Storm Kafka Integration With Configurations and Code
Kafka course with real-time projects Start Now!!
In this Kafka Tutorial, we will learn the concept of Storm Kafka Integration. Also, we will discuss Storm architecture, Storm Cluster in this Kafka Storm integration tutorial.
So, in order to make easier for Kafka developers to ingest and publish data streams from Storm topologies, we perform Storm Kafka Integration.
So, let’s begin Kafka Storm Integration tutorial.
What is Storm?
Apache Storm is an open source, distributed, reliable, and fault-tolerant system. There are various use cases of Storm, like real-time analytics, online machine learning, continuous computation, and Extract Transformation Load (ETL) paradigm.
However, for streaming data processing, there are several components that work together, such as:
- Spout
The spout is a source of the stream, which is a continuous stream of log data.
- Bolt
Further, spout passes the data to a component, what we call the bolt. Basically, bolt consumes any number of input streams, does some processing, and possibly emits new streams.
Below diagram describes spout and bolt in the Storm Architecture:
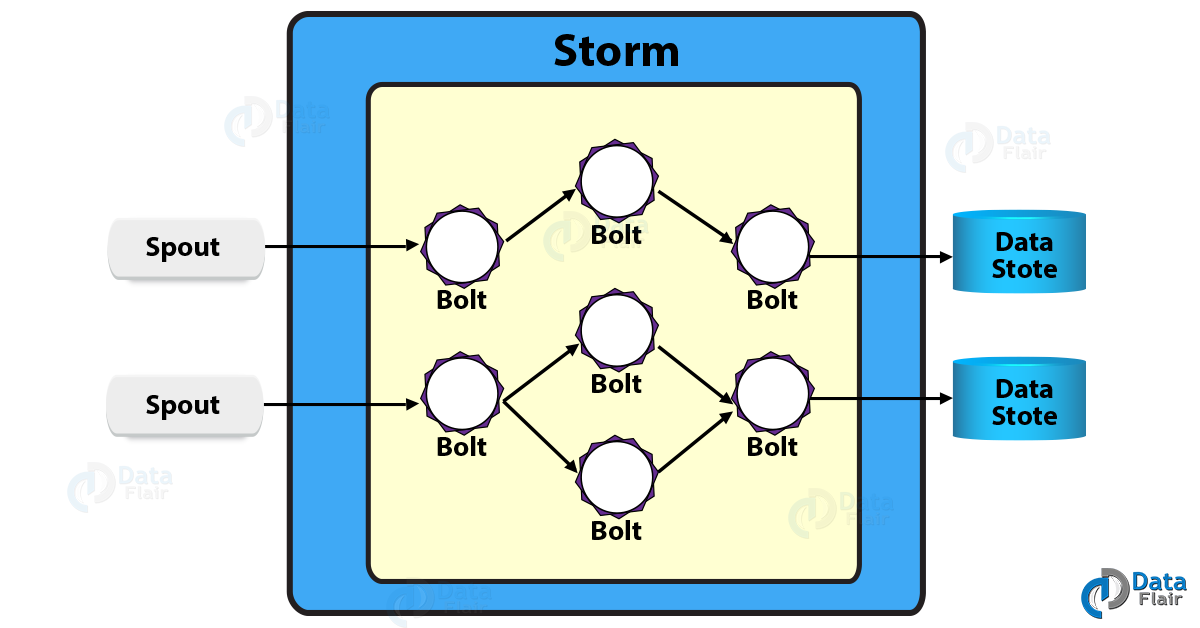
Storm Kafka Integration- Apache Storm Architecture
However, let’s suppose a Storm cluster to be a chain of bolt components. Here, each bolt performs some kind of transformation on the data streamed by the spout.
Moreover, jobs refer to as topologies, in the Storm cluster. Although, these topologies run forever. Afterward, topologies (graphs of computation) are created, for real-time computation on Storm. So, how data will flow from spouts through bolts, topologies will define it.
What is Storm Kafka Integration?
Generally, both Kafka and Storm complement each other. So, we can say their powerful cooperation enables real-time streaming analytics for fast-moving big data.
Hence, in order to make easier for developers to ingest and publish data streams from Storm topologies, we perform Kafka – Storm integration.
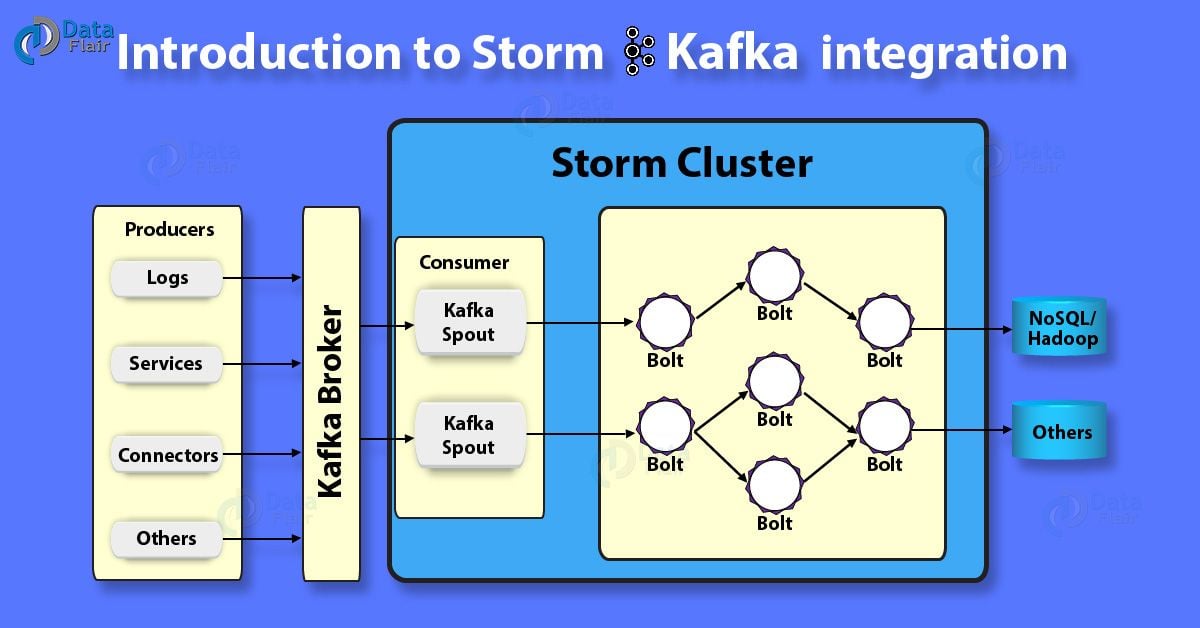
Apache Storm Kafka Integration – Storm Cluster with Kafka Broker
Below diagram describes the high-level integration view of what a Kafka Storm integration working model will look like:
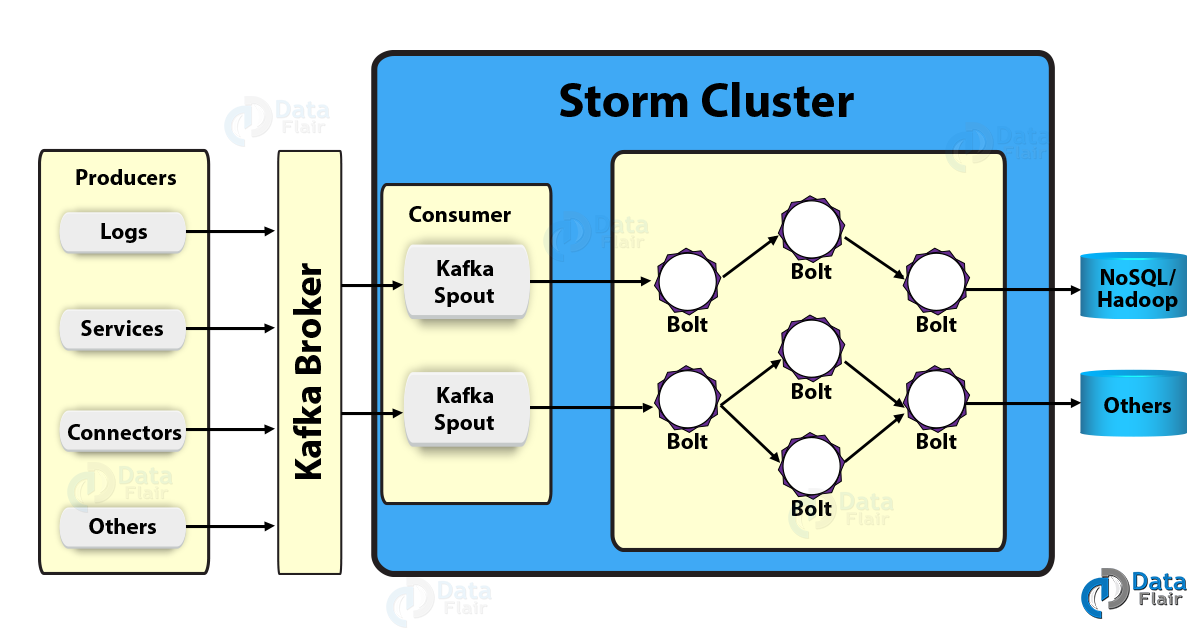
Storm Kafka Integration- The Working model of Kafka Storm
a. Using KafkaSpout
Basically, a regular spout implementation that reads from a Kafka cluster is KafkaSpout. Its basic usage is:
SpoutConfig spoutConfig = new SpoutConfig(
ImmutableList.of("kafkahost1", "kafkahost2"), // list of Kafka brokers
8, // number of partitions per host
"clicks", // topic to read from
"/kafkastorm", // the root path in Zookeeper for the spout to store the consumer offsets
"discovery"); // an id for this consumer for storing the consumer offsets in Zookeeper
KafkaSpout kafkaSpout = new KafkaSpout(spoutConfig);
However, with a static list of brokers and a fixed number of partitions per host, the spout is parameterized.
Also, it stores the state of the offsets its consumed in Zookeeper. Moreover, to store the offsets and an id for this particular spout, the spout is parameterized with the root path. Hence, offsets for partitions will be stored in these paths, where “0”, “1” are ids for the partitions:
{root path}/{id}/0
{root path}/{id}/1
{root path}/{id}/2
{root path}/{id}/3
…Make sure the offsets will be stored in the same Zookeeper cluster that Storm uses, by default. Also, we can override this via our spout config like this:
spoutConfig.zkServers = ImmutableList.of("otherserver.com");
spoutConfig.zkPort = 2191;The ability to force the spout to rewind to a previous offset is shown by the following configuration. We can do forceStartOffsetTime on the spout config, like so:
spoutConfig.forceStartOffsetTime(-2);
That will choose the latest offset written around that timestamp to start consuming. Also, we can force the spout to always start from the latest offset by passing in -1, and we can force it to start from the earliest offset by passing in -2.
i. Parameters for connecting to Kafka Cluster
In addition, KafkaSpout is a regular spout implementation that reads the data from a Kafka cluster. Moreover, in order to connect to the Kafka cluster, it requires the following parameters:
a. List of Kafka brokers
b. The number of partitions per host
c. A topic name used to pull the message.
d. Root path in ZooKeeper, where Spout stores the consumer offset
e. ID for the consumer required for storing the consumer offset in ZooKeeper
Below code sample shows the KafkaSpout class instance initialization with the previous parameters:
Copy
SpoutConfig spoutConfig = new SpoutConfig(
ImmutableList.of("localhost:9092", "localhost:9093"),
2,
" othertopic",
"/kafkastorm",
"consumID");
KafkaSpout kafkaSpout = new KafkaSpout(spoutConfig);Moreover, to store the states of the message offset and segment consumption tracking if it is consumed, the Kafka Spout uses ZooKeeper.
At the root path specified for the ZooKeeper, these offsets are stored. Also, for storing the message offset, Storm uses its own ZooKeeper cluster, by default. However, by setting other ZooKeeper clusters we can use in Spout configuration.
To specify how Spout fetches messages from a Kafka cluster by setting properties, Kafka Spout also offers an option, like buffer sizes and timeouts.
It is very important to note that in order to run Kafka with Storm, it is a requirement to set up both Storm and Kafka clusters and also it should be in running state.
So, this was all about Storm Kafka Integration. Hope you like our explanation.
Conclusion
Hence, In this Storm Kafka integration tutorial, we have seen the concept of Storm Kafka Integration. Here, we discussed a brief introduction to Apache Storm, Storm Architecture, Storm Cluster.
Lastly, we discussed implementation using KafkaSpout. In the next article, we will see Kafka-Spark Integration. Keep visiting at Data Flair. Furthermore, if you have any query, feel free to ask in the comment section.
Your opinion matters
Please write your valuable feedback about DataFlair on Google





Hi, Can you mention the full code for the storm kafka integration