AWS Data Pipeline – 6 Amazing Benefits of Data Pipeline
Top AWS Course for AWS Certified Cloud Practitioner (CLF-C01) Start Now!!
In our last session, we talked about AWS EMR Tutorial. Today, in this AWS Data Pipeline Tutorial, we will be learning what is Amazon Data Pipeline. Along with this will discuss the major benefits of Data Pipeline in Amazon web service.
So, let’s start Amazon Data Pipeline Tutorial.
What is Amazon Data Pipeline?
AWS Data Pipeline is an internet service that helps you dependably process and move data. The data moved is between totally different AWS calculate and storage services. They are on-premises data sources, at mere intervals.
With Amazon Data Pipeline, we will often access your knowledge wherever its hold on, rework and method it at scale, and with efficiency transfer the results to AWS services like Amazon S3, Amazon RDS, Amazon DynamoDB, and Amazon EMR.
AWS data Pipeline helps you simply produce advanced processing workloads that square measure fault tolerant, repeatable, and extremely obtainable. The user should not worry about the availability of the resources, management of inter-task dependencies, and timeout in a particular task.
Amazon Data Pipeline additionally permits you to manoeuvre and method data that was antecedently fast up in on-premises data silos.

AWS Data Pipeline – 6 Amazing Benefits of Data Pipeline
Amazon Data Pipeline manages and streamlines data-driven workflows. This also helps in scheduling data movement and processing. The service targets the customers who want to move data along a defined pipeline of sources, destinations and perform various data-processing activities.
AWS Data Pipeline performs several functions such as:
- Guaranteeing resource convenience.
- Managing inter-task dependencies.
- Retrying transient failures or timeouts in individual tasks.
- Making a failure notification system.
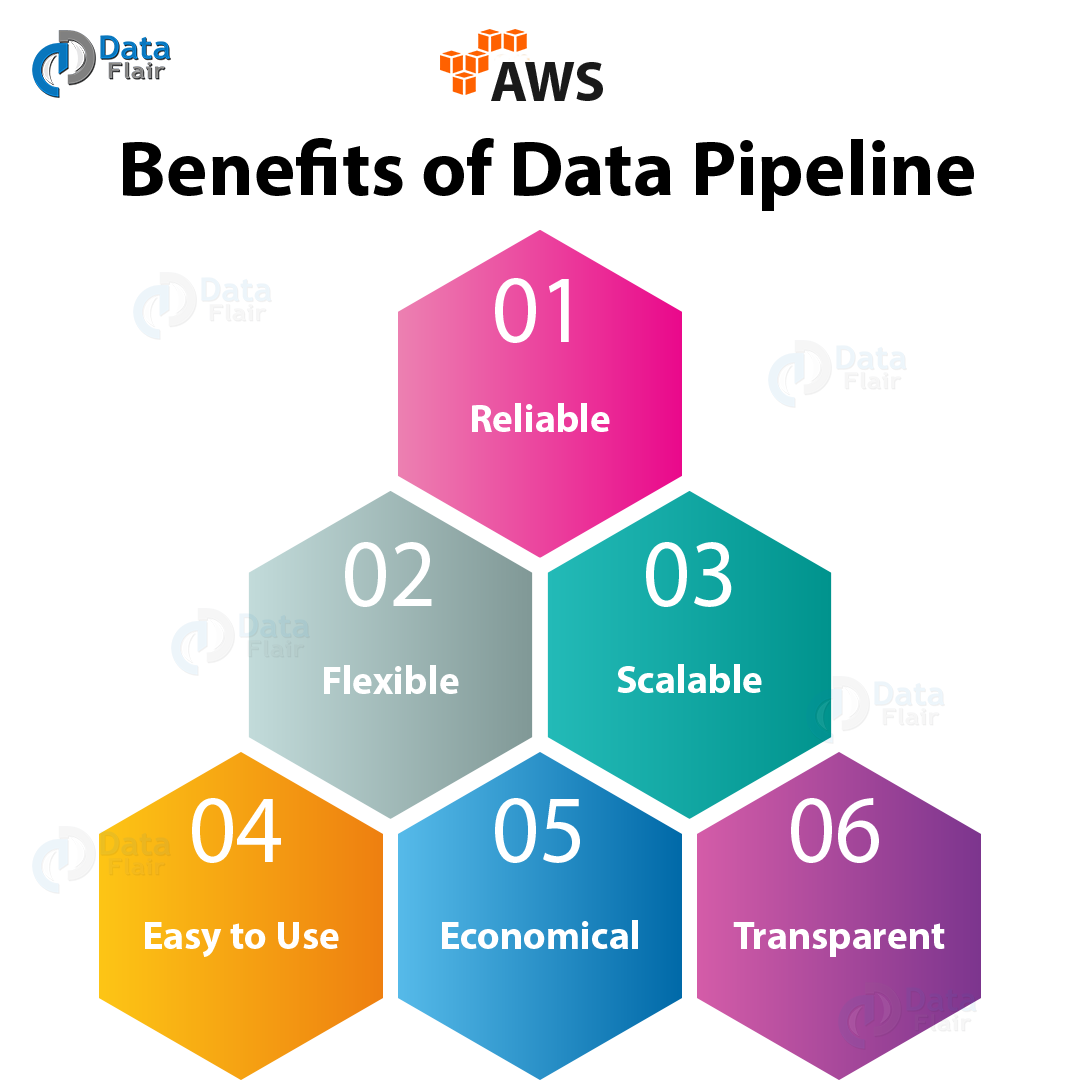
Benefits of AWS Data Pipeline
Following are the benefits of Amazon Data Pipeline, let’s discuss them one by one:
AWS Data Pipeline Tutorial – 6 Amazing Benefits of Data Pipeline
a. Reliable
AWS Data Pipeline is made on a distributed, extremely accessible infrastructure designed for fault tolerant execution of your activities. If failures occur in your activity logic or data sources, Amazon data Pipeline mechanically retries the activity.
If the failure persists, AWS Data Pipeline sends you failure notifications via Amazon Simple Notification Service (Amazon SNS). We will be able to piece your notifications for flourishing runs, delays in planned activities, or failures.
AWS Data Pipeline – 6 Amazing Benefits of Data Pipeline
b. Flexible
AWS Data Pipeline permits you to take advantage of a range of options like planning, dependency pursuit, and error handling. We will be able to use activities and preconditions that AWS provides and/or write your own custom ones.
This implies that you simply will assemble an Amazon data Pipeline to require actions like run Amazon EMR jobs, execute SQL queries directly against databases, or execute custom applications running on Amazon EC2 or in your own datacenter.
This enables you to form powerful custom pipelines to investigate and process your data while not having to wear down the complexities of dependable programming and executing your application logic.

Flexible
c. Scalable
AWS Data Pipeline makes it equally simple to dispatch work to at least one machine or several, in serial or parallel. With Amazon Data Pipeline versatile style, process 1,000,000 files are as simple as process one file.

Scalable
d. Easy to Use
Creating a pipeline is fast and simple via our drag-and-drop console. Common preconditions area unit engineered into the service, thus you don’t have to write any additional logic to use them.
As an example, you’ll be able to check for the existence of associate Amazon S3 file by merely providing the name of the Amazon S3 bucket and also the path of the file that you simply need to check for, and AWS data Pipeline will the remainder.
Additionally to its simple visual pipeline creator, Amazon Data Pipeline provides a library of pipeline templates.
These templates build it easy to form pipelines for the variety of additional advanced use cases, like frequently process your log files, archiving data to Amazon S3, or running periodic SQL queries.
Amazon Data Pipeline – Easy to Use
e. Economical
AWS Data Pipeline is cheap to use and is billed at a low monthly rate. You’ll be able to attempt it without charge beneath the AWS Free Usage.

Economical
f. Transparent
You have full management over the procedure resources that execute your business logic, creating it simple to boost or rectify your logic.
To boot, full execution logs area unit automatically delivered to Amazon S3, providing you with a persistent, elaborated record of what is going on in your pipeline.
Uses of AWS Data Pipeline

Uses of AWS Data Pipeline
a. ETL data to Amazon RedShift
Copy RDS or DynamoDB tables to S3, remodel organization, run analytics using SQL queries and cargo it to RedShift.
b. ETL Unstructured knowledge
Analyze unstructured data like clickstream logs using Hive or Pig on EMR, mix it with structured data from RDS and transfer it to Redshift for simple querying.
c. Load AWS Log knowledge to Amazon Redshift
Load log files like from the AWS asking logs, or AWS CloudTrail, Amazon CloudFront, and Amazon CloudWatch logs, from Amazon S3 to Redshift.
d. Move to Cloud
Easily copy knowledge from the user on-premises knowledge store, sort of a MySQL information, and move it to an AWS data store, like S3 to create it out there to a spread of AWS services like Amazon EMR, Amazon Redshift, and Amazon RDS.
e. Amazon DynamoDB Backup and Recovery
Periodically backup the user dynamo dB table to S3 for disaster recovery functions.
So, this was all about Amazon Data Pipeline Tutorial. Hope you like our explanation.
Conclusion
Hence, we saw AWS Data Pipeline is economical as the prices depend on the region. The price also changes according to the number of preconditions and activities they use each month.
New customers also get the benefit as they get three free low-frequency preconditions and five free low-frequency activities. Amazon Data Pipeline can also get connected to on-premises data sources.
Moreover, a third-party connection is also compatible as Pipeline gets connected to it too. Furthermore, if you have any query, feel free to ask in the comment box.
Did you like our efforts? If Yes, please give DataFlair 5 Stars on Google




