Cats vs Dogs Classification (with 98.7% Accuracy) using CNN Keras – Deep Learning Project for Beginners
Machine Learning courses with 100+ Real-time projects Start Now!!
Cats vs Dogs classification is a fundamental Deep Learning project for beginners. If you want to start your Deep Learning Journey with Python Keras, you must work on this elementary project.
In this Keras project, we will discover how to build and train a convolution neural network for classifying images of Cats and Dogs.
The Asirra (Dogs VS Cats) dataset:
The Asirra (animal species image recognition for restricting access) dataset was introduced in 2013 for a machine learning competition. The dataset includes 25,000 images with equal numbers of labels for cats and dogs.
Dataset: Cats and Dogs dataset
Deep Learning Project for Beginners – Cats and Dogs Classification

Steps to build Cats vs Dogs classifier:
1. Import the libraries:
import numpy as np import pandas as pd from keras.preprocessing.image import ImageDataGenerator,load_img from keras.utils import to_categorical from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt import random import os
2. Define image properties:
Image_Width=128 Image_Height=128 Image_Size=(Image_Width,Image_Height) Image_Channels=3
3. Prepare dataset for training model:
filenames=os.listdir("./dogs-vs-cats/train")
categories=[]
for f_name in filenames:
category=f_name.split('.')[0]
if category=='dog':
categories.append(1)
else:
categories.append(0)
df=pd.DataFrame({
'filename':filenames,
'category':categories
})4. Create the neural net model:
from keras.models import Sequential
from keras.layers import Conv2D,MaxPooling2D,\
Dropout,Flatten,Dense,Activation,\
BatchNormalization
model=Sequential()
model.add(Conv2D(32,(3,3),activation='relu',input_shape=(Image_Width,Image_Height,Image_Channels)))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Conv2D(64,(3,3),activation='relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Conv2D(128,(3,3),activation='relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512,activation='relu'))
model.add(BatchNormalization())
model.add(Dropout(0.5))
model.add(Dense(2,activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',metrics=['accuracy'])5. Analyzing model:
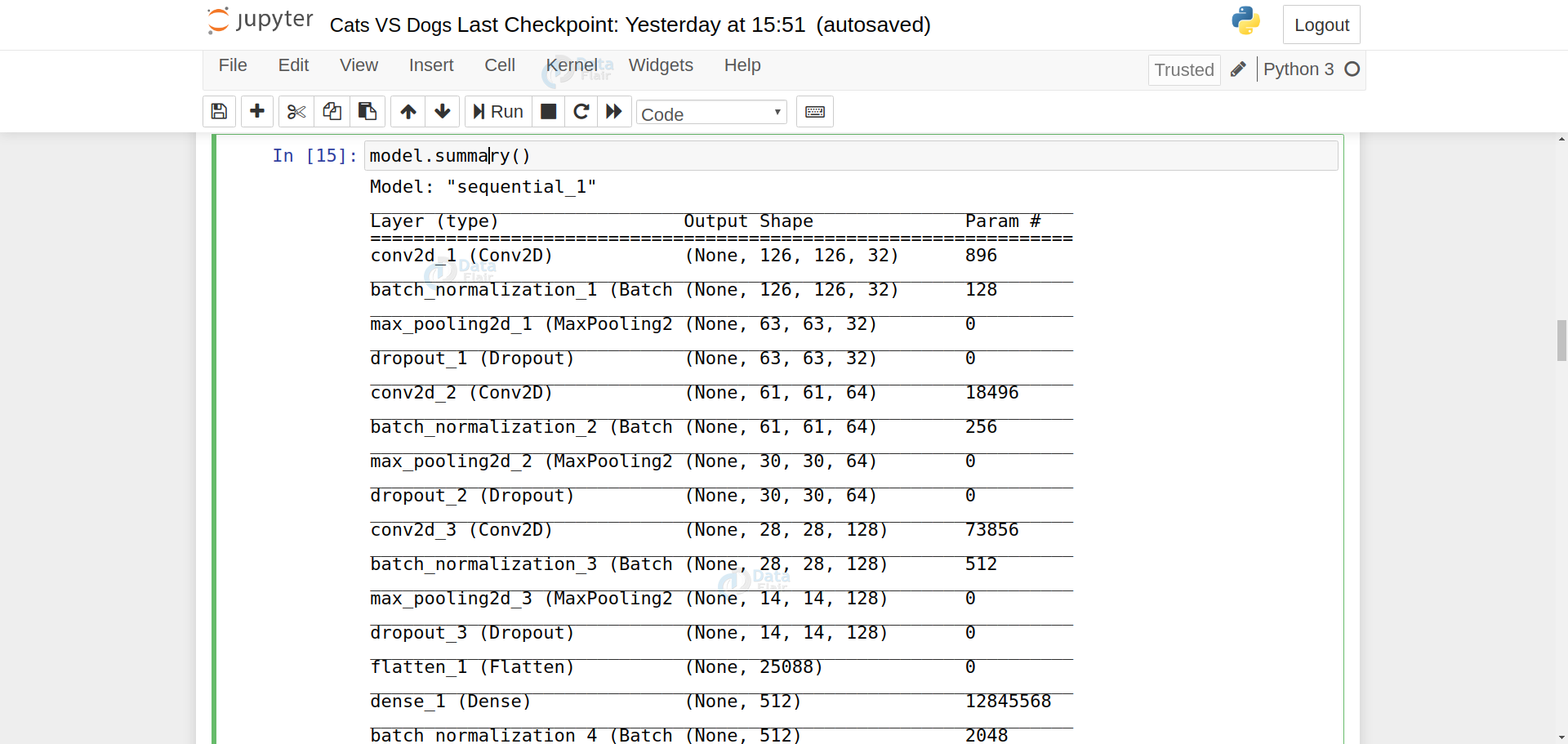
model.summary()
6. Define callbacks and learning rate:
from keras.callbacks import EarlyStopping, ReduceLROnPlateau earlystop = EarlyStopping(patience = 10) learning_rate_reduction = ReduceLROnPlateau(monitor = 'val_acc',patience = 2,verbose = 1,factor = 0.5,min_lr = 0.00001) callbacks = [earlystop,learning_rate_reduction]
7. Manage data:
df["category"] = df["category"].replace({0:'cat',1:'dog'})
train_df,validate_df = train_test_split(df,test_size=0.20,
random_state=42)
train_df = train_df.reset_index(drop=True)
validate_df = validate_df.reset_index(drop=True)
total_train=train_df.shape[0]
total_validate=validate_df.shape[0]
batch_size=158. Training and validation data generator:
train_datagen = ImageDataGenerator(rotation_range=15,
rescale=1./255,
shear_range=0.1,
zoom_range=0.2,
horizontal_flip=True,
width_shift_range=0.1,
height_shift_range=0.1
)
train_generator = train_datagen.flow_from_dataframe(train_df,
"./dogs-vs-cats/train/",x_col='filename',y_col='category',
target_size=Image_Size,
class_mode='categorical',
batch_size=batch_size)
validation_datagen = ImageDataGenerator(rescale=1./255)
validation_generator = validation_datagen.flow_from_dataframe(
validate_df,
"./dogs-vs-cats/train/",
x_col='filename',
y_col='category',
target_size=Image_Size,
class_mode='categorical',
batch_size=batch_size
)
test_datagen = ImageDataGenerator(rotation_range=15,
rescale=1./255,
shear_range=0.1,
zoom_range=0.2,
horizontal_flip=True,
width_shift_range=0.1,
height_shift_range=0.1)
test_generator = train_datagen.flow_from_dataframe(train_df,
"./dogs-vs-cats/test/",x_col='filename',y_col='category',
target_size=Image_Size,
class_mode='categorical',
batch_size=batch_size)
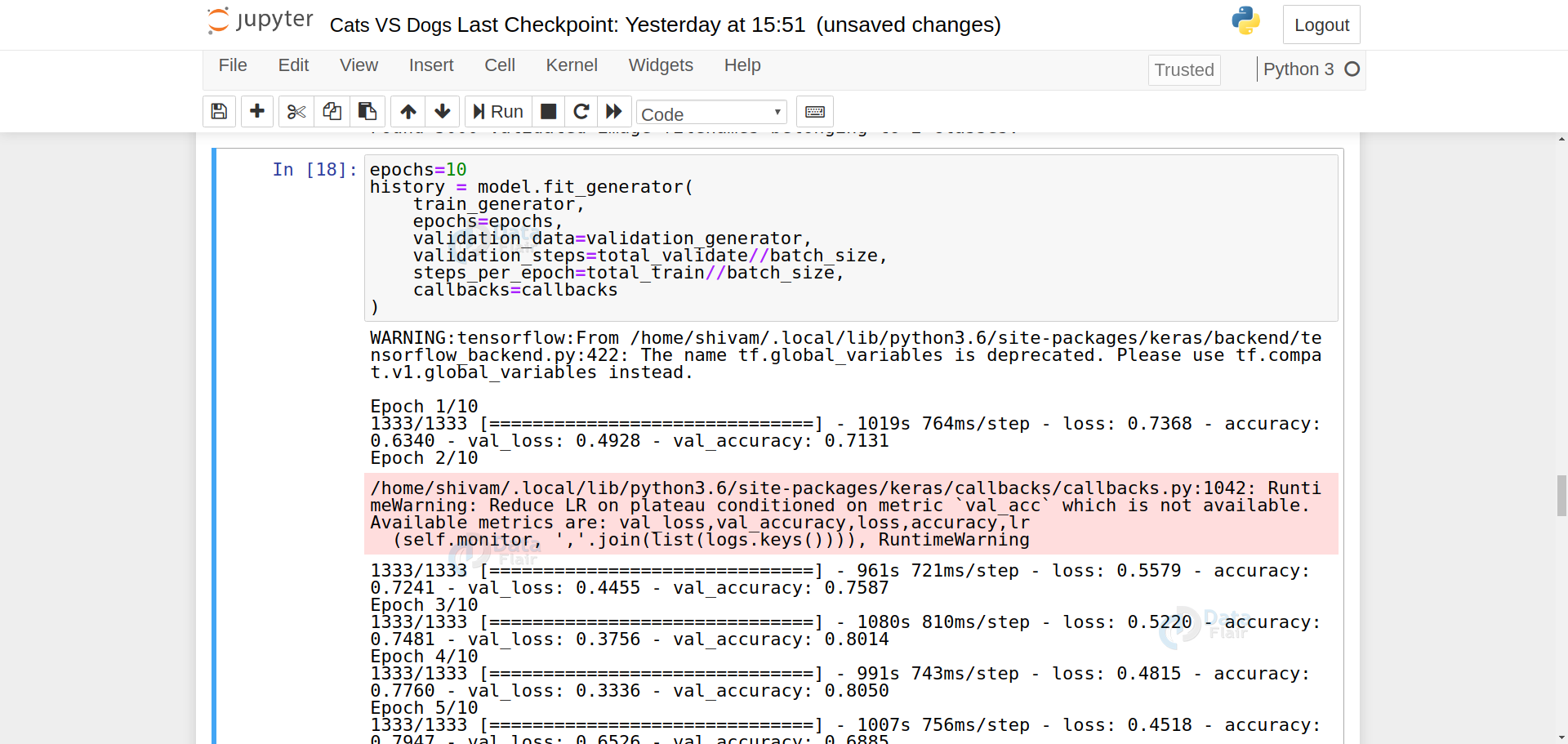
9. Model Training:
epochs=10
history = model.fit_generator(
train_generator,
epochs=epochs,
validation_data=validation_generator,
validation_steps=total_validate//batch_size,
steps_per_epoch=total_train//batch_size,
callbacks=callbacks
)
10. Save the model:
model.save("model1_catsVSdogs_10epoch.h5")11. Test data preparation:
test_filenames = os.listdir("./dogs-vs-cats/test1")
test_df = pd.DataFrame({
'filename': test_filenames
})
nb_samples = test_df.shape[0]12. Make categorical prediction:
predict = model.predict_generator(test_generator, steps=np.ceil(nb_samples/batch_size))
13. Convert labels to categories:
test_df['category'] = np.argmax(predict, axis=-1)
label_map = dict((v,k) for k,v in train_generator.class_indices.items())
test_df['category'] = test_df['category'].replace(label_map)
test_df['category'] = test_df['category'].replace({ 'dog': 1, 'cat': 0 })14. Visualize the prediction results:
sample_test = test_df.head(18)
sample_test.head()
plt.figure(figsize=(12, 24))
for index, row in sample_test.iterrows():
filename = row['filename']
category = row['category']
img = load_img("./dogs-vs-cats/test1/"+filename, target_size=Image_Size)
plt.subplot(6, 3, index+1)
plt.imshow(img)
plt.xlabel(filename + '(' + "{}".format(category) + ')' )
plt.tight_layout()
plt.show()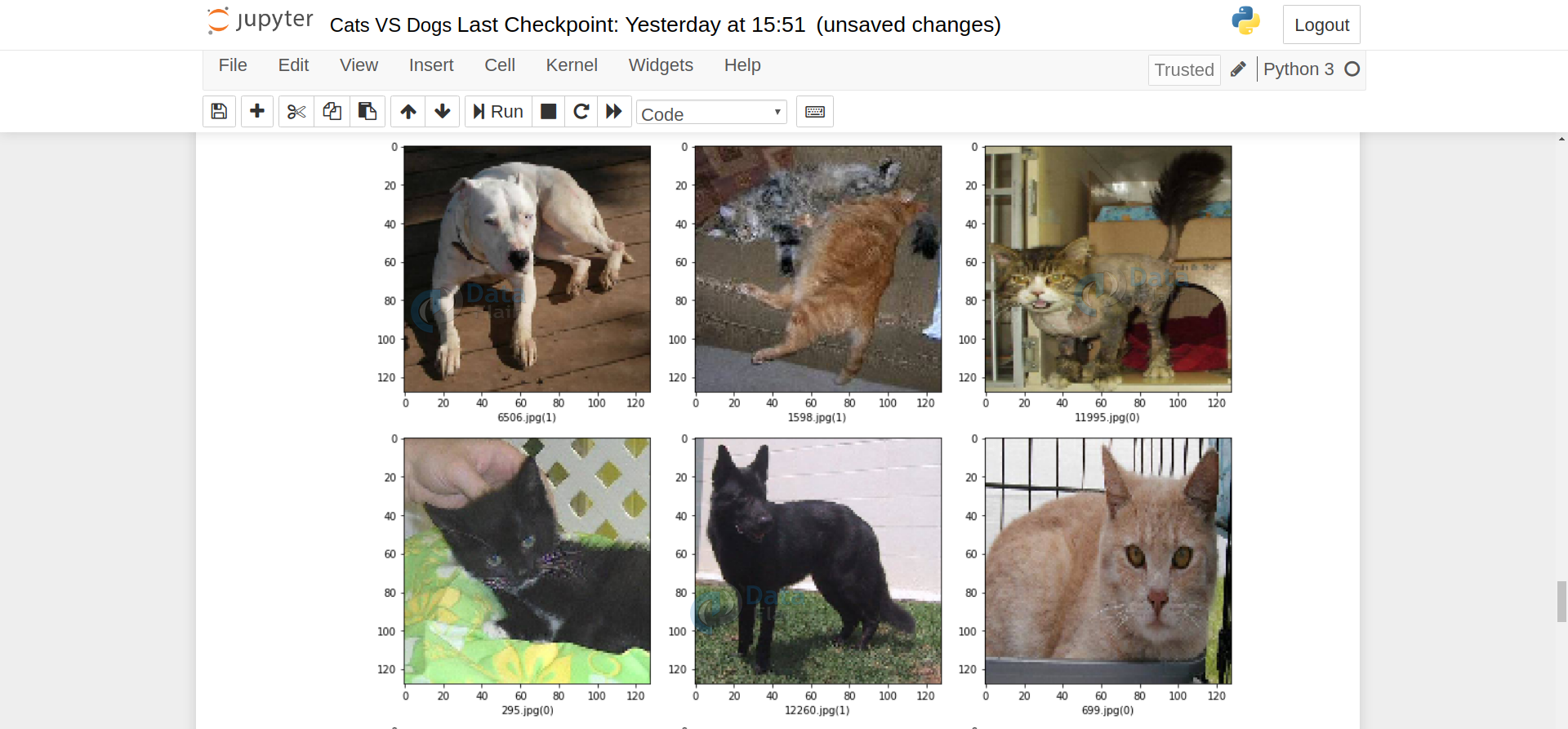
15. Test your model performance on custom data:
results={
0:'cat',
1:'dog'
}
from PIL import Image
import numpy as np
im=Image.open("__image_path_TO_custom_image")
im=im.resize(Image_Size)
im=np.expand_dims(im,axis=0)
im=np.array(im)
im=im/255
pred=model.predict_classes([im])[0]
print(pred,results[pred])Cats VS Dogs Classifier GUI:
We do not want to run predict_classes method every time we want to test our model. That’s why we need a graphical interface. Here we will build the GUI using Tkinter python.
To install Tkinter :
sudo apt-get install python3-tk
Now create a new directory, copy your model (“model1_catsVSdogs_10epoch.h5”) to this directory.
Create a file gui.py and paste the below code:
import tkinter as tk
from tkinter import filedialog
from tkinter import *
from PIL import ImageTk, Image
import numpy
from keras.models import load_model
model = load_model('model1_catsVSdogs_10epoch.h5')
#dictionary to label all traffic signs class.
classes = {
0:'its a cat',
1:'its a dog',
}
#initialise GUI
top=tk.Tk()
top.geometry('800x600')
top.title('CatsVSDogs Classification')
top.configure(background='#CDCDCD')
label=Label(top,background='#CDCDCD', font=('arial',15,'bold'))
sign_image = Label(top)
def classify(file_path):
global label_packed
image = Image.open(file_path)
image = image.resize((128,128))
image = numpy.expand_dims(image, axis=0)
image = numpy.array(image)
image = image/255
pred = model.predict_classes([image])[0]
sign = classes[pred]
print(sign)
label.configure(foreground='#011638', text=sign)
def show_classify_button(file_path):
classify_b=Button(top,text="Classify Image",
command=lambda: classify(file_path),
padx=10,pady=5)
classify_b.configure(background='#364156', foreground='white',
font=('arial',10,'bold'))
classify_b.place(relx=0.79,rely=0.46)
def upload_image():
try:
file_path=filedialog.askopenfilename()
uploaded=Image.open(file_path)
uploaded.thumbnail(((top.winfo_width()/2.25),
(top.winfo_height()/2.25)))
im=ImageTk.PhotoImage(uploaded)
sign_image.configure(image=im)
sign_image.image=im
label.configure(text='')
show_classify_button(file_path)
except:
pass
upload=Button(top,text="Upload an image",command=upload_image,padx=10,pady=5)
upload.configure(background='#364156', foreground='white',font=('arial',10,'bold'))
upload.pack(side=BOTTOM,pady=50)
sign_image.pack(side=BOTTOM,expand=True)
label.pack(side=BOTTOM,expand=True)
heading = Label(top, text="CatsVSDogs Classification",pady=20, font=('arial',20,'bold'))
heading.configure(background='#CDCDCD',foreground='#364156')
heading.pack()
top.mainloop()Save this file and run using:
python3 gui.py
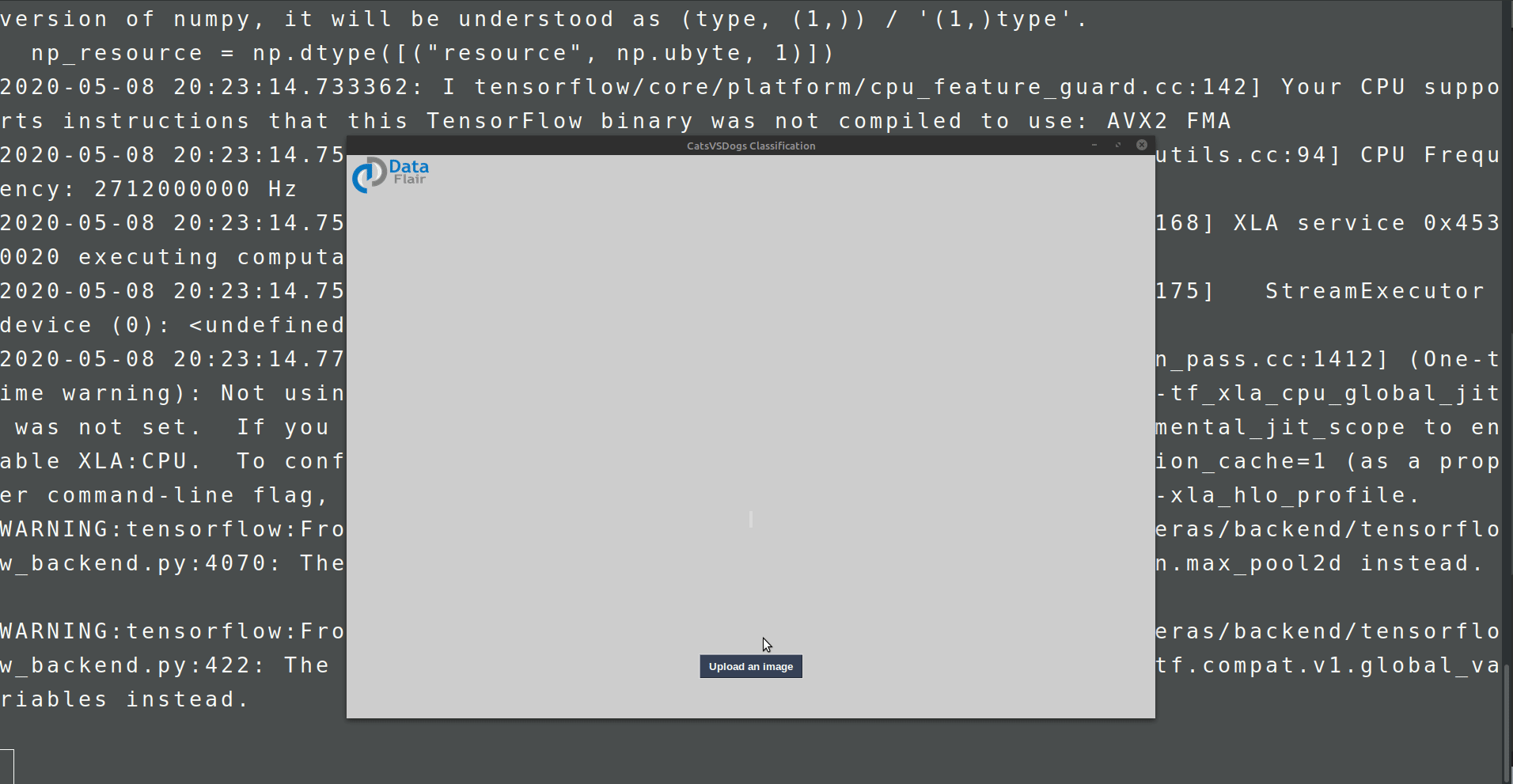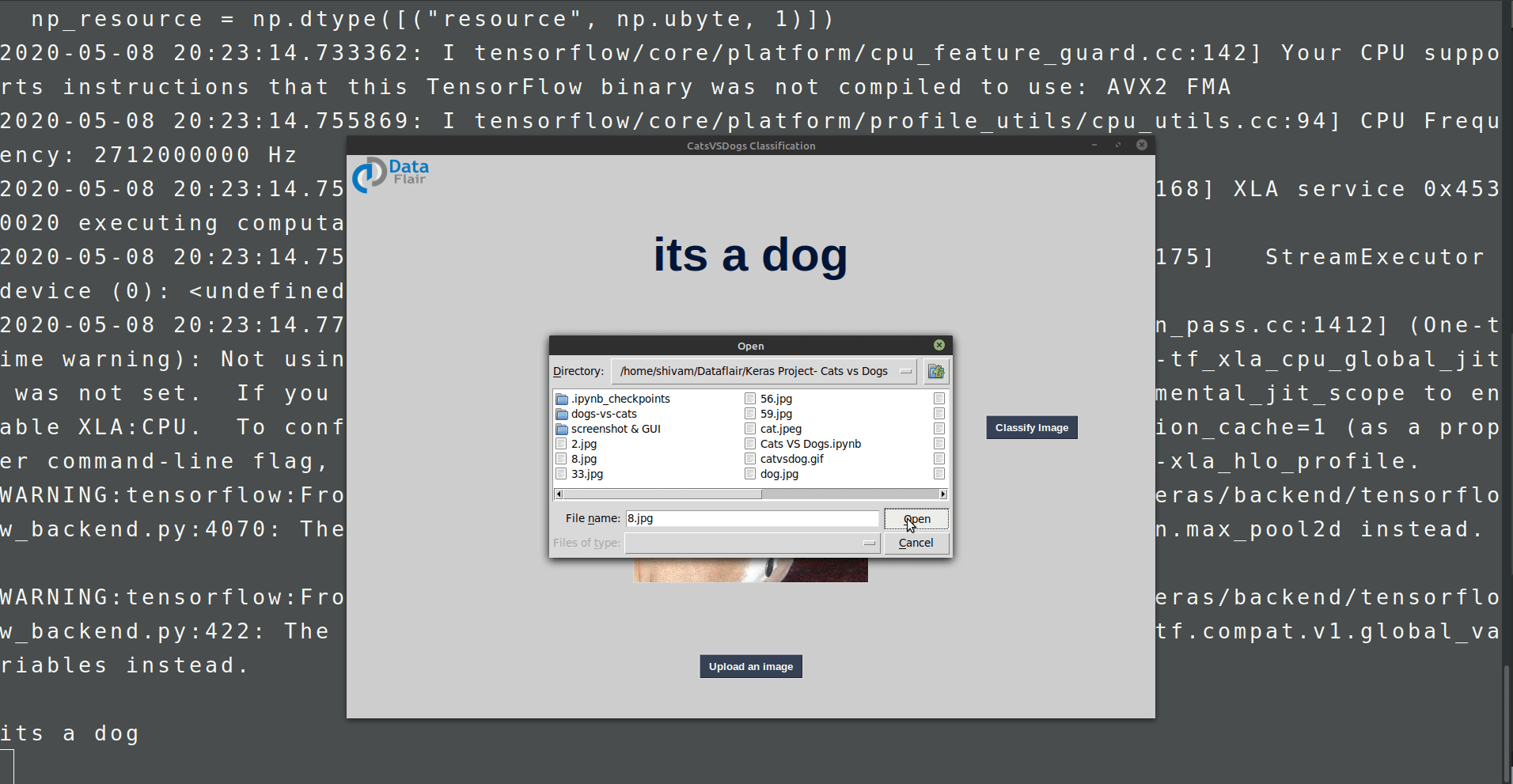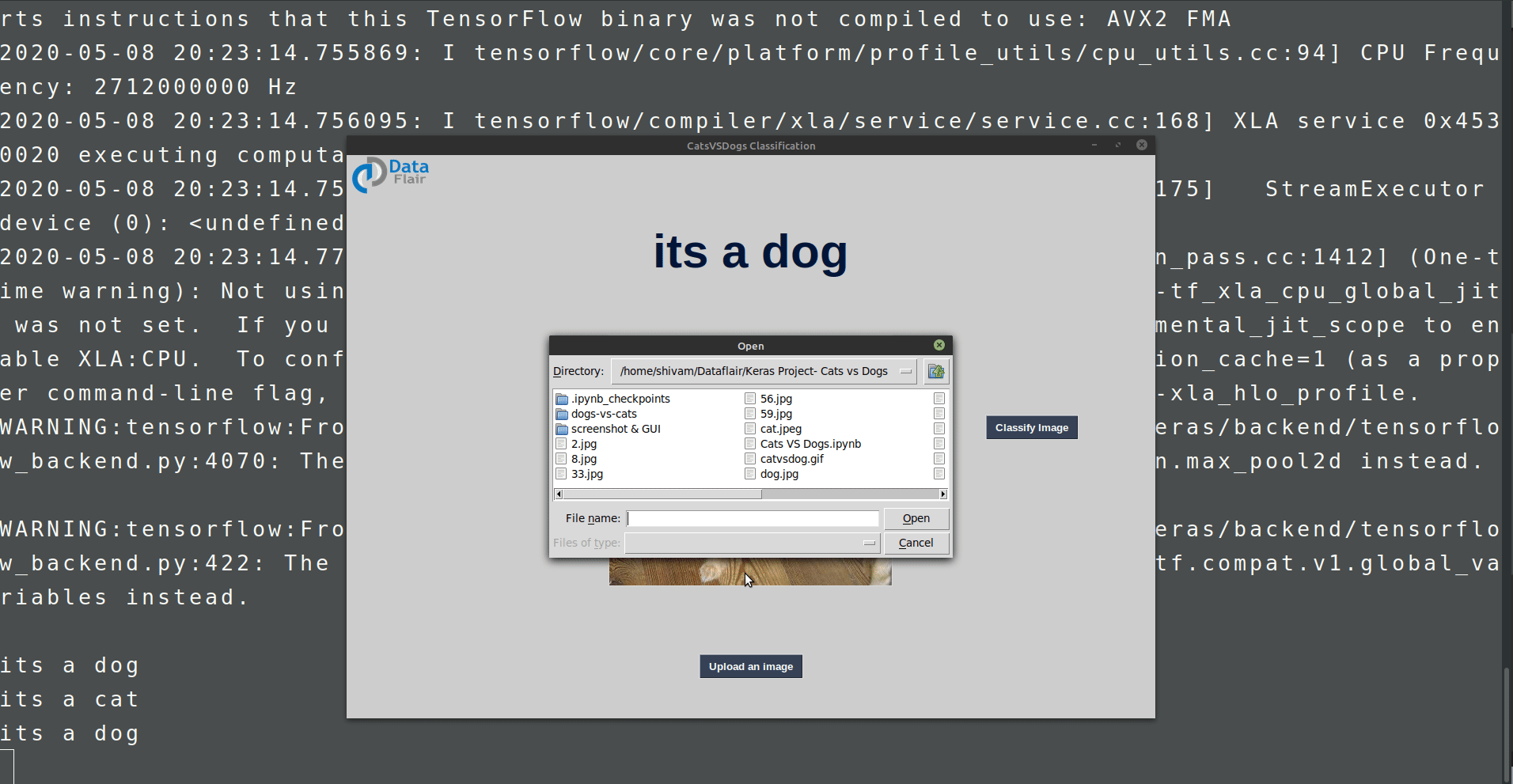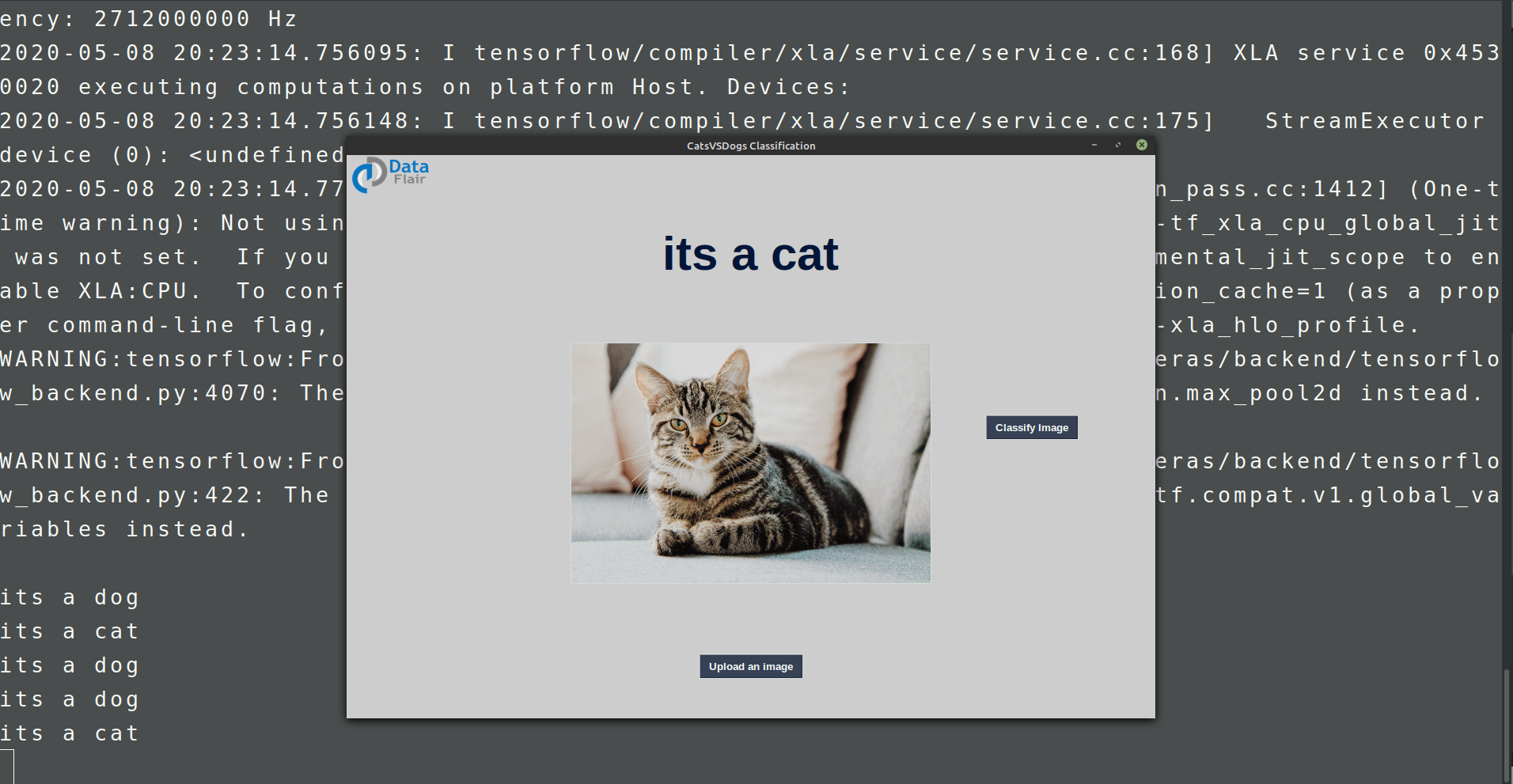
Summary:
This Deep Learning project for beginners introduces you to how to build an image classifier. This project takes The Asirra (catsVSdogs) dataset for training and testing the neural network. In this project, we have learned:
- How to create a neural network in Keras for image classification
- How to prepare the dataset for training and testing
- How to visualize the dataset
- How to save the model
- How to test our model performance on custom data
- How to create a GUI for the execution of deep learning project
What Next?
Now, It’s a good time to deep dive into deep learning: Deep Learning Project – Develop Image Caption Generator with CNN & LSTM.
Did you like this article? If Yes, please give DataFlair 5 Stars on Google





Hi! Thanks a lot)
I have a question in 12
12. Make categorical prediction:
predict = model.predict_generator(test_generator, steps=np.ceil(nb_samples/batch_size))
I think (test_generator) was forgotten to write to the article
I hope you will add
Yes, there is a test_generator Image data generation object in 8.
category=f_name.split(‘.’)[0]
Hi, Thanks for your awesome blog, can you guide about the above line of code?. because i often saw this sometimes with split(‘/’) and what does this [0] actually means? Thanks!
f_name.split(“.”) is used to make partition of the filename string object using “.” as a pivot and it returns a list of substrings. [0] points to the 0th index of the list.
f_name.split(“.”) is used to make partition of the filename string object using “.” as a pivot and it returns a list of substrings. [0] points to the 0th index of the list.
Hi, i have an error can you help me please ?
UserWarning: Found 20000 invalid image filename(s) in x_col=”filename”. These filename(s) will be ignored. .format(n_invalid, x_col)
Found 0 validated image filenames belonging to 0 classes.
same problem, do you have solved it?
hi i have this error :
ValueError: Length of values does not match length of index
can anyone please help
it is at 13. Convert labels to categories: part this error occurs
i really need to solve this error as i have submision project this
It is showing the same error still. Can you help me with this.
Even i have the same error.Please help
Hi, I am getting a train_size error at 7(manage data)
Hi, at 7, i have an error showing
ValueError: With n_samples=1, test_size=0.2 and train_size=0.8, the resulting train set will be empty. Adjust any of the aforementioned parameters.
can you help me?
same problem … Please someone do help!
at 7, i have an error showing
ValueError: With n_samples=1, test_size=0.2 and train_size=0.8, the resulting train set will be empty. Adjust any of the aforementioned parameters.
can you help me?
hey, how much time does this fit takes? we are trying the same code but fit part is improving soooo slowly.
Hi, I noticed that the “test_generator” looks to the “train_df” (item 8). So in item 12, the “predict_generator” is applying “test_generator”. Doesn’t that mean that the model is making predictions using the train dataset? Even though in item 11, the “test_filename” refers to the test dataset.
I also have an error which appears when I run item 12, such that the number of predictions is 5 less than the number of test image files. Any idea what where could have gone wrong?
Hi,
Getting below error after step #12, can you please help.
ValueError Traceback (most recent call last)
in
—-> 1 predict = model.predict_generator(test_generator, steps=np.ceil(nb_samples/batch_size))
~\AppData\Local\Continuum\anaconda3\lib\site-packages\tensorflow\python\keras\engine\training.py in predict_generator(self, generator, steps, callbacks, max_queue_size, workers, use_multiprocessing, verbose)
1913 use_multiprocessing=use_multiprocessing,
1914 verbose=verbose,
-> 1915 callbacks=callbacks)
1916
1917 ######################################################################
~\AppData\Local\Continuum\anaconda3\lib\site-packages\tensorflow\python\keras\engine\training.py in predict(self, x, batch_size, verbose, steps, callbacks, max_queue_size, workers, use_multiprocessing)
1606 use_multiprocessing=use_multiprocessing,
1607 model=self,
-> 1608 steps_per_execution=self._steps_per_execution)
1609
1610 # Container that configures and calls `tf.keras.Callback`s.
~\AppData\Local\Continuum\anaconda3\lib\site-packages\tensorflow\python\keras\engine\data_adapter.py in __init__(self, x, y, sample_weight, batch_size, steps_per_epoch, initial_epoch, epochs, shuffle, class_weight, max_queue_size, workers, use_multiprocessing, model, steps_per_execution)
1110 use_multiprocessing=use_multiprocessing,
1111 distribution_strategy=ds_context.get_strategy(),
-> 1112 model=model)
1113
1114 strategy = ds_context.get_strategy()
~\AppData\Local\Continuum\anaconda3\lib\site-packages\tensorflow\python\keras\engine\data_adapter.py in __init__(self, x, y, sample_weights, shuffle, workers, use_multiprocessing, max_queue_size, model, **kwargs)
907 max_queue_size=max_queue_size,
908 model=model,
–> 909 **kwargs)
910
911 @staticmethod
~\AppData\Local\Continuum\anaconda3\lib\site-packages\tensorflow\python\keras\engine\data_adapter.py in __init__(self, x, y, sample_weights, workers, use_multiprocessing, max_queue_size, model, **kwargs)
777 # Since we have to know the dtype of the python generator when we build the
778 # dataset, we have to look at a batch to infer the structure.
–> 779 peek, x = self._peek_and_restore(x)
780 peek = self._standardize_batch(peek)
781 peek = _process_tensorlike(peek)
~\AppData\Local\Continuum\anaconda3\lib\site-packages\tensorflow\python\keras\engine\data_adapter.py in _peek_and_restore(x)
911 @staticmethod
912 def _peek_and_restore(x):
–> 913 return x[0], x
914
915 def _handle_multiprocessing(self, x, workers, use_multiprocessing,
~\AppData\Local\Continuum\anaconda3\lib\site-packages\keras_preprocessing\image\iterator.py in __getitem__(self, idx)
55 ‘but the Sequence ‘
56 ‘has length {length}’.format(idx=idx,
—> 57 length=len(self)))
58 if self.seed is not None:
59 np.random.seed(self.seed + self.total_batches_seen)
ValueError: Asked to retrieve element 0, but the Sequence has length 0
did you solve the problem ? because I have it too
same problem. Please do help!
I changed test_generator as follows and it functioned properly
test_generator = train_datagen.flow_from_dataframe(test_df,
“./dogs-vs-cats/test1/”,x_col=’filename’,y_col=None,
target_size=Image_Size,
class_mode=None,
batch_size=batch_size
)
Hello, so did you put the 11th statement before the 8th statement, and then continued normally?
Thanks this worked!
hi i have an error at 12:
Make categorical prediction:
predict = model.predict_generator(test_generator, steps=np.ceil(nb_samples/batch_size))
ValueError: Asked to retrieve element 0, but the Sequence has length 0
Anyone know how to fix it?
If you are having issues predicting the test generator (step either is too much or too less because of np.CEIL. I was able to adjust to make it work (I created a validation_batch to avoid round numbers):
# Step 8
TEST_BATCH = 20 (any number that will be divided by 12.500 test pictures in order to avoid round numbers)
test_generator = train_datagen.flow_from_dataframe(train_df,
“./dogs-vs-cats/test/”,x_col=’filename’,y_col=’category’,
target_size=Image_Size,
class_mode=’categorical’,
batch_size= TEST_BATCH)
# Step 12
predict = model.predict_generator(test_generator, steps=np.ceil(nb_samples/TEST_BATCH))
ValueError: Asked to retrieve element 0, but the Sequence has length 0
same problem, @author please help us
ValueError: Length of values (12510) does not match length of index (12500) can anyone help me
Did u rectify this error?
I need a complete ptoject which is : Vulnerability detection for selfie images using graph neural network
ValueError: With n_samples=1, test_size=0.2 and train_size=0.8, the resulting train set will be empty. Adjust any of the aforementioned parameters.
model is not performing as well as 98% accuracy rate, it doesn’t even pass 90% on train or val sets.
I run the exact code from this page on the same data, any idea why I’m not getting the same results?
Hi!
I don’t know if you solved it. I obtain results about the 87% so if you want to see my code I can invite you to my github group.
In the other hand, I has been watching that in step 14 the visualization of the prediction results are also wrong because I obtain a lot of “0” values when I have a dog. ¿Any idea?
The same here, I can barely make 85% using this model. I can’t believe, this model has achieved 98%.
I am wondering why author has used only 3 conv layers, because there is still big layer 14×14 before Flatten. I also don’t understand why didn’t he use GlobalAveragePooling2D instead Flatten.
I achieved 94% on validation data by adding additional conv layers (with and without maxpooling by turns)
Hello, Could you please share your code? I really need your help, thankyou very much!
Can anyone help me with this error?
predict = model.predict(test_generator, steps=np.ceil(nb_samples/batch_size))
—————————————————————————
ValueError Traceback (most recent call last)
C:\Users\MARCEL~1\AppData\Local\Temp/ipykernel_46316/1081390916.py in
—-> 1 predict = model.predict(test_generator, steps=np.ceil(nb_samples/batch_size))
C:\Anaconda\lib\site-packages\keras\utils\traceback_utils.py in error_handler(*args, **kwargs)
65 except Exception as e: # pylint: disable=broad-except
66 filtered_tb = _process_traceback_frames(e.__traceback__)
—> 67 raise e.with_traceback(filtered_tb) from None
68 finally:
69 del filtered_tb
C:\Anaconda\lib\site-packages\keras_preprocessing\image\iterator.py in __getitem__(self, idx)
52 def __getitem__(self, idx):
53 if idx >= len(self):
—> 54 raise ValueError(‘Asked to retrieve element {idx}, ‘
55 ‘but the Sequence ‘
56 ‘has length {length}’.format(idx=idx,
ValueError: Asked to retrieve element 0, but the Sequence has length 0
Hi!
I don’t know if you solved it. I obtain results about the 87% so if you want to see my code I can invite you to my github group.
In the other hand, I has been watching that in step 14 the visualization of the prediction results are also wrong because I obtain a lot of “0” values when I have a dog. ¿Any idea?
The same, I can barely make 85% using this model. I can’t believe, this model has achieved 98%.
I am wondering why author has used only 3 conv layers, because there is still big layer 14×14 before Flatten. I also don’t understand why didn’t he use GlobalAveragePooling2D instead Flatten.
I achieved 94% on validation data by adding additional conv layers (with and without maxpooling by turns)
Hi Ticzek, do you have code for this anywhere? I’d be interested in seeing it as I’m having the same problem with this model. What do you mean by maxpooling by turns?
I succeed with training the model and saving to the .h5 file… when i run the GUI i get this error
pred = model.predict_classes([image])[0]
AttributeError: ‘Sequential’ object has no attribute ‘predict_classes’
Hello, I have a question in 12.
12. Make categorical prediction:
predict = model.predict_generator(test_generator, steps=np.ceil(nb_samples/batch_size))
I get an error when running it:
“NameError Traceback (most recent call last)
Cell In [4], line 1
—-> 1 predict = model.predict_generator(test_generator, steps=np.ceil(nb_samples/batch_size))
NameError: name ‘model’ is not defined”
How can I solve that?
Hello,
I’ve tried a lot of things including the suggestions from Keerthi here, but I’m not able to fix the error in Predict. I still keep getting “ValueError: Asked to retrieve element 0, but the Sequence has length 0”
Any help will be appreciated. Thanks in advance.
Govindan
Hello,
I went through each section carefully and figured out the issue and I was able to move forward. Explaining my finding below. Please correct me if I’m wrong. There were multiple corrections needed. The problem was that, the test_df was never being used in predict, so it was not finding any data and hence the error.
Section 8 defines the test_generator and test_datagen – this is not correct.
Create the test_df as mentioned, then use the test_df in test_datagen – that will solve the issue.
Also, note that the y_col should be None for test_datagen, because there is no category in the test data.
test_filenames = os.listdir(“”)
test_df = pd.DataFrame({
‘filename’: test_filenames
})
nb_samples = test_df.shape[0]
test_datagen = ImageDataGenerator(rotation_range=15,
rescale=1./255,
shear_range=0.1,
zoom_range=0.2,
horizontal_flip=True,
width_shift_range=0.1,
height_shift_range=0.1)
test_generator = test_datagen.flow_from_dataframe(test_df,
“”,x_col=’filename’,y_col=None,
target_size=Image_Size,
class_mode=None,
batch_size=batch_size)
#Note that I’ve used test_df in the test_generator
class_mode is None as well.
None type error generating at test_generator
same problem, have you solved it?
There is no ./dogs-vs-cats/test/ file in zip