Data Warehousing in SAP HANA – Components, Methods, Working & Benefits
Job-ready Online Courses: Dive into Knowledge. Learn More!
In the last tutorial, we learned about the SAP HANA Information Modeler, now we will understand the concept of data warehousing in SAP HANA. Data warehouses are not new to the world of business intelligence, yet, they are an integral part of SAP HANA’s architecture and conceptual framework.
Before moving on to details of Data Warehousing in SAP HANA, we will learn the basic concept of data warehousing.
What is Data Warehousing?
A simple answer to this is, Data warehousing is a technique or system that collects transformed data from either or both homogenous and heterogeneous data sources and transfers into a single data store. It provides the data to the analytical tools. The data warehouses are known to be the central repositories of a business intelligence system.
Both real-time and historic (pre-existing) data can set the data warehouses collected from either the enterprise’s operational sources or an external data source. As we know, the traditional databases keep transactional data which is one-dimensional data.
And, it cannot be used for analytical and reporting purposes, such databases are called OLTP (Online Transactional Processing) database. But the data warehouses are OLAP type databases which provide processed data for analytical operations like data mining, OLAP analysis, reporting etc.
A data warehouse typically contains metadata, raw data and summary data which is used by analytic tools for reporting, planning, and forecasting.
Next, in the SAP HANA Data Warehousing tutorial, we will discuss the components of Data Warehouse Architecture.
Components of Data Warehouse Architecture
A typical data warehousing architecture in SAP HANA consists of four parts, data sources, staging zone for ETL processing, data types in warehouse and presentation or data access part.
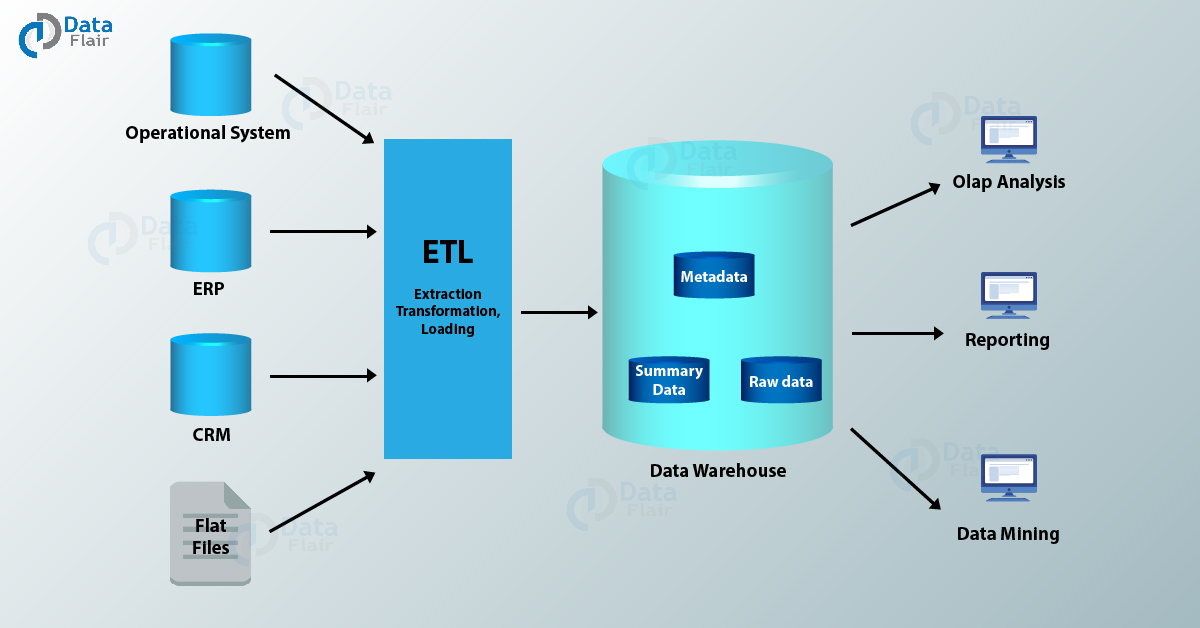
- The data sources consist of the ERP system, CRM systems or financial applications, flat files, operational systems.
- The staging area is where ETL (Extract, Transform and Load) operations performs on the data taken from the various data sources. Data from all kinds of data sources are brought to a single staging area where ETL performs. In ETL, data first extracts from the data source. Then cleans and transforms as per user requirements and loads into the data warehouses so that users can use it for analysis.
- Data warehouses primarily contain metadata, which is, data about data. Whereas, the summary data is the transformed and processes data ready for analysis and reporting.
- Lastly, in the presentation layer, users can perform OLAP operations on the data taken from the data warehouses and use it for data mining, reporting, and analysis. Analytical operations perform on such data to understand the messages in raw transactional data. Understanding the data helps in making informed business decisions.
Now, in SAP HANA Data Warehousing tutorial, we will further move on to Designing Methods in Data Warehousing.
Designing Methods in Data Warehousing
Before using data in analytical tools, users need to design and create data models. It will serve as a blueprint during the execution process. Generally, the user performs three designing methods in Data Warehousing:
- Inmon’s method: It is a top-down approach where the process flow is such that data is taken from the data source, undergoes ETL in the staging area, gets integrated into a normalized (3NF) data model. From here, data loads into the data warehouse. The users create data marts from the data warehouses which creates before them.
- Kimball’s method: On the contrary, Kimball’s method follows the bottom-up approach. The process flow of this model is such that users take data from the operational or third-party data sources, undergoes ETL, then models into a star schema structure. After this, users create data marts in which data that models as schemas get loads. Finally, these data marts integrate to form a single enterprise data warehouse.
- Hybrid method: The hybrid design uses both the techniques together to design the data models. By doing so, a user gets the speed of the bottom-up approach and integration capabilities of the top-down approach.
Moving further in SAP HANA Data Warehousing tutorial, now, we will learn the working of Data Warehousing in SAP HANA.
Working of SAP HANA Data Warehousing
The data warehousing works in a similar fashion in SAP HANA as well. Transactional data from different SAP and non-SAP data sources comes to SAP HANA data warehouse and clients use them as per the data models and logics that the user defines.
SAP HANA has a data warehouse solution known as SAP BW/4HANA. This business warehousing solution runs on a NetWeaver based ABAP platform. It is a model-based solution where a user designs a data warehouse model and data flow on the basis of which data retrieves from the original data source.
Users can create multi-dimensional data models in SAP Business Warehouse. Users mainly use it for OLAP operations.
Benefits of SAP HANA Data Warehousing
Data warehousing solution in SAP HANA has several benefits:
- Instantly access real-time or historical data from SAP or non-SAP data sources. It accesses data to carry out real-time analysis and business insights either on-premise or on-cloud.
- It offers high-volume and real-time data processing.
- Utilize the most of this tool by the virtue of a Big Data warehouse. It allows complete capitalization on your data.
- You can develop the application according to your requirements and use processed data from the data warehouse. Conduct advanced analytics and integrate with machine learning capabilities.
Summary
Data warehouses are efficient analytical data storage systems holding data in multi-dimensional models and schemas making it easy for users to carry out analytical and reporting operations on it. This was all about data warehouse in SAP HANA.
Any queries or feedbacks related to SAP HANA Data Warehousing article? Just enter in the comment section.
We work very hard to provide you quality material
Could you take 15 seconds and share your happy experience on Google




