JavaScript Characters – Learn to play with Characters in JS
Full Stack Web Development Courses with Real-time projects Start Now!!
Previously, we learned about JavaScript Data Structures, now, this DataFlair’s tutorial will follow JavaScript characters and all the special characters available for the programmer. These characters may be letters, numbers, symbols, etc. We will study all the categories of characters associated with JavaScript and what their uses are. We will learn different techniques to access and use these characters as per our requirement. The numerous special characters used in regular expressions are as follows:
What are JavaScript Characters?
1. Assertions
These include look-ahead, look-behind, and conditional expressions and indicate that a match is possible in some way. The assertions available in JavaScript are as follows:
| Assertions | Description |
| x(?= y) [Look-ahead] | It matches ‘x’ if and only if (iff) followed by ‘y’. |
| x(?! y) [Negeted Look-ahead] | It matches ‘x’ iff not followed by ‘y’. |
| (?<= y) x [Look-behind] | It matches ‘x’ iff ‘y’ precedes it. |
| (?<! y) x [Negeted Look-behind] | It matches ‘x’ iff ‘y’ doesn’t precede it. |
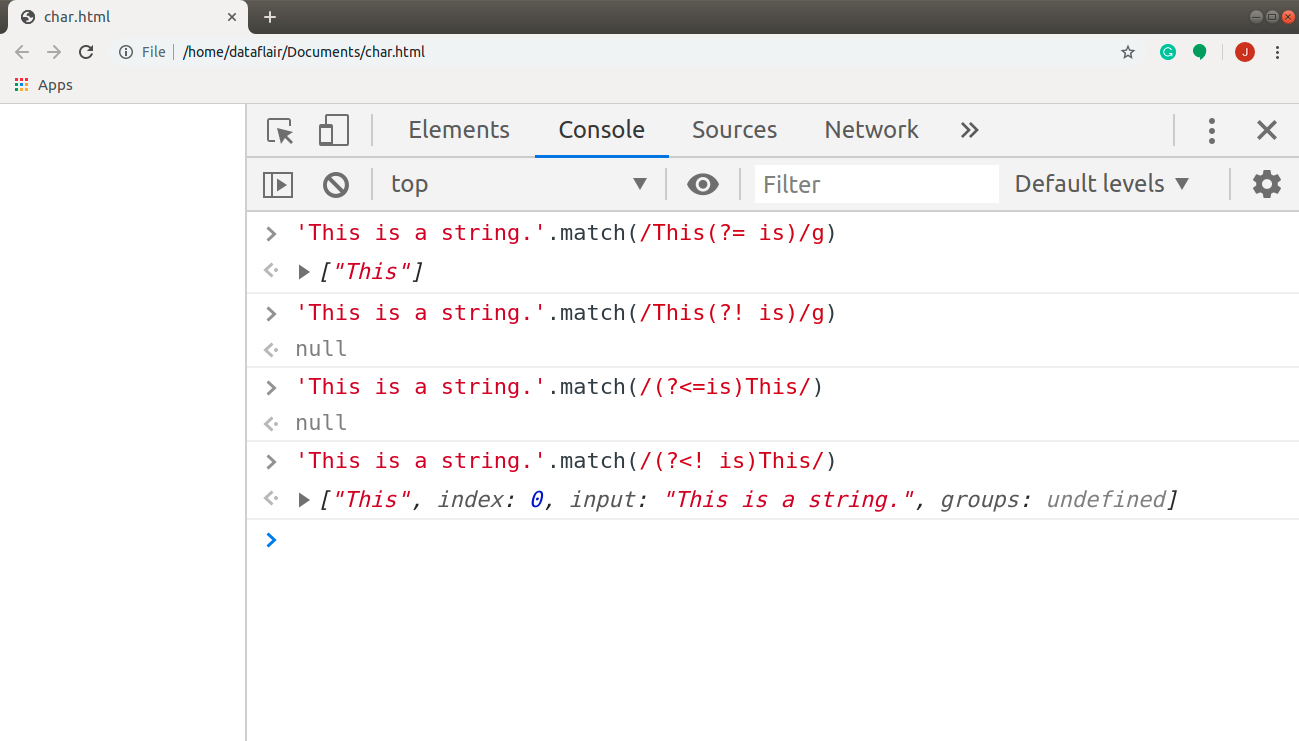
Code:
'This is a string.'.match(/This(?= is)/g) // ["This"] 'This is a string.'.match(/This(?! is)/g) // null 'This is a string.'.match(/(?<=is)This/) // null 'This is a string.'.match(/(?<! is)This/) // ["This", index: 0, input: "This is a string.", groups: undefined]
Output:
2. Boundaries
They include the beginnings and endings of lines and words. The following are the different boundaries in JavaScript:
| Boundaries | Description |
| ^ | It matches the beginning of input. It is case-sensitive, thus /^J/ matches JavaScript but not javascript. It has a different meaning when working with sets (explained further). |
| $ | It matches the end of the input. Thus, /t$/ matches the ‘t’ in javascript, but not in ‘data’. |
| \b | It matches a word boundary i.e. another word character doesn’t follow or precede a word character. The length of a matched word boundary is zero. |
| \B | It matches a non-word boundary i.e. the previous and the next character are of the same type. The beginning and end of the string are non-words. This matches the following cases:
|
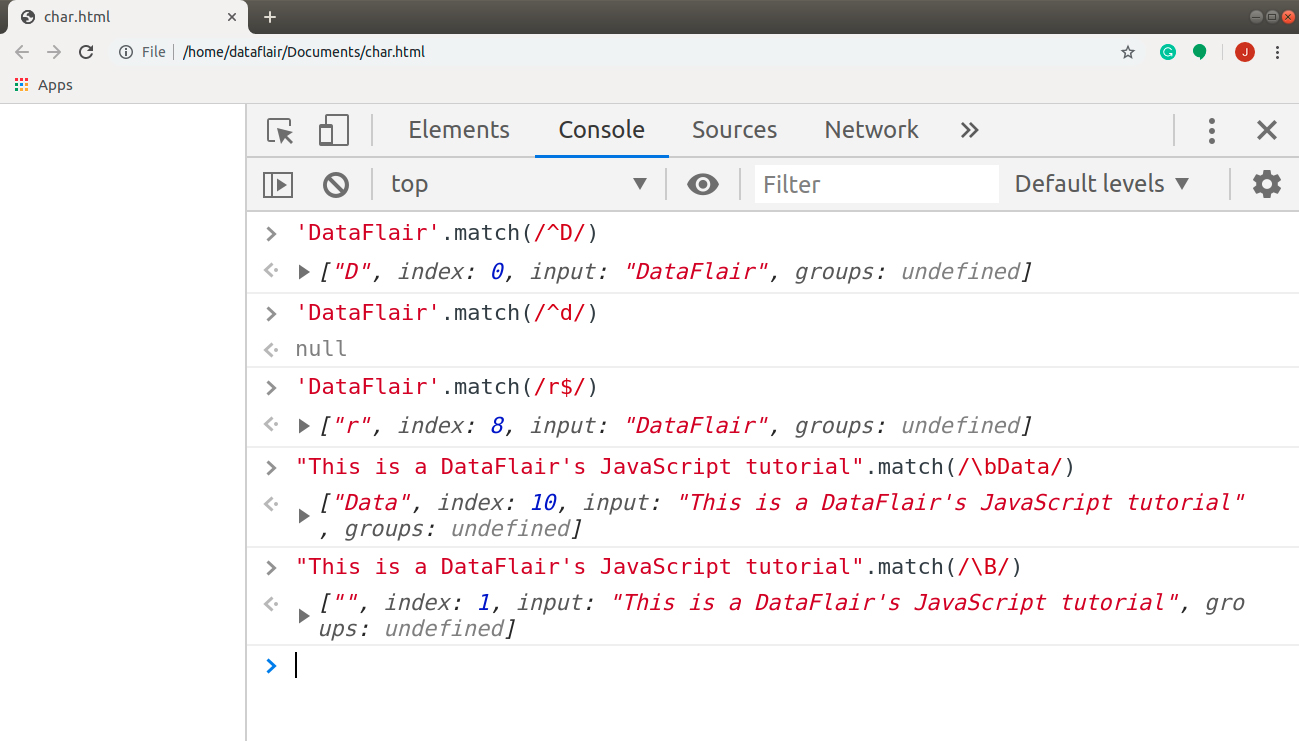
Code:
'DataFlair'.match(/^D/) // ["D", index: 0, input: "DataFlair", groups: undefined] 'DataFlair'.match(/^d/) // null 'DataFlair'.match(/r$/) // ["r", index: 8, input: "DataFlair", groups: undefined] "This is a DataFlair's JavaScript tutorial".match(/\bData/) // ["Data", index: 10, input: "This is a DataFlair's JavaScript tutorial", groups: undefined] "This is a DataFlair's JavaScript tutorial".match(/\B/) // ["", index: 1, input: "This is a DataFlair's JavaScript tutorial", groups: undefined]
Output:
3. Character Classes
These detect different kinds of characters like differentiating between letters and digits. Be sure you’ve gone through our article on JavaScript Strings so that you understand the meaning of every shorthand for escape characters. The most common characters in this category are as follows:
| Character Classes | Description |
| . | It matches any single character excluding the line terminators like \n or \r. The dot matches a literal dot inside a character set. |
| \d | It matches any Arabic numeral, equivalent to [0-9]. |
| \D | It matches any character, not a digit (Arabic numeral), equivalent to [^0-9]. |
| \w | It matches any alphanumeric character from the basic Latin alphabet, including the underscore, equivalent to [A-Za-z0-9_]. |
| \W | It matches any alphanumeric character, not from the basic Latin alphabet, equivalent to [^A-Za-z0-9_]. |
| \s | It matches any whitespace character like space, tab, form feed, etc. It is equivalent to [\f\n\r\t\v\u00a0\u1680\u2000-\u200a\u2028\u2029\u202f\u205f\u3000\ufeff]. |
| \S | It matches any single character other than a whitespace character, equivalent to [^\f\n\r\t\v\u00a0\u1680\u2000-\u200a\u2028\u2029\u202f\u205f\u3000\ufeff]. |
| \t or \u0009 | It matches a horizontal tab. |
| \n or \u000A | It matches a linefeed (newline). |
| \v or \u000B | It matches a vertical tab. |
| \f or \u000C | It matches a form feed. |
| \r or \u000D | It matches a carriage return. |
| [\b] | It matches a backspace. |
| \0 or \u0000 | It matches a NULL character. (Do not follow this character with any other digit). |
| \ | It indicates that the following character is an escape character. It behaves in two ways:
|
4. Sets and Ranges
This category indicates sets (groups) and ranges of expression characters. We search for several characters or character classes inside square brackets […] to search for a given character or a series of characters. The list explaining them is as follows:
| Sets and Ranges | Description |
| x|y | It matches either ‘x’ or ‘y’. |
| [xyz] [a-c] | It is a character set that matches any one of the enclosed characters. |
| [^xyz] [^a-c] | It is a complemented/ negated character set. It matches everything not enclosed in the brackets. |
| (x) (Capturing group) | It matches and remembers ‘x’. |
| (?:x) (Non-capturing group) | It matches but doesn’t remember ‘x’. |
| (?<Name>x) (Named capturing group) | It matches ‘x’, stores it on the group’s property of returned matches and specifies the name by <Name>. The angle brackets < > are essential. |
The brackets we used above have additional functionality: no escaping. Generally, when we want to find the dot literal in our string, we use the escape character \. In square brackets, we can use many characters like dot, plus, parentheses, etc. without escaping.
We will use the above two categories of characters in the next tutorial, so all you need to do for now is understand how these characters work in JavaScript.
Do you know about JavaScript Array?
5. Quantifiers
It indicates the number of characters or expressions to match. The quantifiers provided by JavaScript are listed in the table below:
| Quantifiers | Description |
| x* | It matches ‘x’ occurring 0 or more times. |
| x+ | It matches ‘x’ occurring 1 or more times, equivalent to {1,}. |
| x? | It matches ‘x’ occurring 0 or 1 time, default is greedy quantifier (matching the maximum number of times). If used after any of the quantifiers, it makes them non-greedy (matching the minimum number of times). |
| x{n} | Here, n is a positive integer and matches exactly n occurrences of ‘x’. |
| x{n,} | n is a positive integer here and matches at least n occurrences of ‘x’. |
| x{n,m} | Here, n is 0 or a positive integer and m is a positive integer such that m > n. It matches at least n and at most m occurrences of ‘x’. |
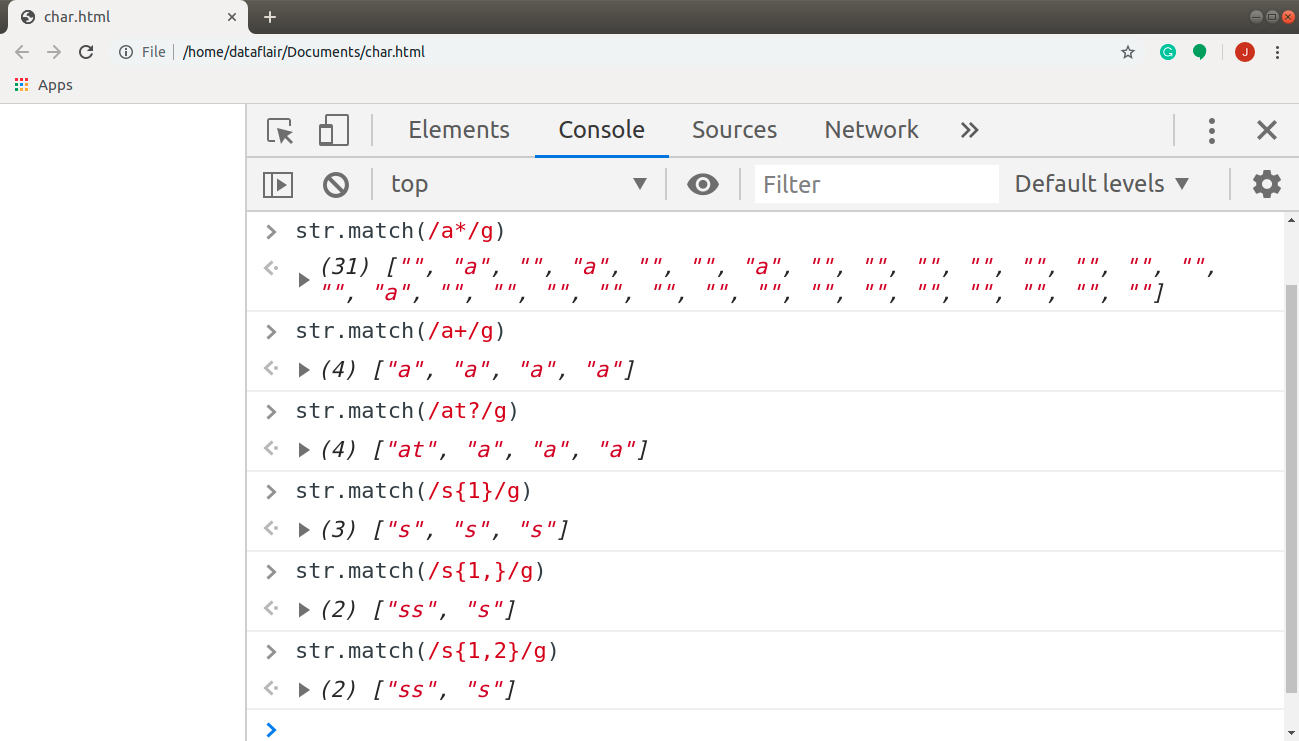
var str = “DataFlair: Regular Expressions”
Code:
str.match(/a*/g)
(31) ["", "a", "", "a", "", "", "a", "", "", "", "", "", "", "", "", "", "a", "", "", "", "", "", "", "", "", "", "", "", "", "", ""]
str.match(/a+/g)
(4) ["a", "a", "a", "a"]
str.match(/at?/g)
(4) ["at", "a", "a", "a"]
str.match(/s{1}/g)
(3) ["s", "s", "s"]
str.match(/s{1,}/g)
(2) ["ss", "s"]
str.match(/s{1,2}/g)
(2) ["ss", "s"]Output:
6. Unicode property escapes
Surrogate Strings
All frequently used characters in JavaScript strings have 2-byte representation. But they only allow 65536 combinations; these are not enough to denote every possible symbol. Thus, rare symbols are encoded with a pair of 2-byte characters for additional combinations. These pairs (4-bytes) are popular by the term “surrogate pairs”. These did not exist at the time of JavaScript creation, thus aren’t always processed correctly by the language.
Some of the Unicode values to compare surrogate strings with normal characters are as follows:
Character | Unicode | Bytes |
A | 0x0041 | 2 |
| = | 0x003D | 2 |
𝒳 (mathematical script X) | 0x1d4b3 | 4 |
| 𝒴 (mathematical script Y) | 0x1d4b4 | 4 |
| 😄 | 0x1f604 | 4 |
7. Flags
There are six flags in JavaScript that affect the search using regular expressions. These are clear in the table below:
| Flags | Description |
| i | This flag indicates that the search should be case-insensitive. This means the character a and A are the same. |
| g | If you set this flag, it means that the script will look for all the matches and return an array. If we skip this modifier, we only get the first match as a result. |
| m | This flag indicates a multiline mode and only affects the behavior of the characters ^ and $. This mode is described in more detail later in the tutorial. |
| s | A dot doesn’t usually match a newline (\n) character. But the dotall mode allows a dot (.) to match newlines. The working of a dot operator is detailed further in the tutorial. |
| u | This flag enables full Unicode support and enables the correct processing of surrogate pairs. |
| y | The sticky flag “y” makes the regular expression search for a match at exactly the specified position and not move any further. |
8. Multiline Mode
The “m” flag enables the multiline mode in JavaScript, which affects the behavior of ^ and $ characters. In this mode, the script not only searches for a match at the beginning or end of the string but also at the start or end of the string.
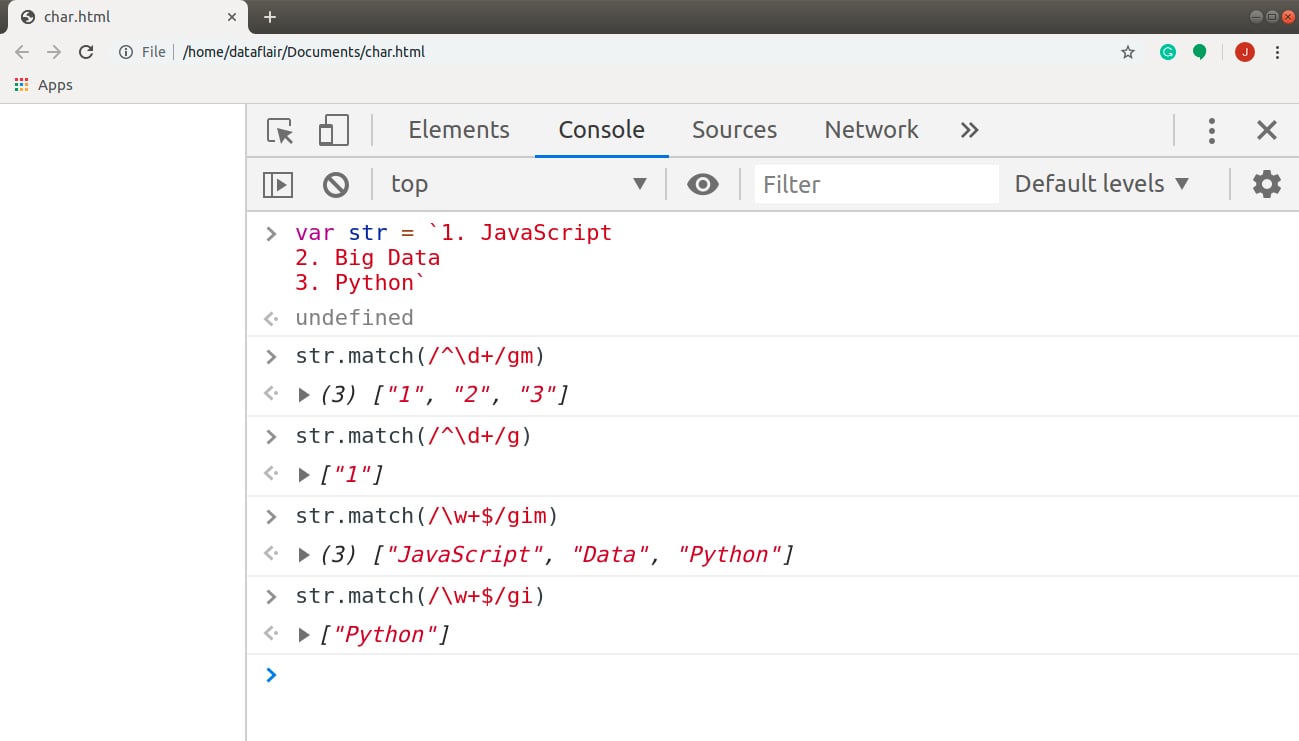
Line start ^: The expression /^\d+/ finds all the digits at the start of each line. See the difference in outputs when multiline mode is set and unset.
Line end $: The expression /^\d+/ finds all the digits at the start of each line. The difference in outputs, when multiline mode is set and unset, is clear in the code below.
Code:
var str = `1. JavaScript 2. Big Data 3. Python` str.match(/^\d+/gm) // (3) ["1", "2", "3"] str.match(/^\d+/g) // ["1"] str.match(/\w+$/gim) // (3) ["JavaScript", "Data", "Python"] str.match(/\w+$/gi) // ["Python"]
Output:
9. The dot character
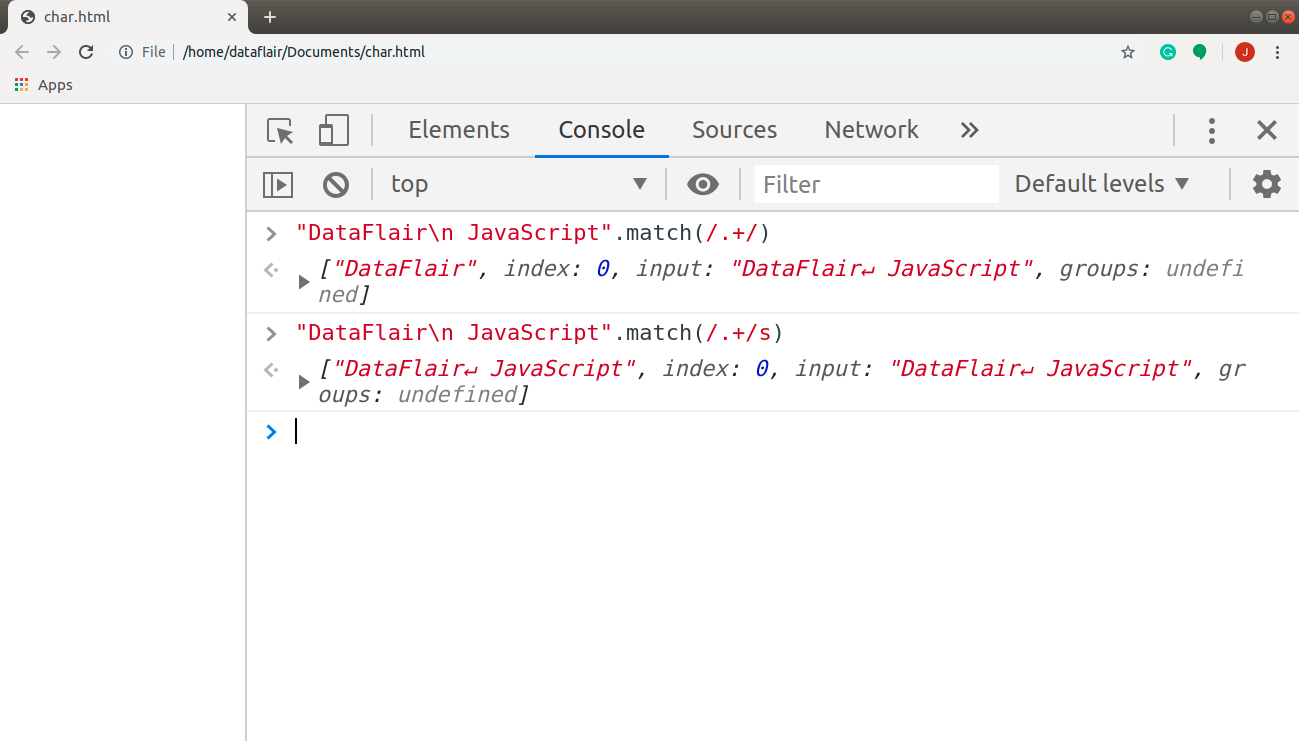
A dot character in JavaScript is a special character class that matches any character, except a newline. This means that the statement “DataFlair”.match(/./); results in DataFlair. What happens when we try to match the string: “DataFlair\n JavaScript”.match(/.+/)? We only get the first word as a match. If we want our program to read the newline too, all we need to do is set the dotall flag “s”. Try the code in the console and see what you get.
"DataFlair\n JavaScript".match(/.+/) // ["DataFlair", index: 0, input: "DataFlair↵ JavaScript", groups: undefined] "DataFlair\n JavaScript".match(/.+/s) // ["DataFlair↵ JavaScript", index: 0, input: "DataFlair↵ JavaScript", groups: undefined]
Output:
Summary
In this JavaScript tutorial, we went through the different characters available to a user or a programmer. These characters are widely used in JavaScript Regular Expressions, explained in the next tutorial. We also learned how we can manipulate the output with the combination of these characters.
You give me 15 seconds I promise you best tutorials
Please share your happy experience on Google




