Top Apache Kafka Terminologies and Concepts
Kafka course with real-time projects Start Now!!
Basically, Kafka architecture contains few key terms, like topics, producers, consumers, brokers and many more. To understand Apache Kafka in detail, we must understand these key terms first.
So, in this article, “Kafka Terminologies” we will learn all these Kafka Terminologies which will help us to build the strong foundation of Kafka Knowledge.
So, let’s begin with Apache Kafka Terminology.
Apache Kafka Terminologies and Concepts
List of Kafka Terminologies
Below is the list of most prominent Kafka terminologies which may help you to build the strong foundation of Kafka knowledge. Get yourslef aware with these terminologies and then ready to implement the concept through Kafka Online Training with Industry Experts
i. Kafka Broker
There are one or more servers available in Apache Kafka cluster, basically, these servers (each) are what we call a broker.
ii. Kafka Topics
Basically, Kafka maintains feeds of messages in categories. And, messages are stored as well as published in a category/feed name that is what we call a topic. In addition, all Kafka messages are generally organized into Kafka topics.
iii. Kafka Partitions
In each broker in Kafka, there is some number of partitions. These Kafka partitions in Kafka can be both a leader or a replica of a topic. So, on defining a Leader, it is responsible for all writes and reads to a topic whereas if somehow the leader fails, replica takes over as the new leader.
iv. Kafka Producers
In simple words, the processes which publish messages to Kafka is what we call Producers. In addition, it publishes data on the topics of their choice.
v. Kafka Consumers
The processes that subscribe to topics and process as well as read the feed of published messages, is what we call Consumers.
vi. Offset in Kafka
The position of the consumer in the log and which is retained on a per-consumer basis is what we call Offset. Moreover, we can say it is the only metadata retained on a per-consumer basis.
vii. Kafka Consumer Group
Basically, a consumer abstraction offered by Kafka which generalizes both traditional messaging models of queuing and also publish-subscribe is what we call the consumer group. However, with a consumer group name, Consumers can label themselves.
viii. Kafka Log Anatomy
A log is nothing different but another way to view a partition. Basically, a data source writes messages to the log. Further, one or more consumers read that data from the log at any time they want.
Let’s understand it with a diagram, here consumers A and B are reading a data source which is writing to the log and from the log at different offsets.
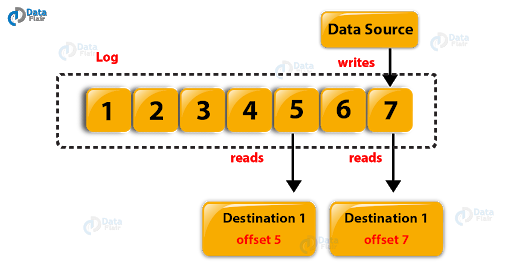
Log Anatomy in Kafka
ix. Kafka Message Ordering and Client Acknowledgments
In Kafka, the order of the messages delivered from a certain partition and messages received by the partition is same.
x. Node in Kafka
In the Apache Kafka cluster, a node is a single computer.
xi. Kafka Cluster
A group of computers which are acting together in order to achieve a common purpose is what we call a cluster. In Kafka also, it has the same meaning i.e. a group of computers, each having one instance of Kafka broker.
xii. Kafka Replicas
Here, the word replica refers to a backup. That means a replica of a partition is a “backup” of a partition. Basically, we use replicas in order to prevent data loss, they never read or write data.
xiii. Kafka Message
In one line, Message in Kafka is an information which travels from the producer to a consumer through Apache Kafka.
xiv. Kafka Leader
A node which is responsible for all reads and writes for the given partition is what we call a Kafka Leader. So, every partition consists of one server, which acts as a leader.
xv. Follower in Kafka
Simply putting, a node that follows leader instructions is what we call a follower. The basic usage of a follower is, if any leader fails, any of these followers will automatically become the new leader. However, it plays as the normal consumer, which pulls messages and also updates its own data store.
xvi. Kafka Data Log
Messages are preserved through Kafka, especially for a considerable amount of time. That means consumers can read as per their convenience.
Since Kafka is configured to keep messages for 24 hours but somehow consumer is down for time greater than 24 hours, in that case, the consumer will lose messages. Still, it is possible to read that message from last known offset, only if the downtime on part of the consumer is just 60 minutes.
xvii. Kafka Connector API
The API which permits to build as well as run reusable consumers or producers that connects existing applications or data systems to Kafka topics, we use the Connector API.
So, this was all about Apache Kafka Terminologies. Hope you like our explanation.
Summary
Hence, this Apache Kafka tutorial sums up most of the important Apache Kafka Terminologies. Moreover, this article says how these terms play an important role in Apache Kafka computations.
Also, helps us to understand Kafka in more depth. Thus, as a result, this blog will help us to learn the concept of Apache Kafka more efficiently.
Furthermore, if you have any query in Kafka Terminologies, feel free to ask through the comment section.
After exploring all these Kafka Terminologies, don’t you think you should master this technology?
We work very hard to provide you quality material
Could you take 15 seconds and share your happy experience on Google





This site is helping me to understand kafka very clearly, in this page, information Text about offset and consumer group is not very clear, could you please update it OR, if there is any diagrammatical representation of all pieces together linking with each other in a message flow from producer to consumer would be great if possible, thank you.
Please write about offset more clearly