AWS EMR Tutorial – What Can Amazon EMR Perform?
Top AWS Course for AWS Certified Cloud Practitioner (CLF-C01) Start Now!!
In our last section, we talked about Amazon Cloudsearch. Today, in this AWS EMR tutorial, we are going to explore what is Amazon Elastic MapReduce and its benefits.
Moreover, we will discuss what are the open source applications perform by Amazon EMR and what can AWS EMR perform?
So, let’s start Amazon Elastic MapReduce (EMR) Tutorial.
AWS EMR Tutorial – What Can Aamzon EMR Perform?
What is AWS EMR (Elastic Mapreduce)?
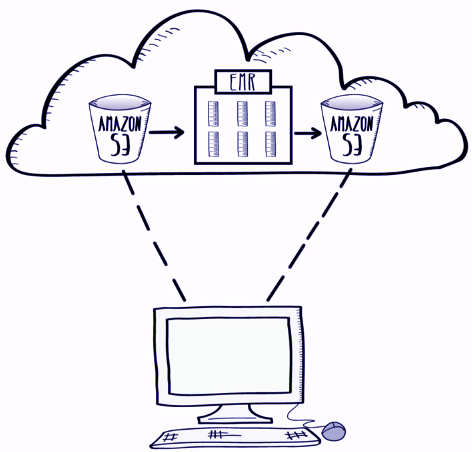
Amazon EMR (Amazon Elastic MapReduce) provides a managed Hadoop framework using the elastic infrastructure of Amazon EC2 and Amazon S3.
It distributes computation of the data over multiple Amazon EC2 instances. AWS EMR is easy to use as the user can start with the easy step which is uploading the data to the S3 bucket. After that, the user can upload the cluster within minutes.
Analysis of the data is easy with Amazon Elastic MapReduce as most of the work is done by EMR and the user can focus on Data analysis. The output can retrieve through the Amazon S3.
Do you know the What is Amazon DynamoDB?
AWS S3 monitors the job and when it gets completed it shuts down the cluster so that the user stops paying. The user can manually turn on the cluster for managing additional queries. The AWS EMR can modify by the user to handle more or less data which benefits large as well as small-scale firms.
Amazon Elastic MapReduce
Data stored in Amazon S3 can access by multiple Amazon EMR clusters. This lead to the fact that the user can spin the many clusters they need. The speed of innovation is increased by this as well as it makes the idea more economical.
The major benefit that each cluster can use for an individual application. There is a bidding option through which the user can name the price they need. AWS EMR automatically synchronizes the security need for the cluster and makes it easy to control access over the information.
Amazon Elastic MapReduce – Open Source Applications
AWS EMR Tutorial – Open Source Applications
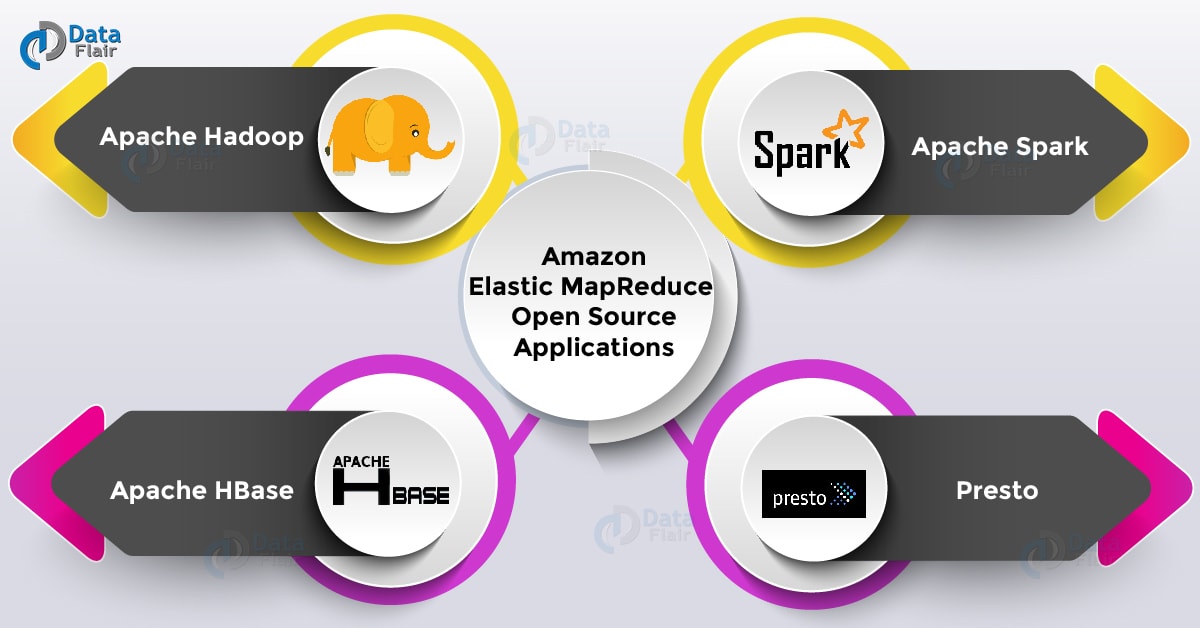
a. Apache Hadoop
Hadoop is used to process large datasets and it is an open source software project. Hadoop diminishes the use of a single large computer. It allows clustering commodity hardware together to analyze massive data sets in parallel.
b. Apache Spark
Apache Spark is used for big data workloads and is an open-source, distributed processing system. It optimizes execution for the fast processing and supports general batch processing streaming analytics, machine learning, and graph databases.
c. Apache HBase
Apache HBase is a large scalable distributed Big Data store which is present in the Hadoop ecosystem. It runs on the top of Amazon S3 or the Hadoop Distributed File System (HDFS). It is loaded with inbuilt access to tables with billions of rows and millions of columns.
d. Presto
Presto helps to process data from various data stores which includes Hadoop Distributed File System (HDFS) and Amazon S3. It is optimized for low-latency, ad-hoc analysis of data.
Benefits of Amazon EMR
Following are the AWS EMR benefits, let’s discuss them one by one:
AWS EMR Tutorial -Benefits of Amazon Elastic MapReduce
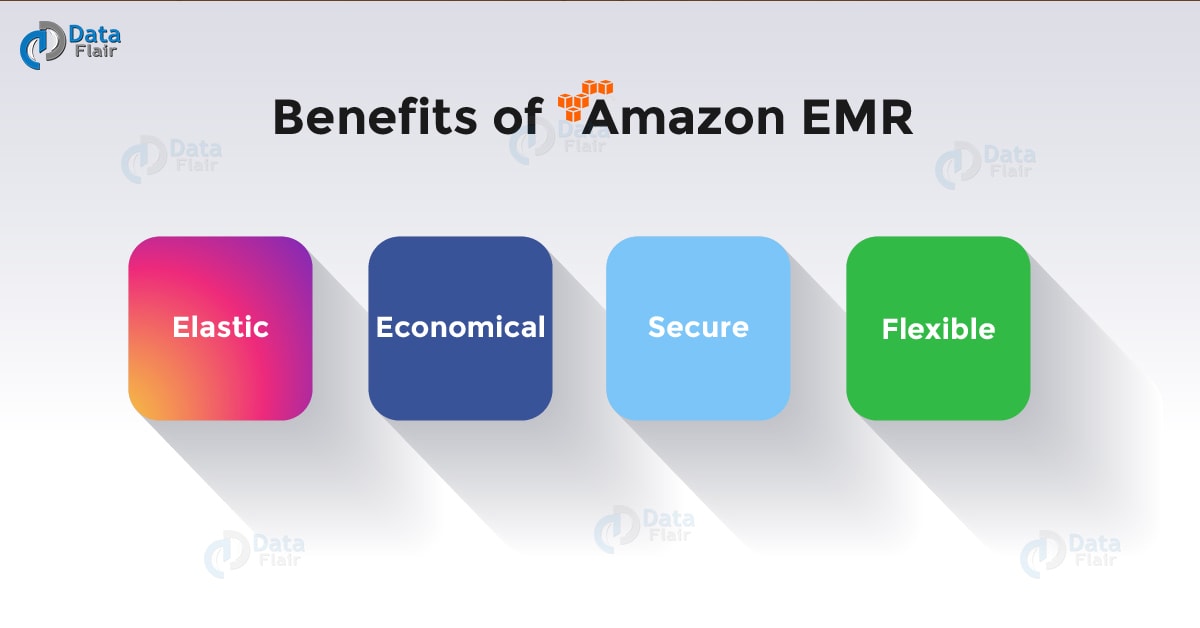
a. Elastic
With the help of Amazon Elastic MapReduce, the user can monitor myriads of compute instances for data processing. Amazon AutoScaling can use to modify the number of instances automatically. Instance modifications can do manually by the user so that the cost may reduce.

AWS EMR – Elastic
b. Economical
AWS EMR is cheap as one can launch 10-node Hadoop cluster for $0.15 per hour. Amazon EMR has a support for Amazon EC2 Spot and Reserved Instances. This helps them to save 50-80% on the cost of the instances.
Economical
c. Secure
AWS EC2 has an inbuilt capability to turn on the firewall for the protection and controlling cloud network access to instances. Clusters can also launch in Virtual Private Cloud a logically isolated network for higher security.
d. Flexible
While using AWS EMR the used=r is flexible for performing tasks such as root access to any instance, Installation of additional applications, and customization of the cluster with bootstrap actions.

AWS EMR – Flexible
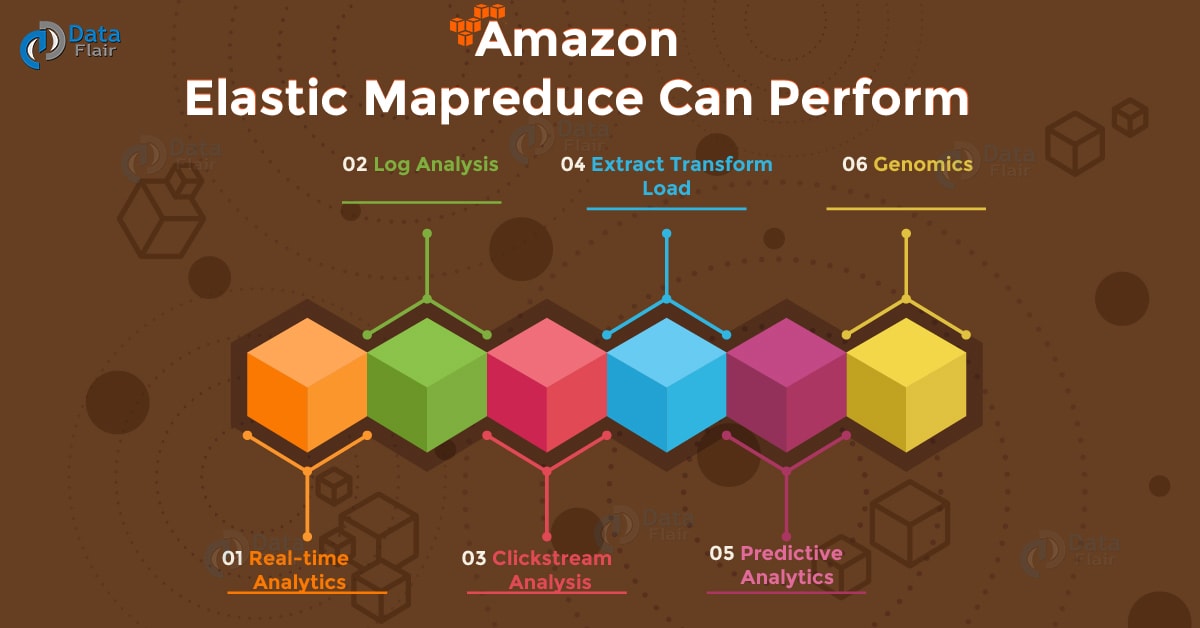
What Can AWS EMR Perform?
These are the activities, which perform by Amazon Elastic MapReduce, let’s explore them:
AWS EMR Tutorial – What Can Amazon EMR Perform?
a. Real-time Analytics
The user can use and process the real-time data. Streaming analytics can perform in a fault tolerant way and the results can be submitted to Amazon S3 or HDFS.
b. Log Analysis
Log processing is easy with AWS EMR and generates by web and mobile application. The unstructured or semi-structured data can also convert into useful insights with the help of Amazon EMR.
Let’s discuss what is Amazon Snowball?
c. Clickstream analysis
To deliver more effective and useful advertisements Amazon Elastic MapReduce can use to analyze Clickstream data.

What Can Amazon Web Services Elastic Mapreduce Perform?
d. Extract Transform Load
AWS EMR often accustoms quickly and cost-effectively perform data transformation workloads (ETL) like – sort, aggregate, and part of – on massive datasets.
e. Predictive Analytics
Apache Spark on AWS EMR includes MLlib for scalable machine learning algorithms otherwise you will use your own libraries. By storing datasets in-memory, Spark will offer nice performance for common machine learning workloads.
f. Genomics
AWS EMR, often accustom method immense amounts of genomic data and alternative giant scientific information sets quickly and expeditiously. Researchers will access genomic data hosted for free of charge on Amazon Web Services.
So, this was all about AWS EMR Tutorial. Hope you like our explanation.
Conclusion
Hence, we studied Amazon EMR provides the tutorial to use different types of programming languages. It supports multiple Hadoop distributions which further integrates with third-party tools. This helps to install additional software and can customize cluster as per the need.
Along with this, we got to know the different activities and benefits of Amazon Elastic Mapreduce. Still, you have a doubt, feel free to share with us.
Your opinion matters
Please write your valuable feedback about DataFlair on Google




