Hadoop Tutorial for Big Data Enthusiasts – The Optimal way of Learning Hadoop
Hadoop Tutorial – One of the most searched terms on the internet today. Do you know the reason? It is because Hadoop is the major part or framework of Big Data.
If you don’t know anything about Big Data then you are in major trouble. But don’t worry I have something for you which is completely FREE – 520+ Big Data Tutorials. This free tutorial series will make you a master of Big Data in just few weeks. Also, I have explained a little about Big Data in this blog.
“Hadoop is a technology to store massive datasets on a cluster of cheap machines in a distributed manner”. It was originated by Doug Cutting and Mike Cafarella.
Doug Cutting’s kid named Hadoop to one of his toy that was a yellow elephant. Doug then used the name for his open source project because it was easy to spell, pronounce, and not used elsewhere.
Interesting, right?
Hadoop Tutorial
Now, let’s begin our interesting Hadoop tutorial with the basic introduction to Big Data.
What is Big Data?
Big Data refers to the datasets too large and complex for traditional systems to store and process. The major problems faced by Big Data majorly falls under three Vs. They are volume, velocity, and variety.
Do you know – Every minute we send 204 million emails, generate 1.8 million Facebook likes, send 278 thousand Tweets, and up-load 200,000 photos to Facebook.
Volume: The data is getting generated in order of Tera to petabytes. The largest contributor of data is social media. For instance, Facebook generates 500 TB of data every day. Twitter generates 8TB of data daily.
Velocity: Every enterprise has its own requirement of the time frame within which they have process data. Many use cases like credit card fraud detection have only a few seconds to process the data in real-time and detect fraud. Hence there is a need of framework which is capable of high-speed data computations.
Variety: Also the data from various sources have varied formats like text, XML, images, audio, video, etc. Hence the Big Data technology should have the capability of performing analytics on a variety of data.

Hope you have checked the Free Big Data DataFlair Tutorial Series. Here is one more interesting article for you – Top Big Data Quotes by the Experts
Why Hadoop is Invented?
Let us discuss the shortcomings of the traditional approach which led to the invention of Hadoop –
1. Storage for Large Datasets
The conventional RDBMS is incapable of storing huge amounts of Data. The cost of data storage in available RDBMS is very high. As it incurs the cost of hardware and software both.
2. Handling data in different formats
The RDBMS is capable of storing and manipulating data in a structured format. But in the real world we have to deal with data in a structured, unstructured and semi-structured format.
3. Data getting generated with high speed:
The data in oozing out in the order of tera to peta bytes daily. Hence we need a system to process data in real-time within a few seconds. The traditional RDBMS fail to provide real-time processing at great speeds.
What is Hadoop?
Hadoop is the solution to above Big Data problems. It is the technology to store massive datasets on a cluster of cheap machines in a distributed manner. Not only this it provides Big Data analytics through distributed computing framework.
It is an open-source software developed as a project by Apache Software Foundation. Doug Cutting created Hadoop. In the year 2008 Yahoo gave Hadoop to Apache Software Foundation. Since then two versions of Hadoop has come. Version 1.0 in the year 2011 and version 2.0.6 in the year 2013. Hadoop comes in various flavors like Cloudera, IBM BigInsight, MapR and Hortonworks.
Prerequisites to Learn Hadoop
1. Familiarity with some basic Linux Command – Hadoop is set up over Linux Operating System preferable Ubuntu. So one must know certain basic Linux commands. These commands are for uploading the file in HDFS, downloading the file from HDFS and so on.
2. Basic Java concepts – Folks want to learn Hadoop can get started in Hadoop while simultaneously grasping basic concepts of Java. We can write map and reduce functions in Hadoop using other languages too. And these are Python, Perl, C, Ruby, etc. This is possible via streaming API. It supports reading from standard input and writing to standard output. Hadoop also has high-level abstractions tools like Pig and Hive which do not require familiarity with Java.
Big Data Hadoop Tutorial Video
Wait! understand the concepts of Hadoop through this awesome video –
Hope the above Big Data Hadoop Tutorial video helped you. Let us see further.
Hadoop consists of three core components –
- Hadoop Distributed File System (HDFS) – It is the storage layer of Hadoop.
- Map-Reduce – It is the data processing layer of Hadoop.
- YARN – It is the resource management layer of Hadoop.
Core Components of Hadoop
Let us understand these Hadoop components in detail.
1. HDFS
Short for Hadoop Distributed File System provides for distributed storage for Hadoop. HDFS has a master-slave topology.
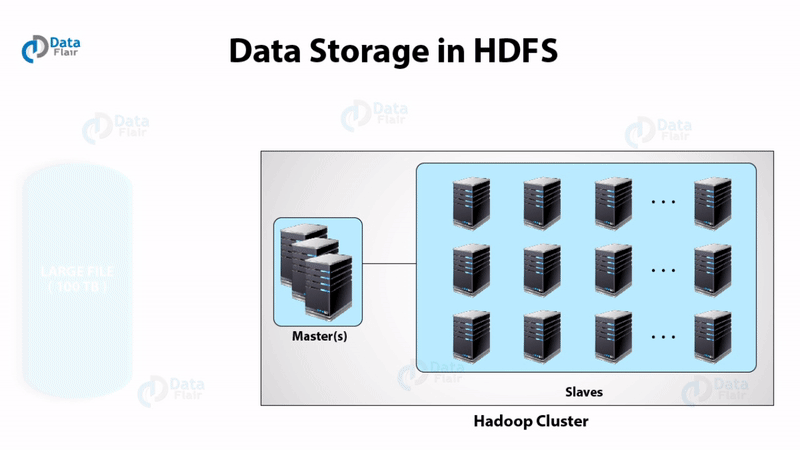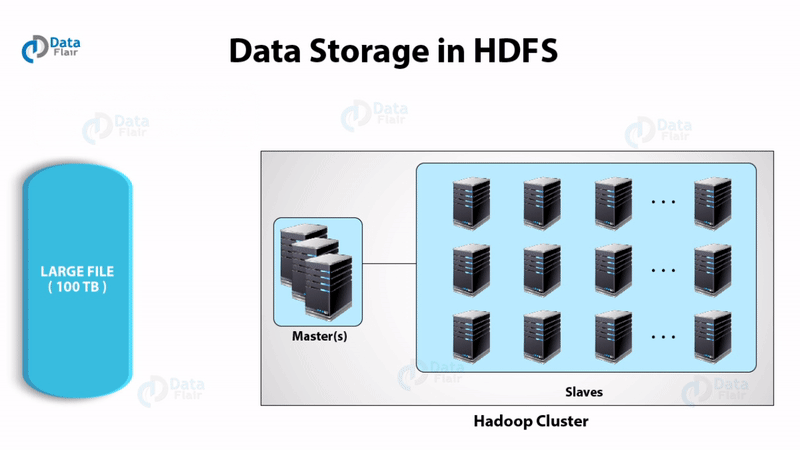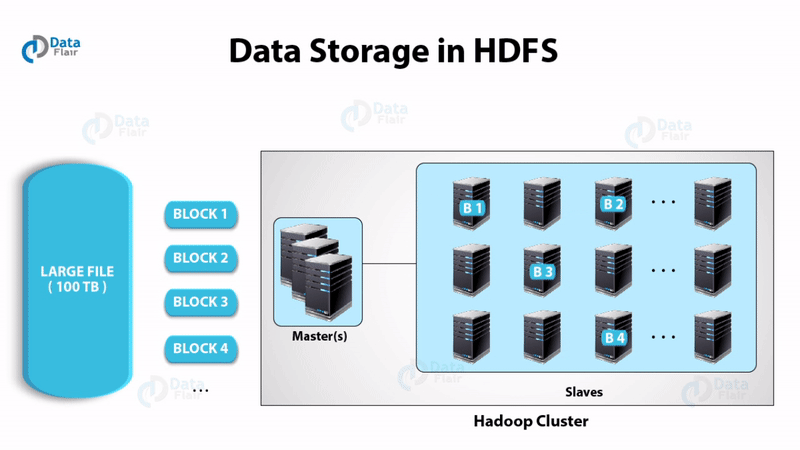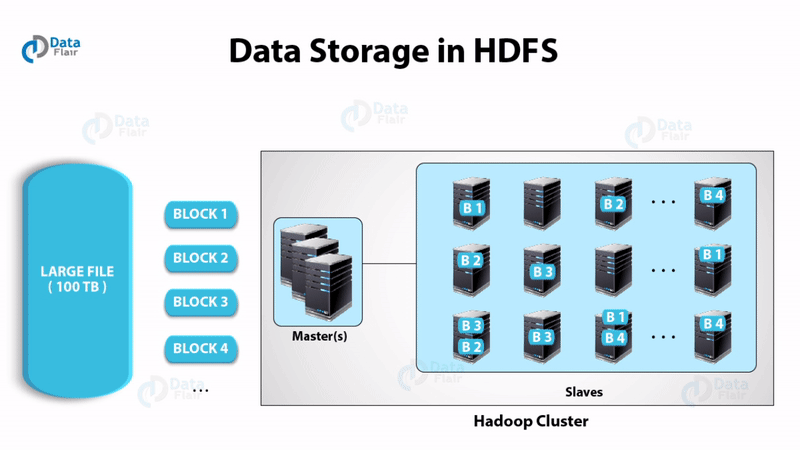
Master is a high-end machine where as slaves are inexpensive computers. The Big Data files get divided into the number of blocks. Hadoop stores these blocks in a distributed fashion on the cluster of slave nodes. On the master, we have metadata stored.
HDFS has two daemons running for it. They are :
NameNode : NameNode performs following functions –
- NameNode Daemon runs on the master machine.
- It is responsible for maintaining, monitoring and managing DataNodes.
- It records the metadata of the files like the location of blocks, file size, permission, hierarchy etc.
- Namenode captures all the changes to the metadata like deletion, creation and renaming of the file in edit logs.
- It regularly receives heartbeat and block reports from the DataNodes.
DataNode: The various functions of DataNode are as follows –
- DataNode runs on the slave machine.
- It stores the actual business data.
- It serves the read-write request from the user.
- DataNode does the ground work of creating, replicating and deleting the blocks on the command of NameNode.
- After every 3 seconds, by default, it sends heartbeat to NameNode reporting the health of HDFS.
Explore the top features of HDFS that a Hadoop developer must know
Erasure Coding in HDFS
Till Hadoop 2.x replication is the only method for providing fault tolerance. Hadoop 3.0 introduces one more method called erasure coding. Erasure coding provides the same level of fault tolerance but with lower storage overhead.
Erasure coding is usually used in RAID (Redundant Array of Inexpensive Disks) kind of storage. RAID provides erasure coding via striping. In this, it divides the data into smaller units like bit/byte/block and stores the consecutive units on different disks. Hadoop calculates parity bits for each of these cell (units). We call this process as encoding. On the event of loss of certain cells, Hadoop computes these by decoding. Decoding is a process in which lost cells gets recovered from remaining original and parity cells.
Erasure coding is mostly used for warm or cold data which undergo less frequent I/O access. The replication factor of Erasure coded file is always one. we cannot change it by -setrep command. Under erasure coding storage overhead is never more than 50%.
Under conventional Hadoop storage replication factor of 3 is default. It means 6 blocks will get replicated into 6*3 i.e. 18 blocks. This gives a storage overhead of 200%. As opposed to this in Erasure coding technique there are 6 data blocks and 3 parity blocks. This gives storage overhead of 50%.
The File System Namespace
HDFS supports hierarchical file organization. One can create, remove, move or rename a file. NameNode maintains file system Namespace. NameNode records the changes in the Namespace. It also stores the replication factor of the file.
2. MapReduce
It is the data processing layer of Hadoop. It processes data in two phases.
They are:-
Map Phase- This phase applies business logic to the data. The input data gets converted into key-value pairs.
Reduce Phase- The Reduce phase takes as input the output of Map Phase. It applies aggregation based on the key of the key-value pairs.
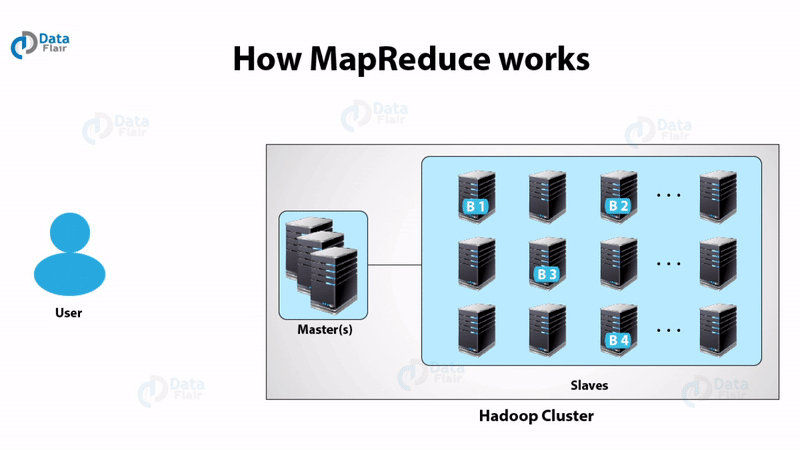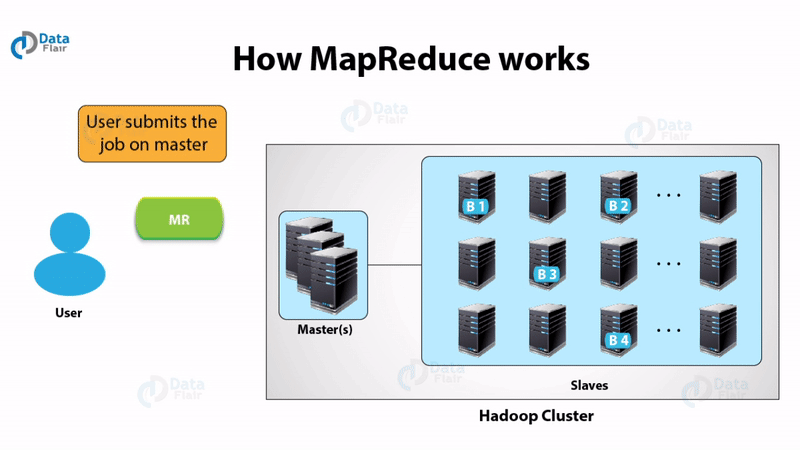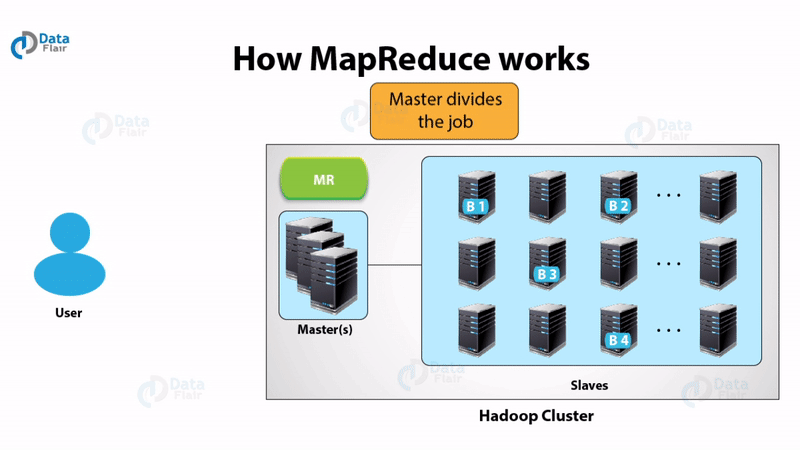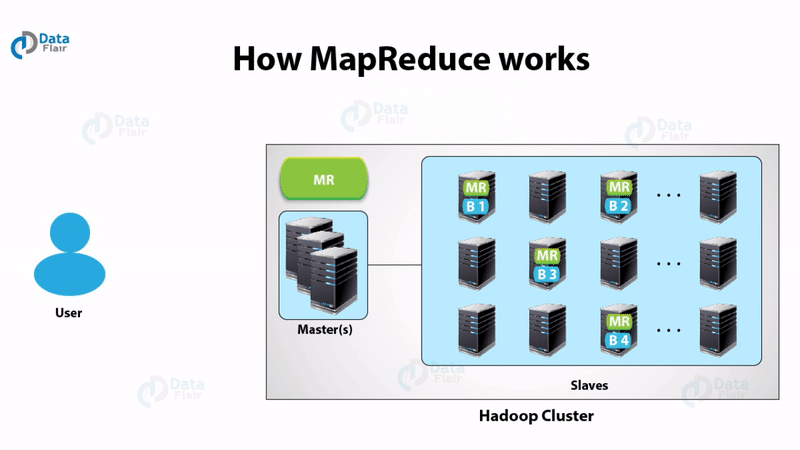
You must check this MapReduce tutorial to start your learning.
Map-Reduce works in the following way:
- The client specifies the file for input to the Map function. It splits it into tuples
- Map function defines key and value from the input file. The output of the map function is this key-value pair.
- MapReduce framework sorts the key-value pair from map function.
- The framework merges the tuples having the same key together.
- The reducers get these merged key-value pairs as input.
- Reducer applies aggregate functions on key-value pair.
- The output from the reducer gets written to HDFS.
3. YARN
Short for Yet Another Resource Locator has the following components:-
Resource Manager
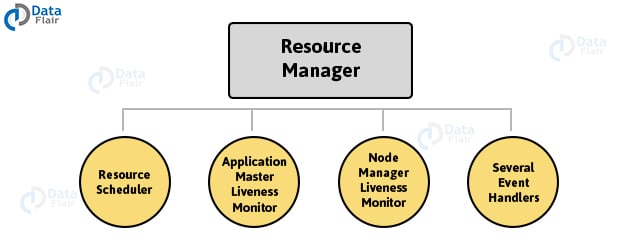
- Resource Manager runs on the master node.
- It knows where the location of slaves (Rack Awareness).
- It is aware about how much resources each slave have.
- Resource Scheduler is one of the important service run by the Resource Manager.
- Resource Scheduler decides how the resources get assigned to various tasks.
- Application Manager is one more service run by Resource Manager.
- Application Manager negotiates the first container for an application.
- Resource Manager keeps track of the heart beats from the Node Manager.
Node Manager
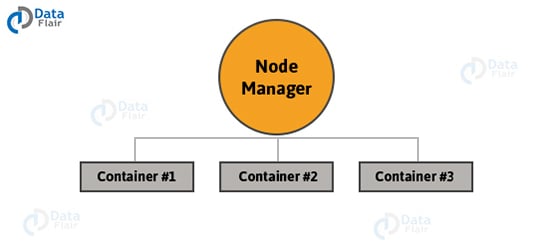
- It runs on slave machines.
- It manages containers. Containers are nothing but a fraction of Node Manager’s resource capacity
- Node manager monitors resource utilization of each container.
- It sends heartbeat to Resource Manager.
Job Submitter
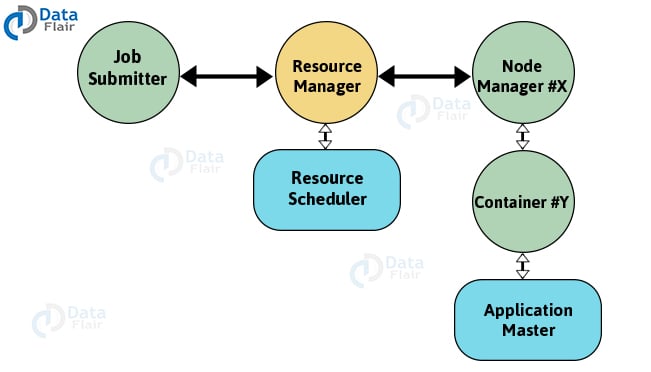
The application startup process is as follows:-
- The client submits the job to Resource Manager.
- Resource Manager contacts Resource Scheduler and allocates container.
- Now Resource Manager contacts the relevant Node Manager to launch the container.
- Container runs Application Master.
The basic idea of YARN was to split the task of resource management and job scheduling. It has one global Resource Manager and per-application Application Master. An application can be either one job or DAG of jobs.
The Resource Manager’s job is to assign resources to various competing applications. Node Manager runs on the slave nodes. It is responsible for containers, monitoring resource utilization and informing about the same to Resource Manager.
The job of Application master is to negotiate resources from the Resource Manager. It also works with NodeManager to execute and monitor the tasks.
Wait before scrolling further! This is the time to read about the top 15 Hadoop Ecosystem components.
Why Hadoop?
Let us now understand why Big Data Hadoop is very popular, why Apache Hadoop capture more than 90% of the big data market.
Apache Hadoop is not only a storage system but is a platform for data storage as well as processing. It is scalable (as we can add more nodes on the fly), Fault-tolerant (Even if nodes go down, data processed by another node).
Following characteristics of Hadoop make it a unique platform:
1. Flexibility to store and mine any type of data whether it is structured, semi-structured or unstructured. It is not bounded by a single schema.
2. Excels at processing data of complex nature. Its scale-out architecture divides workloads across many nodes. Another added advantage is that its flexible file-system eliminates ETL bottlenecks.
3. Scales economically, as discussed it can deploy on commodity hardware. Apart from this its open-source nature guards against vendor lock.
What is Hadoop Architecture?
After understanding what is Apache Hadoop, let us now understand the Hadoop Architecture in detail.

How Hadoop Works
Hadoop works in master-slave fashion. There is a master node and there are n numbers of slave nodes where n can be 1000s. Master manages, maintains and monitors the slaves while slaves are the actual worker nodes. In Hadoop architecture, the Master should deploy on good configuration hardware, not just commodity hardware. As it is the centerpiece of Hadoop cluster.
Master stores the metadata (data about data) while slaves are the nodes which store the data. Distributedly data stores in the cluster. The client connects with the master node to perform any task. Now in this Hadoop tutorial for beginners, we will discuss different features of Hadoop in detail.
Hadoop Features
Here are the top Hadoop features that make it popular –
1. Reliability
In the Hadoop cluster, if any node goes down, it will not disable the whole cluster. Instead, another node will take the place of the failed node. Hadoop cluster will continue functioning as nothing has happened. Hadoop has built-in fault tolerance feature.
2. Scalable
Hadoop gets integrated with cloud-based service. If you are installing Hadoop on the cloud you need not worry about scalability. You can easily procure more hardware and expand your Hadoop cluster within minutes.
3. Economical
Hadoop gets deployed on commodity hardware which is cheap machines. This makes Hadoop very economical. Also as Hadoop is an open system software there is no cost of license too.
4. Distributed Processing
In Hadoop, any job submitted by the client gets divided into the number of sub-tasks. These sub-tasks are independent of each other. Hence they execute in parallel giving high throughput.
5. Distributed Storage
Hadoop splits each file into the number of blocks. These blocks get stored distributedly on the cluster of machines.
6. Fault Tolerance
Hadoop replicates every block of file many times depending on the replication factor. Replication factor is 3 by default. In Hadoop suppose any node goes down then the data on that node gets recovered. This is because this copy of the data would be available on other nodes due to replication. Hadoop is fault tolerant.
Are you looking for more Features? Here are the additional Hadoop Features that make it special.
Hadoop Flavors
This section of the Hadoop Tutorial talks about the various flavors of Hadoop.
- Apache – Vanilla flavor, as the actual code is residing in Apache repositories.
- Hortonworks – Popular distribution in the industry. This provides a robust and reliable Hadoop platform with enterprise-grade features.
- Cloudera – It is the most popular in the industry.
- MapR – It has rewritten HDFS and its HDFS is faster as compared to others.
- IBM – Proprietary distribution is known as Big Insights. This integrates with different IBM products and services, hence providing a complete big data solution.
All the databases have provided native connectivity with Hadoop for fast data transfer. Because, to transfer data from Oracle to Hadoop, you need a connector.
All flavors are almost same and if you know one, you can easily work on other flavors as well.
Hadoop Future Scope
There is going to be a lot of investment in the Big Data industry in coming years. According to a report by FORBES, 90% of global organizations will be investing in Big Data technology. Hence the demand for Hadoop resources will also grow. Learning Apache Hadoop will give you accelerated growth in career. It also tends to increase your pay package.
There is a lot of gap between the supply and demand of Big Data professional. The skill in Big Data technologies continues to be in high demand. This is because companies grow as they try to get the most out of their data. Therefore, their salary package is quite high as compared to professionals in other technology.
The managing director of Dice, Alice Hills has said that Hadoop jobs have seen 64% increase from the previous year. It is evident that Hadoop is ruling the Big Data market and its future is bright. The demand for Big Data Analytics professional is ever increasing. As it is a known fact that data is nothing without power to analyze it.
You must check Expert’s Prediction for the Future of Hadoop
Summary – Hadoop Tutorial
On concluding this Hadoop tutorial, we can say that Apache Hadoop is the most popular and powerful big data tool. Big Data stores huge amount of data in the distributed manner and processes the data in parallel on a cluster of nodes. It provides the world’s most reliable storage layer- HDFS. Batch processing engine MapReduce and Resource management layer- YARN.
Hope this Hadoop Tutorial helped you. If you face any difficulty while understanding Hadoop concept, comment below.
This is the right time to start your Hadoop learning with industry experts.
Your 15 seconds will encourage us to work even harder
Please share your happy experience on Google





A very elaborate .informative guide for beginners
Hello Sivan,
Thank you for your feedback. I’m very happy to know that our lesson Hadoop Tutorial for beginners is useful to you.
This Hadoop Tutorial is designed to be simple for its users so that not only the professionals but even beginners can understand the Hadoop concept.
This is a very comprehensive introduction to Hadoop , it covers all the key concepts really well and the tutorial is written in a very easy to understand way without any unnecessary complications which make this a great way to get started with learning Hadoop.
Hii Jacks
Glad you like our Hadoop tutorial and it proves useful to you. We tried to explain each and every term related to Hadoop concepts.
If you seriously want to start your Hadoop learning, then you can mail us your details for live Hadoop lectures
Contact us – [email protected]
Inquiry about Hadoop tutorial.
Hii Praveen, we have much more to share about Hadoop Technology. Whatever you want to know about Hadoop you can contact us with our mail or call. We will definitely help you.
Contact details: [email protected], +91-8451097879
Best wishes from the site.
Great and helpful article on hodoop. One simply need to read this on basics of hadoop. You have explained it very nicely.Thanks for sharing.
Mayur, thank you so much, for your support and kind words. We have more interesting and explained articles for you. You can check the link for more Hadoop articles – https://data-flair.training/blogs/hadoop-features-and-design-principles/
We would like you to share this blog and help others clear their Hadoop Concepts.
thankyou so much, This is very very useful and helpful
and this installation is very clear and having without any mistakes
Hii Manaswini,
Grateful for your words on Hadoop Tutorial. Hope you have read the complete blog and visited on the given links.
Thank you for taking the time to comment on our blog. Keep reading Hadoop. We wish a bright future for you Hadoop Career.
Hi,
Thanks for sharing the great information about Hadoop… Its useful and helpful information…Keep Sharing.
Hii Harman
Thank you so much for giving such a valuable feedback on Hadoop Tutorial. We tried to make you guys happy with our informative Hadoop tutorial. Follow all the links to get deep knowledge of Hadoop Technology.
Please help me How to Find Mean, Median and Mode Using Python?
Hi Poonam,
Thanks for commenting on the Hadoop Tutorial. To find out Mean, Medium and Mode, you can refer our Python Descriptive Statistics tutorial.
Keep Learning…Keep Visting
Regards, Data-Flair
Very informative Hadoop tutorial. There should be more such Hadoop tutorials for beginners as they need basic level hadoop tutorials on what is Hadoop and similar type of questions in simple terms.
Thank you, Kriti, for such a good observation. We appreciate your suggestions for Hadoop Tutorials for beginners.
We have already published more Hadoop articles for beginners and gave you the connected links but it seems you may have missed those.
Don’t worry,
Here is the link for you, you can go through this link. Hope you will get the same experience with this blog
https://data-flair.training/blogs/how-hadoop-works-internally/
If you want us to write on a topic of your choice, you can let us know.
This Hadoop tutorial was really helpful to me. I have question on why is apache hadoop is so popular from the rest of the big data hadoop tools like apache spark. I also want to know more about hadoop training by DataFlair.
Hii Sumeet,
If you’re curious about Hadoop’s enormous popularity, we think the following blogs will be informative to you:
https://data-flair.training/blogs/hadoop-features-and-design-principles/
Yes, we provide Hadoop training. You can contact us for Hadoop online courses, you will get detailed information about the course via mail. Ask your course-related queries here
Contact us- [email protected]
Call: +91-8451097879
The Big Data Hadoop Tutorial Video was very helpful. Thanks for creating such video. Even the blog post on Hadoop tutorial was very nicely explained. It helped understand apache hadoop from core.
Aayush you are amazing, thank you for commenting on our Hadoop Tutorial article and giving us a fabulous review. We have more such video, you can check it on our website. Above given links will also help you to understand Apache Hadoop more easily.
Regards
Data Flair
The Big Data Hadoop Tutorial Video was very helpful. Thanks for creating such video. Even the blog post on Hadoop tutorial was very nicely explained. It helped understand apache hadoop from core.
Thanks, Rinku
Glad to see your appreciation on our effort for Hadoop Tutorial Video. There are more such interesting videos and lectures on Big Data Hadoop which you may like. If you want to learn Hadoop deeply, follow all the links on the page or you can join us for live Hadoop Lectures by sharing your details on our contact.
Contact us- [email protected]
Privileged to read this informative blog on Hadoop tutorial which helped me clearly understand what is hadoop. Commendable efforts to put on research the hadoop. Please enlighten us with regular updates on hadoop.
Glad Avika, you clearly understand Apache Hadoop. This is just the starting of our journey with Hadoop Technology, there is much more to learn about Hadoop.
For new blogs on Hadoop every day, you can subscribe to our site or follow us on different social platforms.
It’s really vy super and excellent
Dorababu thanks a lot for sharing your experience with us. We have already published more super articles about Hadoop Technology especially for readers like you. You must read those Apache Hadoop articles on our site for making a good career in Hadoop Technology.
Best wishes from the site.
Hello dear, i appreciate your amazing work on this post and I am totally impressed. It was great information for me. Thanks for sharing.
Hii paras, You are amazing. Thank you for appreciating us on our Hadoop Tutorial. This all Hadoop information is especially for the loyal readers like you. It seems that you want to explore your career in Hadoop Technology. You can read more Big Data Hadoop blogs on our website. I have something very useful information for you, hope you love to read this:
https://data-flair.training/blogs/hadoop-features-and-design-principles/
Share your experience with us.
It’s very helpful for me, I’ve got a fast beginning with this tutorial and know more about this Hadoop infrastructure.
Lily, I am glad to hear that this Apache Hadoop Tutorial helped you. Thank you so much for your kind review on Hadoop Article. I can see that you have a great enthusiasm for learning Hadoop Technology. For this, we have published a lot of Hadoop content on our website, you can read the blogs. Moreover, we have a better option for you. You can contact us with your details for more Hadoop Learning.
Contact us- [email protected]
Very Good and happy your site provides such good Knowledge base.
Hii Shriprasad,
Thank you for commenting on our Hadoop tutorial. Glad to read that you get a good base on Hadoop. Well if you have the complete basic knowledge you can master any technology. Keep learning with us.
We have provided the latest Hadoop articles, you can check them also.
Thank you for visiting Data Flair.
I felt so happy because of the way you described Hadoop big data and all related technology. thank you I really appreciate it.
Glad Adel, to see such good words for our Hadoop tutorial. Hope you have checked our other blogs also. If not then you must visit.
And if you are interested in making a career in Hadoop then you should go for our Hadoop career article. There you will get a complete description of Hadoop jobs and future scope.
I recommend you to check the blog and give us your valuable feedback again.
https://data-flair.training/blogs/hadoop-career/
Mind blowing stuff ,
i’m beginner for hadoop and i want become zero to hero in hadoop, please provide another valuable information
Hi Yogesh,
It really nice to hear, that you are taking interest in Hadoop. You can refer our LEFT SIDEBAR for more Hadoop Tutorials, else you can explore our course page, we are providing many courses of Hadoop.
You can directly contact us through mail – [email protected] or give a call on: +91-8451097879
Regards,
Data-Flair
Thank you so much for sharing this post. I appreciate your work and it was worth spending time here 🙂 Lot to learn.
Thanks again!
Mandeep, thanks a lot for visiting DataFlair.
Glad to read that you found Hadoop tutorial helpful. We have published many articles that cover all the topics related to Hadoop. Also, we have blogs for Hadoop interview that are very interesting and can help you. You must check them as well. You will get good Hadoop knowledge.
All the very best.
Hello DF Team,
This is really an incredible job that you are doing in helping out by giving a great impetus to many beginners which will keep them going till they get into a Big Data/Hadoop job!!! I am really blessed to go through this tutorial. God bless you team!!!
Thank you much Chinna, for wonderful comment for this Hadoop Tutorial. We are glad our loyal reader like you appreciate and interact with us. We recommend you to share this tutorial with your peer groups and help others.
Regards,
DataFlair
A great article for the beginners and it clearly explains me the Hadoop Ecosystem.Kudos for this one and keep up the good work!
Thanks Prathiban for appreciating us.
Very glad to read that you like our blog. If you want to read more about the Hadoop Ecosystem, you can check the published and also we have an infographic on Ecosystem which will give you a quick guide. You can visit on both through our sidebar.
Keep reading.
Each time I read same articles again I found new concepts. In short, a complete material. Kudos !
Perfect and easy to understand for beginner..
Wonderful content for beginners. A very good guide for very beginners.
Thank you for this content.
Good Article about python and Hadoop concept. I really enjoyed reading it. Thank you.
Very good introduction to Hadoop. Thanks for the writer and DataFlair.
Very good article
Thanks for the appreciation. We are constantly making efforts in providing the latest and informative updates of the big data world. You can explore the collection of 520+ Hadoop Tutorials that will help you in becoming a Big Data expert.
I loved the article, very apt. Good work!
Thanks for the appreciation. You can also explore the amazing collection of 520+ Hadoop Tutorials from – https://data-flair.training/blogs/hadoop-tutorials-home/
Thanks for sharing information on Big data Hadoop. The Tutorial was very nicely explained.
Thanks for the feedback. You can refer to the sidebar for learning more Hadoop concepts.
Thank you for the Great Post on Big Data Hadoop. Your article was very helpful, and it is beneficial to me. It will help me to learn Big Data Hadoop. Keep posting articles on Big Data.