Apache Pig Tutorial – An Introduction guide
This Apache Pig tutorial provides the basic introduction to Apache Pig – high-level tool over MapReduce.
This tutorial helps professionals who are working on Hadoop and would like to perform MapReduce operations using a high-level scripting language instead of developing complex codes in Java.
Apache Pig Introduction
a. History of Apache Pig
As a research project at Yahoo in the year 2006, Apache Pig was developed in order to create and execute MapReduce jobs on large data-sets. In 2007 Apache Pig was open sourced, later in 2008, Apache Pig’s first release came out.
b. Introduction to Apache Pig
Pig was created to simplify the burden of writing complex Java codes to perform MapReduce jobs. Earlier Hadoop developers have to write complex java codes in order to perform data analysis.
Apache Pig provides a high-level language known as Pig Latin which helps Hadoop developers to write data analysis programs. By using various operators provided by Pig Latin language programmers can develop their own functions for reading, writing, and processing data.
In order to perform analysis using Apache Pig, programmers have to write scripts using Pig Latin language to process data stored in Hadoop Distributed File System. Internally, all these scripts are converted to Map and Reduce tasks.
A component known as Pig Engine is present inside Apache Pig in which Pig Latin scripts are taken as input and these scripts gets converted into Map-Reduce jobs.
c. Need for Pig
For all those Programmers who are not so good at Java normally, have to struggle a lot for working with Hadoop, especially when they need to perform any MapReduce tasks. Apache Pig comes up as a helpful tool for all such programmers.
There is no need of developing complex Java codes to perform MapReduce tasks. By simply writing Pig Latin scripts programmers can now easily perform MapReduce tasks without having need of writing complex codes in Java.
Apache Pig reduces the length of codes by using multi-query approach. For example, to perform an operation we need to write 200 lines of code in Java that we can easily perform just by typing less than 10 lines of code in Apache Pig.
Hence, ultimately our almost 16 times development time gets reduced using Apache Pig.
If developers have knowledge of SQL language, then it is very easy to learn Pig Latin language as it is similar to SQL language.
Many built-in operators are provided by Apache Pig to support data operations like filters, joins, ordering, etc. In addition, nested data types like tuples, bags, and maps which are not present in MapReduce are also provided by Pig.
d. Features of Pig
Apache Pig comes with the below unique features:
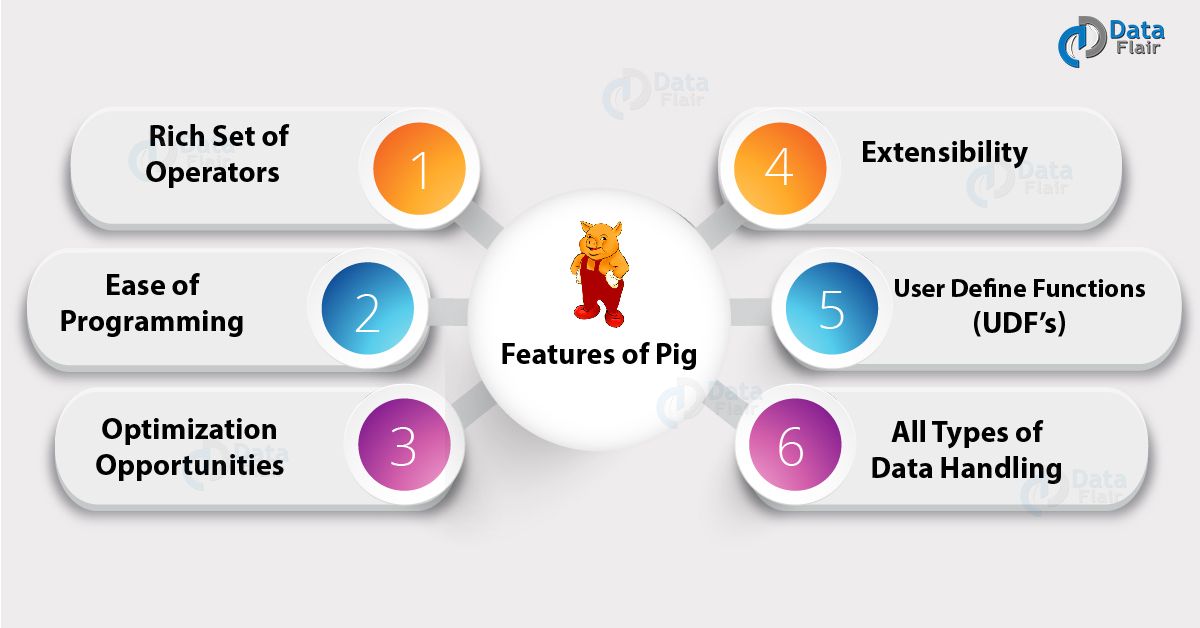
Apache Pig Features
Rich Set of Operators: Pig consists of a collection of rich set of operators in order to perform operations such as join, filer, sort and many more.
Ease of Programming: Pig Latin is similar to SQL and hence it becomes very easy for developers to write a Pig script. If you have knowledge of SQL language, then it is very easy to learn Pig Latin language as it is similar to SQL language.
Optimization opportunities: The execution of the task in Apache Pig gets automatically optimized by the task itself, hence the programmers need to only focus on the semantics of the language.
Extensibility: By using the existing operators, users can easily develop their own functions to read, process, and write data.
User Define Functions (UDF’s): With the help of facility provided by Pig of creating UDF’s, we can easily create User Defined Functions on a number of programming languages such as Java and invoke or embed them in Pig Scripts.
All types of data handling: Analysis of all types of Data (i.e. both structured as well as unstructured) is provided by Apache Pig and the results are stored inside HDFS.
Conclusion
So finally we have seen what is Apache Pig, Pig History, Why Pig is required and the key features of Apache Pig that make it different from other similar technologies.
Did you like our efforts? If Yes, please give DataFlair 5 Stars on Google




