Master 6 Data Compression Techniques in SAP HANA with Examples
Job-ready Online Courses: Dive into Knowledge. Learn More!
Previously, we learned replication modes in SAP HANA, now, let’s move on to the data compression techniques used in column store in SAP HANA.
Here, you will find information about the basics of data compression in SAP HANA plus the different compression techniques used ranging from basic to advanced level techniques.
Let’s quickly start by introducing the concept.
Data Compression in SAP HANA
Data compression techniques compress the data in column stores in the HANA database. It is a necessary step before storing data in HANA database so that SAP HANA’s performance optimizes.
Data compression enables performance optimization in terms of decreasing operational costs by keeping data efficiently in the main memory, speeding up searches and calculations.
Data compression techniques primarily store data and avoid data redundancy. The compression techniques are automatically optimized and calculated during the delta merge operation. If an empty column is stored in the HANA memory, compression is not applied at that time.
Compression is recalculated and applied along with delta merge operation which is executed whenever data is inserted in that column. To activate the automatic compression, the value of parameter “active” in the optimize_compression section must be YES.
Compression Factor
For applying any type of compression on a data table, we must calculate a compression value first using appropriate factors. Thus, the compression value is calculated using a compression factor.
The compression factor is the ratio of the size of uncompressed data to the size of compressed data in SAP HANA.
We determine the size of uncompressed data as a product of nominal record size and number of records in a table. Whereas, the size of compressed data is the total size of a table residing in the main memory of SAP HANA.
Run the SQL command given below to check the compression properties and apply compression on a loaded table.
LOAD <table_name> SELECT SCHEMA_NAME, TABLE_NAME, COLUMN_NAME, COMPRESSION_TYPE, LOADED from PUBLIC.M_CS_COLUMNS where SCHEMA_NAME = '<your_schema>' and TABLE_NAME = '<your_table>
Compression Techniques in SAP HANA
In this section, we’ll learn about different compression techniques for compressing data in a column store. Typically, data in column stores can undergo a two-fold compression. The first level of compression is a basic type which is Dictionary compression.
Further, on the second level, there are advanced compression methods that we apply to the data compressed by dictionary compression. The methods under advanced compression type are prefix encoding, run-length encoding, cluster encoding, indirect encoding, and sparse encoding.
1. Dictionary Compression
Dictionary compression is a standard compression method to reduce data volume in the main memory. It is a default compression method which compulsorily applies on all columns of a data table in HANA database. In this technique, we map distinct column values to consecutive numbers (value ID).
This optimizes SAP HANA performance as processing numbers are more efficient than character values. We can apply advanced compression technique on data compressed bye dictionary compression method.

- Method type: Default
- Applies to: Main store and delta store
- Applied on: Applied generally
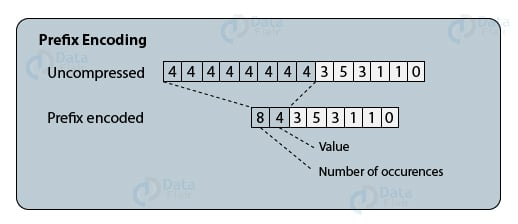
2. Prefix Encoding Compression
In prefix encoding compression, we prefix a numerical value ID by the value representing its number of occurrences. This avoids data redundancy and saves a lot of in-memory space.
Suppose, in a data value array; the value 4 is repeating 8 times consecutively, then, we will add a prefix value 8 before the numeric value 4.
- Method type: PREFIXED
- Applied to: Main store
- Applied on: Single predominant column value
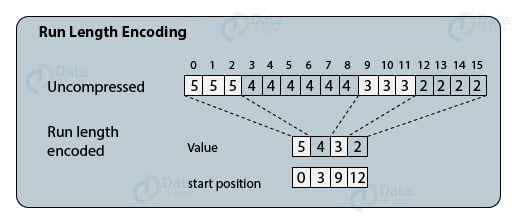
3. Run-length Encoding Compression
In the run-length encoding compression method, only one of the repeating value IDs is stored along with its start position.
Suppose, a data value with value ID 5 appears 3 times consecutively starting from position 0, then, the compression will store only at one instance off value ID 5 and the start position as 0. Thus, it is run-length encoding because it stores the start positions as run-length values.
- Method type: RLE
- Applied to: Main storage
- Applied on: Several frequent column values
4. Cluster Encoding Compression
The cluster encoding compression method cuts a long value ID array into small chunks of 1024 elements. In a piece of an array, if all the value IDs are the same and repeating, then we take only one instance of that value ID. It generates a bit vector value of the cluster encoded value.
Where i=1, if the cluster gets replace by a single value and i=0, if the cluster values are the same as they were in the original uncompressed array.

- Method type: CLUSTERED
- Applied to: Main storage
- Applied on: Several frequent column values
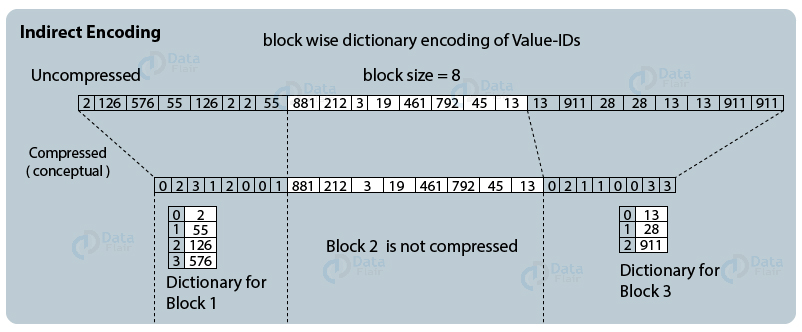
5. Indirect Encoding Compression
We use indirect encoding even after cluster encoding. Only repeating values remain in the compressed array. Thus, in such cases, there are few distinct values and more repeating values which is further compressed into a cluster-specific dictionary unit representing the value IDs in even fewer bits.
This is how indirect encoding compression works where a value ID array compresses down to dictionary blocks.
- Method type: INDIRECT
- Applied to: Main storage
- Applied on: Several frequent column values
6. Sparse Encoding Compression
In sparse encoding compression, we remove the value which repeats most often in a value ID array from the main array. Then bit vector value indicates the position of this value.

- Method type: SPARSE
- Applied to: Main storage
- Applied on: Single predominant column value and not appropriately clustered value ID array.
Summary
This concludes our tutorial of data compression in SAP HANA and different data compression techniques.
We hope the explanation was helpful and you understood every data compression technique. If you have any queries, drop them in the comment section below.
Your 15 seconds will encourage us to work even harder
Please share your happy experience on Google




