SAP HANA Architecture with Components – Learn the Working of SAP HANA
Placement-ready Online Courses: Your Passport to Excellence - Start Now
In the previous tutorial, we learned about features of SAP HANA, now, let’s move on and learn the working of SAP HANA. SAP HANA architecture explains the functioning of the technology completely.
In this tutorial, we will learn about the architectural components and how they work in tandem to make a technology like SAP HANA possible.
SAP HANA is a unique database management technology manifesting in-memory database storage system. SAP HANA is a technology which is a combination of both hardware and software, created specifically for the functioning of the in-memory database management system.
The hardware part consists of a multi-core processor, in-memory storage devices, etc., supported by relevant software. SAP HANA consists of several in-memory servers or engines working in tandem to serve data to client applications.
SAP HANA Architecture
The architecture of SAP HANA has several components working together. The main component of the entire SAP HANA architecture is the Index server which stores and processes all the data. All the other components or engines such as
- Name server
- Relational database engine
- OLAP engine, etc.,
are linked to the index server and work with it. We will learn about all the architectural components and services in detail in this tutorial.
When a user is working on SAP HANA, it is interacting with the client application. A session between the client application and the data source (which is SAP HANA in-memory database) is established which connects the two. The Session and Transaction Manager handle the session initiation and management.
Once, the client is connected with the database, queries and data are launched in languages such as SQL and SQLScript. SQLScript is the scripting language of SAP HANA Database. SAP HANA also supports applications and programs developed in the R language.
Query statements sent by the user processes in the Index Server and a response sends back to the user accordingly. The queries then translate into a readable model and execute by the calculation engine.
Along with the services in the index server, other servers like pre-processor server, name server, graph engine, text engine, statistics server, persistence layer also play important roles in SAP HANA functioning.
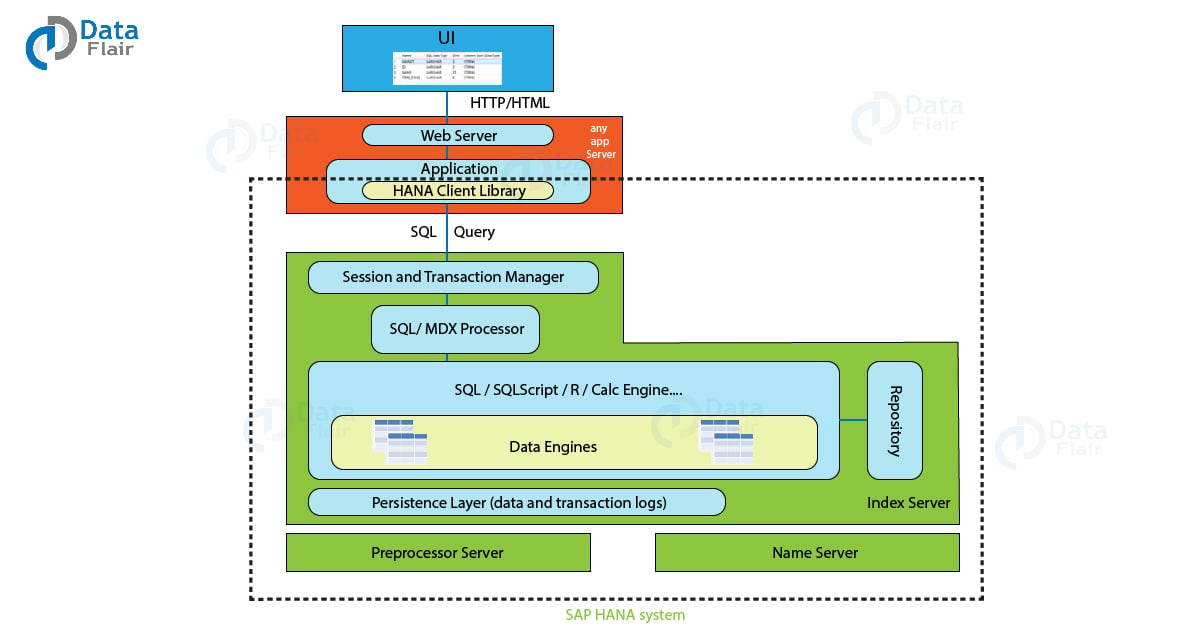
Components of SAP HANA Architecture
Each component in SAP HANA architecture has a unique role to play and a service to provide that contributes to the functioning of SAP HANA. Let us discuss each component of SAP HANA architecture in detail that makes SAP HANA technology one of the best in business analysis.
1. Index Server
The Index Server is the main server of SAP HANA architecture which has the data storage (having the actual data) and processing engine. Queries in different languages like SQL and MDX receives in the index server and process by different components and servers within it.
The transactions and authentications also manage with it. The index server also has a component that manages transaction logs and selectively stores data. All the components of the index server are:
- Relational Data Engine – This engine determines the mechanism of in-memory data storage. The incoming data is either stored in rows or columns. It also manages the relations of data tables between each other.
- Connection and Session Manager – This component checks the user/client authentication and creates a session for an authenticated user. Once a session generates, this component keeps a check of parameters like auto-commit, state of the current transaction, isolation level, etc. Thus, the session generated, and the connection established between the client and the SAP HANA database is managed and monitored by this component.
- Authorization Management – It checks the user privileges and grants users the permission to access that particular services and use resources of SAP HANA.
- Planning Engine – It generates SQL processing plans. The engine generates a plan specific to each request sent to the database, for instance, if user requests for two database objects, then a plan to load the objects into the data engine is created. The planning engine creates plans and manages request execution and filters applied during that. It also manages the different levels of aggregations applied to data. It optimizes performance by planning parallel aggregation processes.
- Calc Engine – This engine creates object specific calculation models and applies it on data to obtain user desired results. Calc engine also maintains the accuracy of data.
- Persistence Layer – The persistence layer maintains the durability and atomicity of the database transaction occurring in and out of it. This server saves the current committed state of transactions and loads the data into the disk every time the system restarts to ensure data durability and security at times of system failure. It also maintains transaction logs of committed or completely undone states.
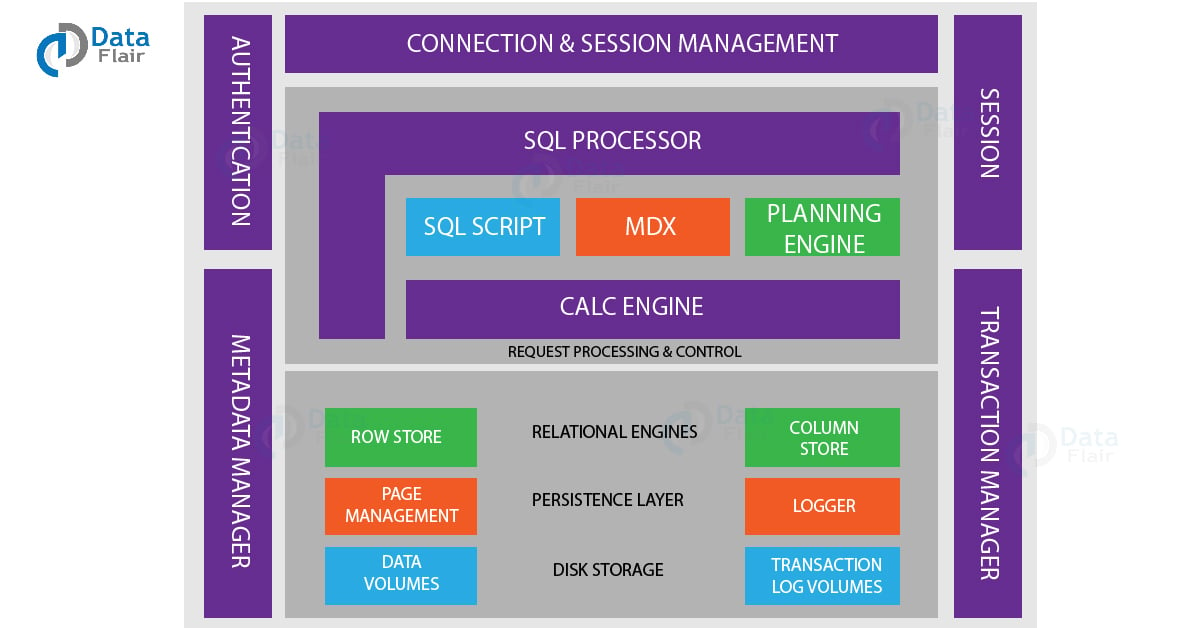
2. Name Server
The name server in SAP HANA architecture maintains the information on the topology or landscape of the SAP HANA system environment. It contains information on the name and location of the components.
This server monitors and manages the topology of all the distributed servers or nodes. It fastens the processing time by decreasing the re-indexing process as it keeps the information on what type of data stores on which server.
3. Pre-processor Server
The pre-processor server in SAP HANA architecture is a text analyzing server which processes textual data. The service provided by this component is used during text search. Whenever a request initiates, this server processes textual data and provides it to the user.
4. Statistical Server
This server checks the performance and health of the overall components of SAP HANA architecture. It collects, stores and analyses the data related to allocation, consumption, and state of system resources. This stored data is for analyzing the system’s performance later.
5. SAP HANA Studio Repository
The repository in SAP HANA Studio stores information related to the newly released updates. You can update the old version to the latest ones with the help of this.
6. XS Engine
XS Engine in SAP HANA architecture facilitates communication between the external applications (Java and HTML based) and SAP HANA system via HTTP/HTTPS in a web browser.
The XS Engine converts the system’s state from the persistence model stored in the database into the consumption model for clients.
Functioning of SAP HANA Architecture
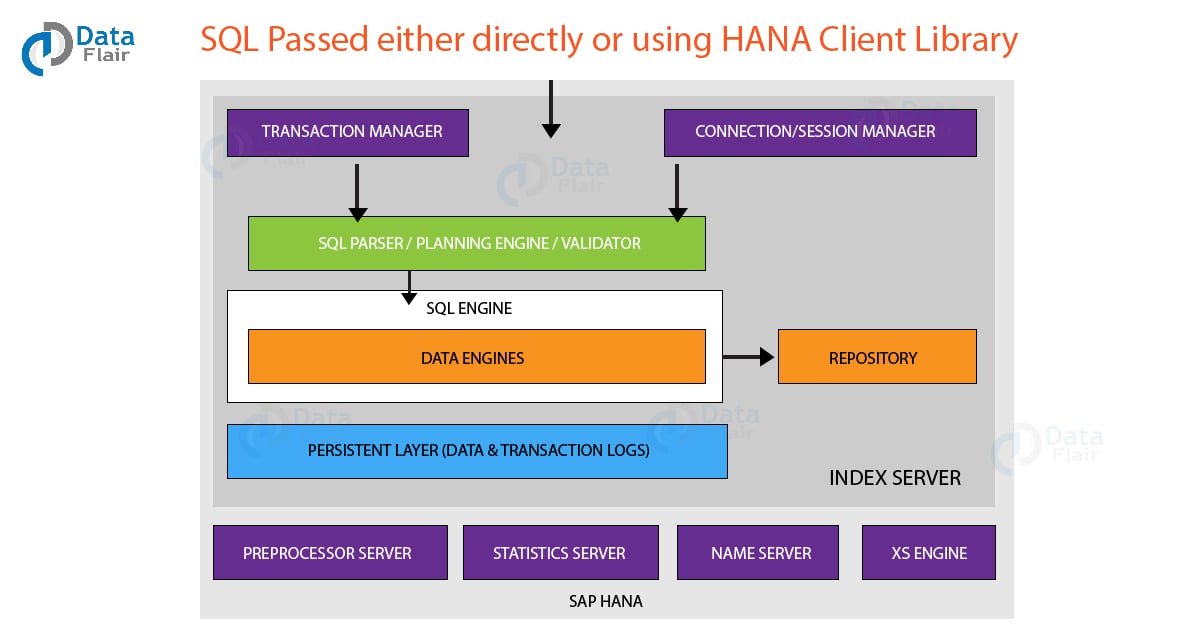
Initially, when a request receives from the client it reaches the HANA distributed environment channel from where it goes to the index server. The index server checks session availability, user authentication and validity of the request. User authorization is kept in check by the authorization manager.
Optimizer and plan-generator parse and optimizes the client request. The SQL Parser reads the query and decomposes into tokens to create a plan for request execution. This part also works in tandem with pre-processor and statistical server.
The query then passes on to the SQL and data engine, which fetches data as per user requirements from the in-memory. The data engine works as per the query plan generated by the planning engine. It is also capable of executing multiple query plans parallelly.
Queries sent in SQL or other supported language translates as calculation models by the corresponding compilers. The translated queries get execute by the calculation engine.
Metadata manager manages SAP HANA metadata such as relational tables, views, columns, indexes, script implementation procedures, etc. The updated data or the changes occurring in delta memory stores in the repository. The results are shown in SAP HANA Studio for the user interface.
SAP HANA Landscape
Landscapes are an important part of SAP HANA Architecture. SAP HANA is an in-memory database technology, which has optimized its performance by improving hardware and software capabilities.
Some important innovations done in SAP HANA software and hardware are:
- Multicore architecture
- 64-bit address space
- Improved performance
- Reduced prices
- Row and column store in the database
- Efficient data compression and partitioning
- No use of aggregates
Row and Column store
The most important aspect of SAP HANA database is the row and column storage formats. These are the ways to store relational data into the SAP HANA database.
i. Row Storage
The row storage method of storing data is similar to how data stores traditionally in disk databases.
The only difference between the SAP HANA row storage and traditional row storage is that in SAP HANA, data stores in rows in the main memory and in traditional databases, data stores in rows in the disk storage.
ii. Column Storage
Column storage is one of the many reasons which make SAP HANA unique. A column storage method stores data in a columnar fashion (linear). It improves SAP HANA’s performance by optimizing both read and write operations on data.
Data stores in the column storage area which divides into two sections; Main Storage and Delta Storage.
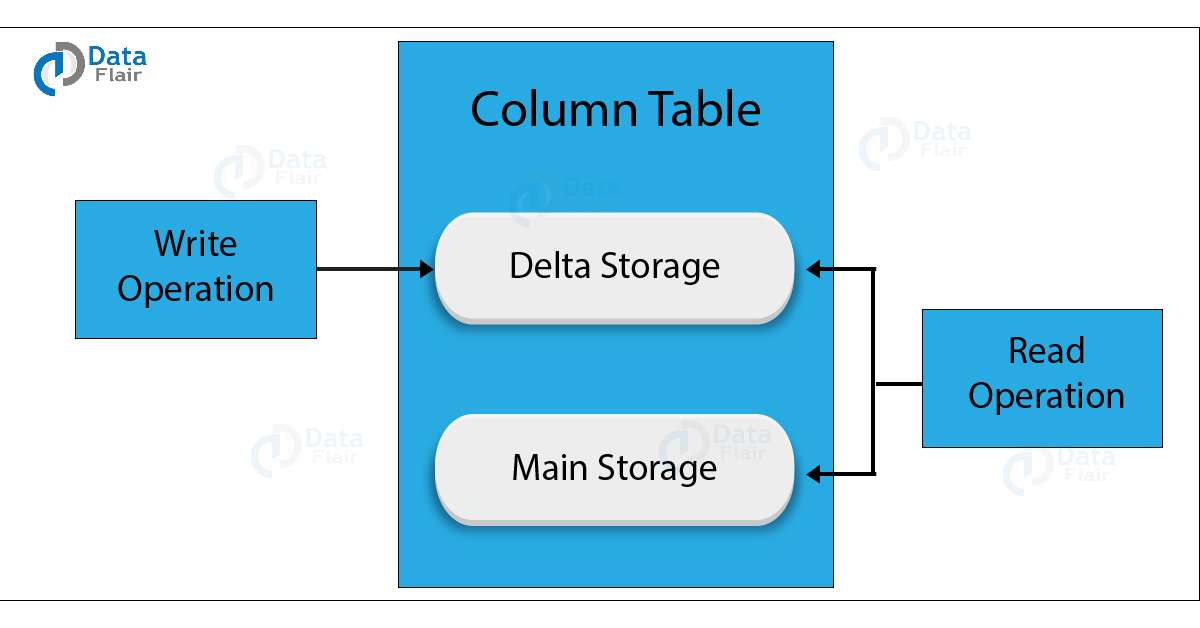 Process of Data Movement from Delta Storage to Main Storage
Process of Data Movement from Delta Storage to Main Storage
1. Main storage is the primary part of the column store which stores compressed data in columnar fashion. The data compresses using any of the several compression techniques such as cluster encoding, sparse encoding, run-length encoding, etc. Main storage is read optimized and we can only read data from here. Delta Store is a separate section to write data into memory. Here, data is present in row store fashion.
2. Initially, when a user writes a query to write data into memory, data goes into L1 Delta buffer store as uncommitted data. Basic compression performs on data in this step.
3. Then data moves to the L2-Delta storage, where it converts in column store and is called committed data.
4. Finally, from the L2-Delta buffer, committed data moves into the main storage area where the compression recalculates, and data stores properly.
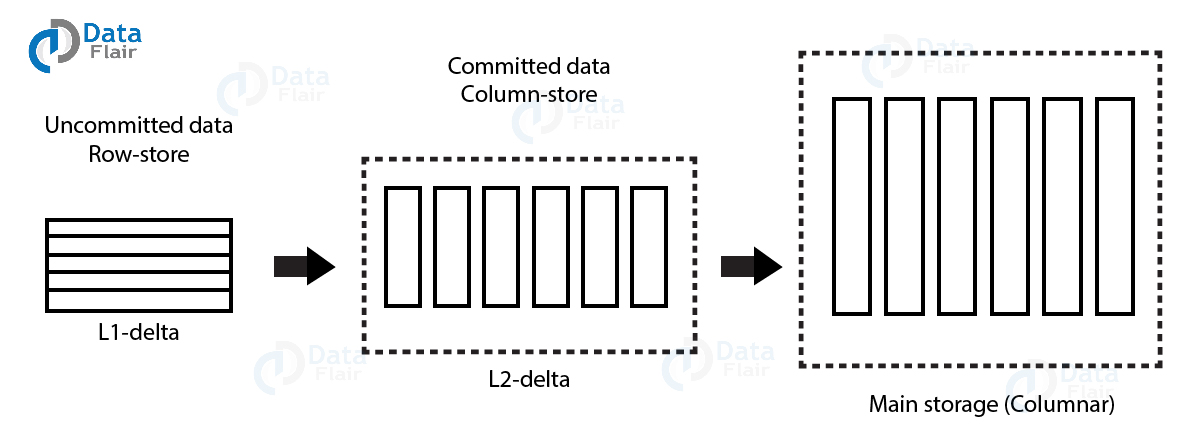
However, we can read data from both delta storage and main storage.
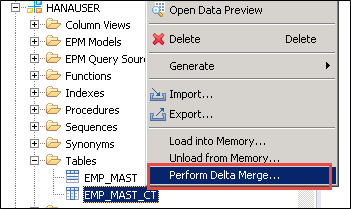
You can move existing data from the Delta store to the Main store by using the “Perform Delta Merge…” option.
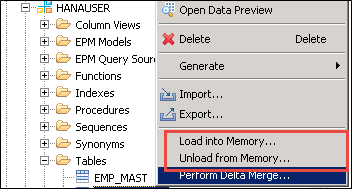
To load or unload data from the main storage, select the options shown below.
Sizing in SAP HANA
Sizing in SAP HANA refers to determining the hardware requirements for a particular SAP HANA installation requirement. The main hardware components are CPU, memory (RAM) and hard disk.
The most crucial task in sizing is to estimate the size of the server best suitable to the business user’s requirements. In SAP HANA, sizing is done by using:
- Quick sizer tool
- DB script
- ABAP report
Any of the three methods for sizing perform three main calculations as given below:
1. Calculating the main memory requirement i.e. doing memory sizing which is done by estimating the size of metadata and transaction data required.
2. Calculating the CPU requirements.
3. Calculating disk space requirements as per the user for data persistence and logging.
Summary
It is all you need to know about the design and working of SAP HANA architecture. A robust architecture like this makes an efficient technology like SAP HANA possible and successful.
If you have any queries related to the Architecture of SAP HANA, enter in the comments below.
You give me 15 seconds I promise you best tutorials
Please share your happy experience on Google





With the help of machine learning also we can find or predict outcome with data.so what is the major difference between SAP HANA, S4 HANA and Machine learning.
Is it possible to deploy some components on private cloud and Web Server on public cloud to offer this as service?