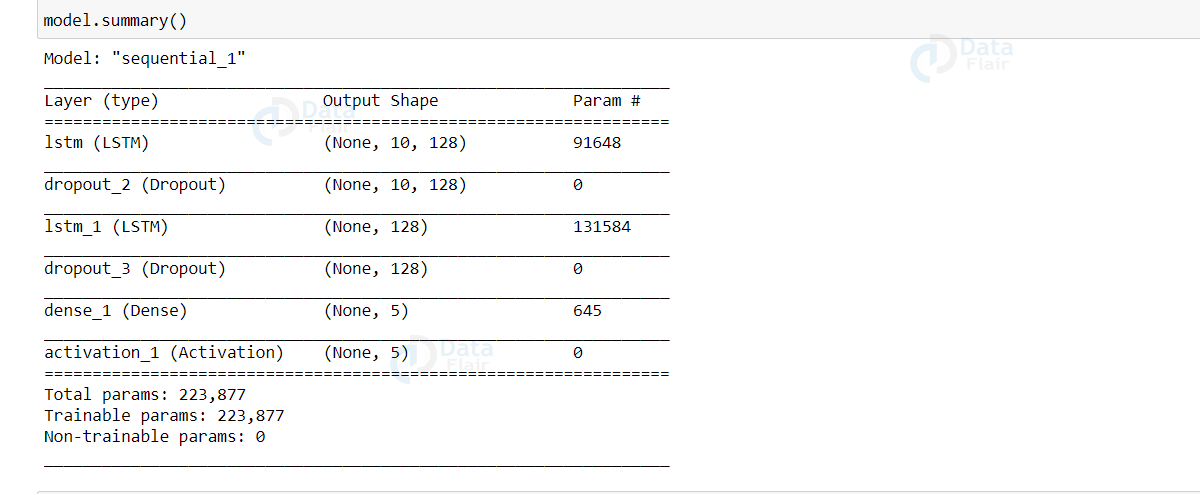
model.add(Activation('softmax'))Let’s look at the summary of our model.
model.summary()
Step 3: Train and evaluate the ml model
Now compile and fit our model against the embedding matrix we have computed using the training data. The categorical crossentropy is used as the loss function and Adam is used as the optimizer function. For metrics, accuracy is used.
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) hist = model.fit(embedding_matrix_train,Y_train, epochs = 50, batch_size=32,shuffle=True)
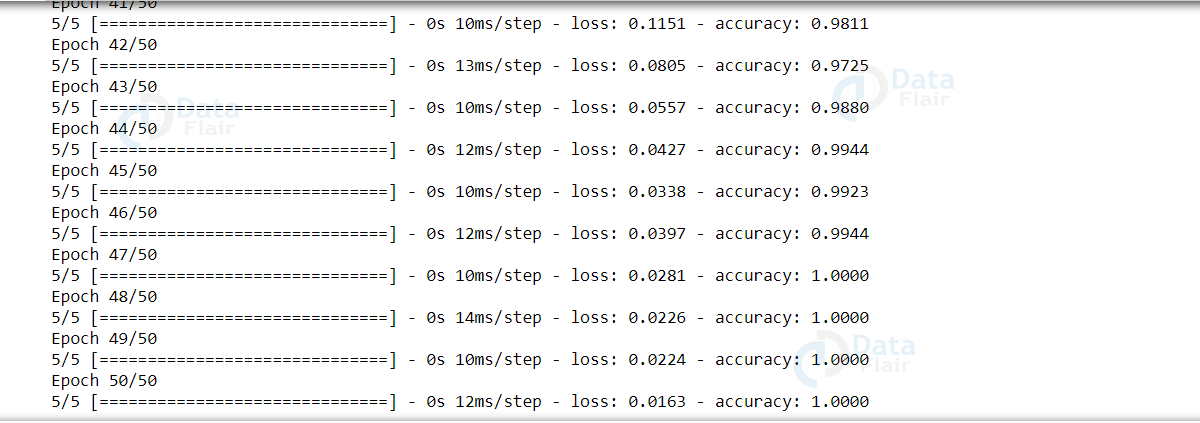
We got 100% accuracy on our emoji prediction training set!
Let’s predict the emoji labels on the testing data.
pred = model.predict_classes(embedding_matrix_test) float(sum(pred==Y_test))/embedding_matrix_test.shape[0]
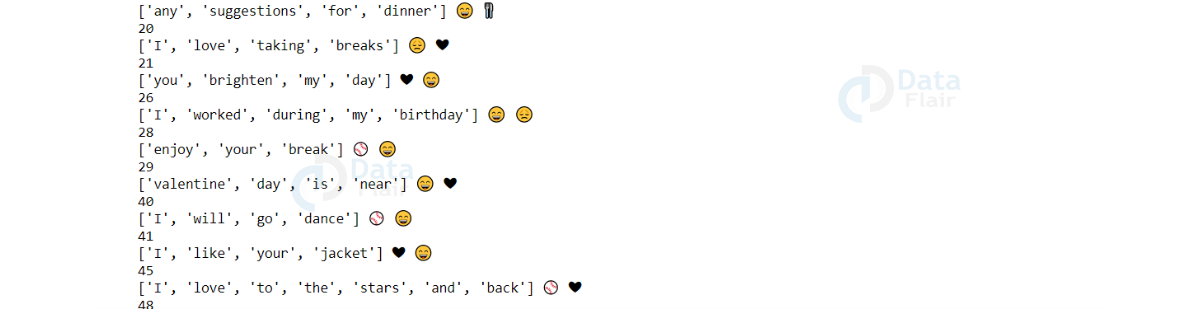
Below code prints the text in the test dataset and its predicted emoji by our text classifier.
for ix in range(embedding_matrix_test.shape[0]):
if pred[ix] != Y_test[ix]:
print(ix)
print (test[0][ix],end=" ")
print (emoji.emojize(emoji_dict[pred[ix]], use_aliases=True),end=" ")
print (emoji.emojize(emoji_dict[Y_test[ix]], use_aliases=True))
Let’s print the confusion matrix.
import itertools
from sklearn.metrics import confusion_matrix
conf_matrix = confusion_matrix(Y_test, pred)
print("Confusion Matrix")
print(conf_matrix)
The confusion matrix for emoji prediction when visualized looks like this.

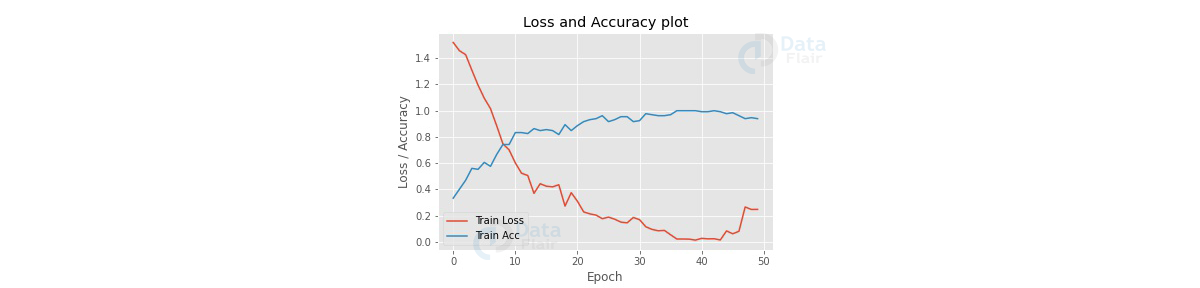
Plot the loss and accuracies of our model on the dataset.
import matplot.pyplot as plt
epochs = 50
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, epochs), hist.history["loss"], label = "Train Loss")
plt.plot(np.arange(0, epochs), hist.history["accuracy"], label = "Train Acc")
plt.title("Loss and Accuracy plot")
plt.xlabel("Epoch")
plt.ylabel("Loss / Accuracy")
plt.legend(loc = "lower left")
plt.savefig("plot.jpg")
Summary
In this deep learning project, we built a text classifier that predicts an emoji that suits the given text. We achieve good accuracy in the implementation, although based on requirements we can train it with larger datasets. To predict emojis, we used LSTM as LSTM networks work well with time-series data.
Your 15 seconds will encourage us to work even harder
Please share your happy experience on Google





there is no attribute predict_classes