Kafka Hadoop Integration | Integrating Hadoop with Kafka
Kafka course with real-time projects Start Now!!
Today, in this Kafka Hadoop Tutorial, we will discuss Kafka Hadoop Integration. Moreover, we will start this tutorial with Hadoop Introduction. Also, we will see Hadoop Producer and Hadoop Consumer in Kafka Integration with Hadoop.
Basically, we can integrate Kafka with the Hadoop technology in order to address different use cases, such as batch processing using Hadoop.
So, in this article, “Kafka Hadoop integration” we will learn the procedure to integrate Hadoop with Kafka in an easier and efficient way. However, before integrating Kafka with Hadoop, it is important to learn the brief introduction of Hadoop.
So, let’s start Kafka Hadoop Integration.
What is Hadoop?
A large-scale distributed batch processing framework that use to parallelize the data processing among many nodes and also addresses the challenges for distributed computing, including big data, is what we call Hadoop.
Basically, it works on the principle of the MapReduce framework which is introduced by Google. It offers a simple interface for the parallelization as well as the distribution of large-scale computations.
In addition, it has its own distributed data filesystem which we call as HDFS (Hadoop Distributed File System). To understand HDFS, it splits the data into small pieces (called blocks) and further distributes it to all the nodes in any typical Hadoop cluster.
Moreover, it creates the replication of these small pieces of data as well as it stores them to ensure that the data is available from another node if any node is down.
Now, here is an image showing the high-level view of a multi-node Hadoop cluster:
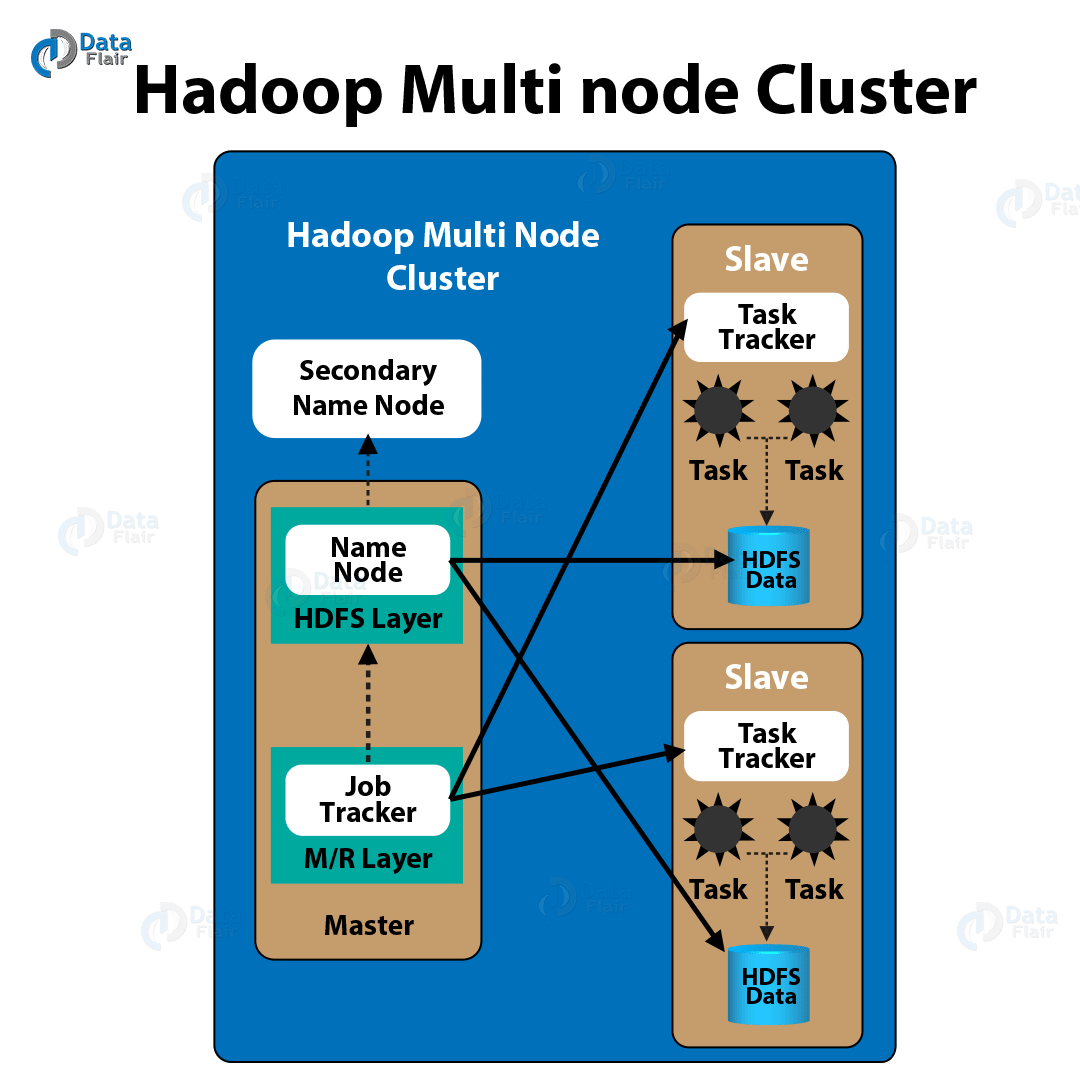
Hadoop Multinode Cluster
a. Main Components of Hadoop
Following are the Hadoop Components:
- Name Node
A single point of interaction for HDFS is what we call Namenode. As its job, it keeps the information about the small pieces (blocks) of data which are distributed among node.
- Secondary Namenode
In case of a name node failure, it stores the edit logs, to restore the latest updated state of HDFS.
- Data Node
It keeps the actual data which is distributed by the namenode in blocks as well as keeps the replicated copy of data from other nodes.
- Job Tracker
In order to split the MapReduce jobs into smaller tasks, Job Tracker helps.
- Task Tracker
Whereas, for the execution of tasks split by the job tracker, the task tracker is responsible.
Although, make sure that the task tracker and the data nodes share the same machines.
Kafka Hadoop Integration
In order to build a pipeline which is available for real-time processing or monitoring as well as to load the data into Hadoop, NoSQL, or data warehousing systems for offline processing and reporting, especially for real-time publish-subscribe use cases, we use Kafka.
a. Hadoop producer
In order to publish the data from a Hadoop Cluster to Kafka, a Hadoop producer offers a bridge you can see in the below image:
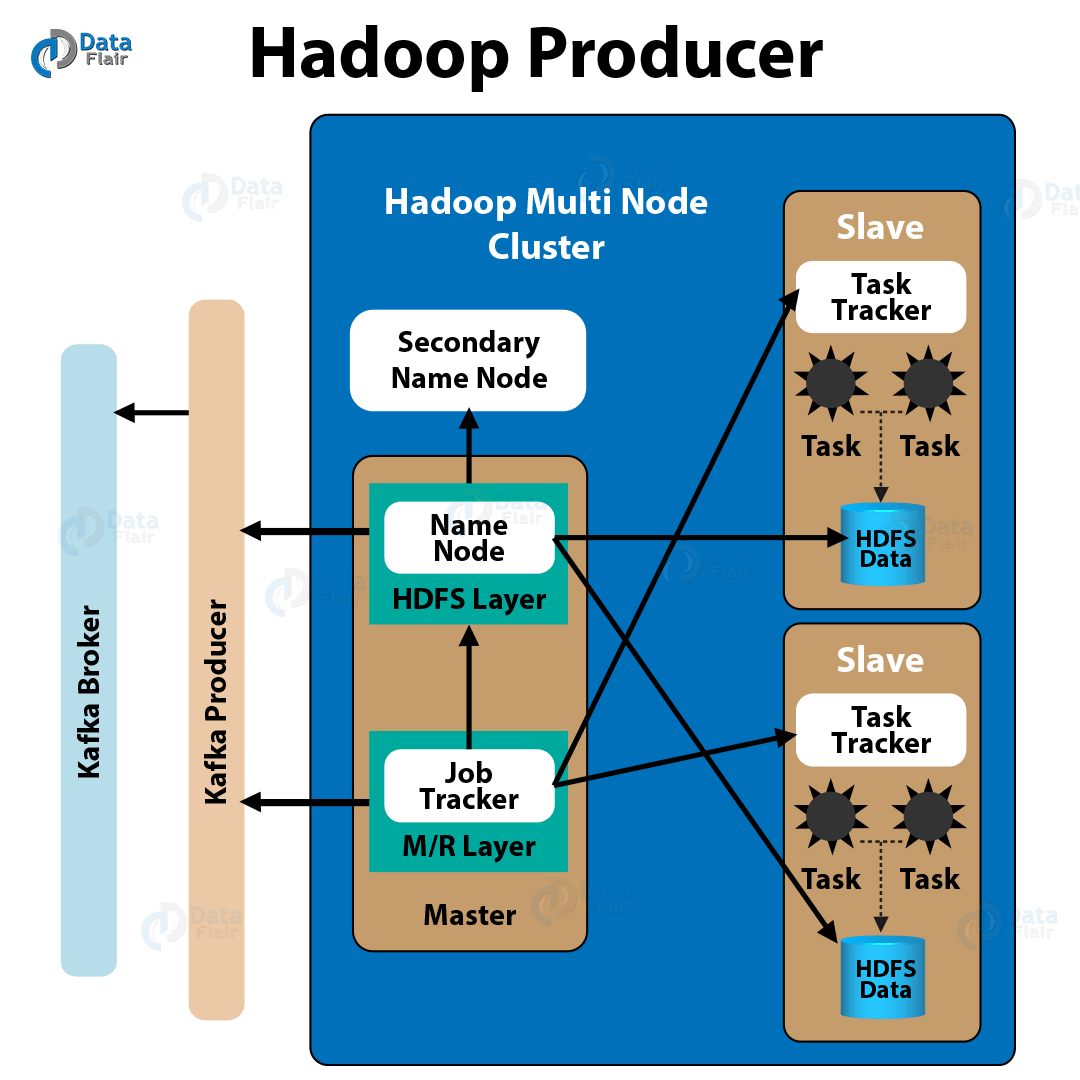
Moreover, Kafka topics are considered as URIs, for a Kafka producer. Though, URIs are specified below, to connect to a specific Kafka broker:
kafka://<kafka-broker>/<kafka-topic>
Well, for getting the data from Hadoop, the Hadoop producer code suggests two possible approaches, they are:
- Using the Pig script and writing messages in Avro format
Basically, for writing data in a binary Avro format, Kafka producers use Pig scripts, in this approach. Here each row refers to a single message.
Further, the AvroKafkaStorage class picks the Avro schema as its first argument and then connects to the Kafka URI, in order to push the data into the Kafka cluster. Moreover, we can easily write to multiple topics and brokers in the same Pig script-based job, by using the AvroKafkaStorage producer.
- Using the Kafka OutputFormat class for jobs
Now, in the second method, for publishing data to the Kafka cluster, the Kafka OutputFormat class (extends Hadoop’s OutputFormat class) is used. Here, by using low-level methods of publishing, it publishes messages as bytes and also offers control over the output.
Although, for writing a record (message) to a Hadoop cluster, the Kafka OutputFormat class uses the KafkaRecordWriter class.
In addition, we can also configure Kafka Producer parameters and Kafka Broker information under a job’s configuration, for Kafka Producers.
b. Hadoop Consumer
Whereas, a Hadoop job which pulls data from the Kafka broker and further pushes it into HDFS, is what we call a Hadoop consumer. Though, from below image, you can see the position of a Kafka Consumer in the architecture pattern:
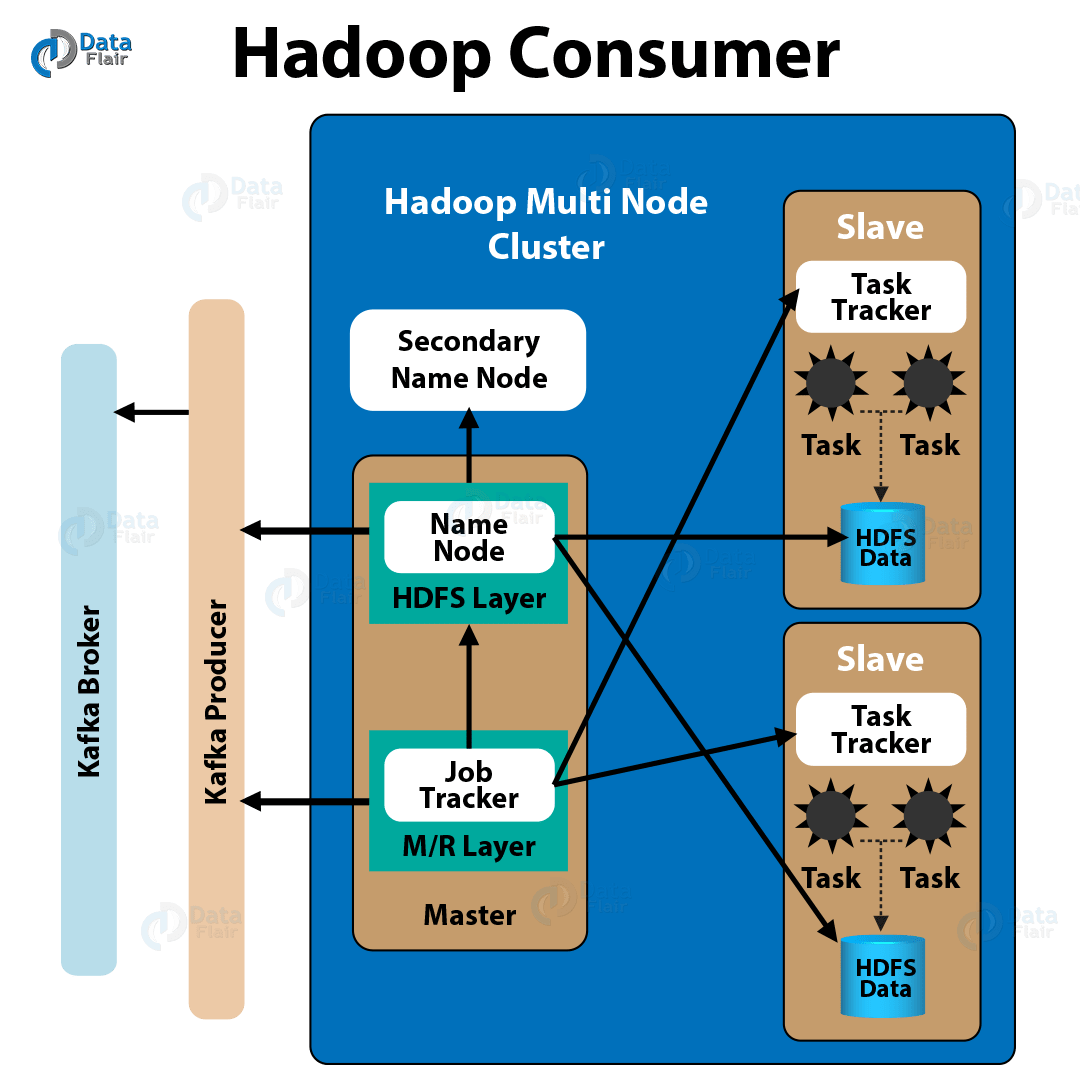
Kafka Hadoop integration – Hadoop Consumer
As a process, a Hadoop job does perform parallel loading from Kafka to HDFS also some mappers for purpose of loading the data which depends on the number of files in the input directory. Moreover, data coming from Kafka and the updated topic offsets is in the output directory.
Further, at the end of the map task, individual mappers write the offset of the last consumed message to HDFS. Though, each mapper simply restarts from the offsets stored in HDFS, if a job fails and jobs get restarted.
So, this was all in Kafka Hadoop Integration. Hope you like our explanation.
Conclusion: Kafka Hadoop integration
Hence, we have seen whole about Kafka Hadoop integration in detail. Hope it helps!. Furthermore, if you feel any difficulty while learning Kafka Hadoop Integration, feel free to ask in the comment tab.
If you are Happy with DataFlair, do not forget to make us happy with your positive feedback on Google





Can I scale it for 2 billion requests for server.